by Fazlur Rahman
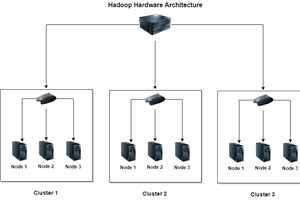
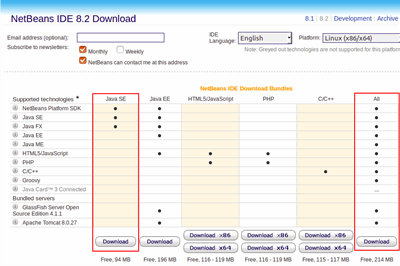
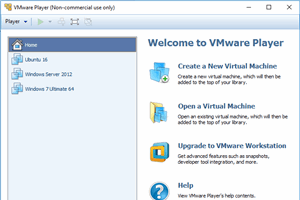
Step by step procedure to install Hadoop 2.7.3 version on Ubuntu 16.04 operating system
by Ryan Scott White
Converts past and real-time stock market tick data into time-sliced summaries called Briefs
by Ilia Reznik, Vladimir Shatalov
Parser for Wikipedia pages from XML dump is presented. Extraction of biographical data and categories with their parents is shown as an example.
by Ilia Reznik, Vladimir Shatalov
How to classify articles on Wikipedia using XML dump