Multicore era – everyone heard about it – Parallel Extensions in Microsoft .NET, Intel TBB, even the new C++ standard includes basic support for threading. Now our small desktop (laptop) computers or small servers posses multicore possibilities – software shall explore these advantages.
Responsibilities of Presented Solution
- Manage pool of data items (order of items might be kept or not)
- Manage pool of empty items – reusing items (useful when these are large buffers)
Features
- Bounded buffer problem solution for multiple producers-consumers pattern. It can also be classified as shared memory asynchronous message passing
- Easy to use solution – all locking machinery hidden inside
- Versions:
- unordered – order in which items are taken does not matter – multiple consumers (one or multiple consumers)
- ordered – order in which items are taken shall be preserved – one consumer (one or multiple producers)
- Puts constraints on memory usage
- Avoids frequent memory allocation and deallocation – more predictable running time (memory allocation time is not predictable)
- Using Parallel Extensions number of running threads can easily and automatically fit into hardware (number of cores)
Data and task parallelism – pipeline processing. Data is divided into blocks, processed in multiple stages in parallel. Each stage can be executed by multiple running threads. The concept is similar to pipelined, superscalar processor architecture (Fig. 1). Arbitrary number of tasks can exist at each stage of processing (Fig. 2).
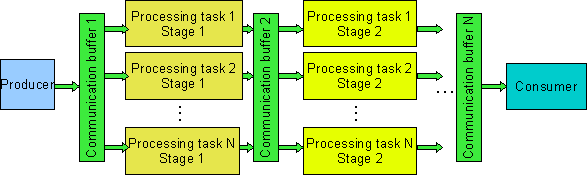
Fig. 1. Sample configuration of processing tasks

Fig. 2. Another configuration of processing tasks
The solution is usable when tasks are time consuming and can be easily parallelized (bag of tasks pattern). It is also usable when data arrives from outside (file, database) and reading is not a processor consuming operation. In such cases, additional threads can perform processing on data blocks already read (when next chunk read is in progress).
Idea
Every item has data and id assigned. Ids shall be unique and sequential (for OrderedItemsPool class). This is some kind of ticket algorithm. The code below presents schematic solution for 3 stage processing (one producer, multiple processing tasks, one consumer).
static void Producer(ItemsPool<t1> bufout)
{
try
{
int i = 0;
while (i < maxNumberOfItems)
{
ItemData<t1> v;
v.Value = bufout.DequeueEmpty();
v.Value = …
v.Id = i;
bufout.EnqueueData(v);
++i;
}
bufout.EnqueueEndOfData(i);
}
catch (Exception e)
{
bufout.SetError("Producer problem", e);
}
}
static void Processing(ItemsPoolsInOut<t1,> bufsInOut)
{
try
{
T2 outData;
ItemData<t1> inData;
while (bufsInOut.DequeueEmptyAndData(out inData, out outData))
{
outData = performSomeProcessing(inData.Value);
bufsInOut.EnqueueDataAndEmpty(outData, inData);
}
}
catch (Exception e)
{
bufsInOut.SetError("Processing problem", e);
}
}
static void Consumer(ItemsPool<t2> bufin)
{
try
{
ItemData<t2> data;
while (bufin.DequeueData(out data))
{
...
bufin.EnqueueEmpty(data.Value);
}
}
catch (Exception e)
{
bufin.SetError("Consumer problem", e);
}
}
static void Main(string[] args)
{
ItemsPool<t1> inputBuffers = new OrderedItemsPool<t1>(inBuffersNumber);
ItemsPool<t2> outputBuffers = new OrderedItemsPool<t2>(outBuffersNumber);
Thread first = new Thread(() => Producer(inputBuffers));
first.Start();
for (int i = 0; i < calcTaskNumber; ++i)
Task.Create((o) =>
{ Processing(new ItemsPoolsInOut<t1,>(inputBuffers, outputBuffers)); });
Thread consumer = new Thread(() => Consumer(outputBuffers));
consumer.Start();
consumer.Join();
if (outputBuffers.IsError)
{
Console.WriteLine(outputBuffers.Error);
}
}
How It Works
Generally heavy locking is used.:) Solution is based on monitors. We have 2 monitors here – first for operations on stack of empty items, second for operations on queue of data items.
When producer thread requires new empty item (DequeueEmpty method) it can be returned from pool of empty items or can be created, but there is a limitation on maximum number of items to be created (memory constraints). Thread has to wait on empty monitor's conditional variable when there are no free empty buffers and no more items can be created. When item is no longer needed, it must be returned to the empty pool (EnqueueEmpty method) or released explicitly (DropEmpty method). Returning or releasing is done by consumer thread whereas dequeuing empty by the producer thread.
When producer has filled empty item with data, it shall be put into data queue (EnqueueData method). On the other end, consumer thread obtains item using DequeueData method. Reading can be blocking when no data exists or when reading is ordered (OrderedItemsPool class) and proper item has not arrived yet. In such cases, thread waits on full monitor's conditional variable.
In case of OrderedItemsPool class, items are stored in priority queue (SortedList class used), for UnorderedItemsPool class ordinary Queue class is used.
Finalizing
When all items have been produced, thread shall mark end of data. This is done using the EnqueueEndOfData method. Information is propagated among all tasks and they can stop processing – DequeueData method returns false when no more items exist to be processed.
EndOfData is a special item with largest id number. After EndOfData was stored, items with larger id cannot be stored (EndOfDataException will appear).
Errors
Work done in multiple threads suffer from error propagating problem. When exception rises in one thread and this thread is part of the processing chain, other threads (tasks) shall be informed. Otherwise deadlock can appear. Therefore exception shall be caught and passed into communication chain using SetError method. After that, ErrorInProcessingException will appear in all tasks processing data as a signal of a problem. The original exception is stored as inner exception.
The main thread can be informed of errors using IsError and Error properties of a pool. The values of the properties shall be obtained from the pool used by the thread that the main thread is waiting for (see code below):
consumer.Join();
if (outputBuffers.IsError)
{
Console.WriteLine(outputBuffers.Error);
}
Deadlocks
When task lives in the middle of processing chain, it is important to first obtain output item and then input item to avoid deadlock. Deadlock can appear when no output item is available (and in the processing chain order shall be preserved – OrderedItemsPool class). Such situation can be easily visible when input pool has more items than output pool. Helper class ItemsPoolsInOut was added as an example solution for such case (DequeueEmptyAndData method).
Moreover ordered items pool (OrderedItemsPool class) shall never appear after unordered items pool (UnorderedItemsPool class) otherwise deadlock can happen.
Problems
- Item not returned to pool (or dropped explicitly) – can lead to deadlock. The problem can be easily solved by resigning from empty pool (and unfortunately memory constraints)
- Heavy locking – .NET monitors are lighter than interprocess mutexes or semaphores, but there is still lot of synchronization – is a more lock free solution available?
- Problem with background (detached) threads when exception occurs
- Processing stopping not implemented
Example
Usage of the presented solution is processing of large file, i.e. encryption and compression. Encryption is realized with RijndaelManaged class whereas compression uses DeflateStream class. Data is read in chunks of 512 KB, processed and written to output file. The second program allows for decompression and decryption of data.
Work is divided into 4 groups: reader (one thread), encryptors (several tasks, several threads), compressors (several tasks, several threads) and writer (one thread). The second program (decompressor, decryptor) looks analogically.
Note that each group of tasks uses different TaskManager object, otherwise it can end in deadlock. Additionally reader and writer are separate threads.
Of course, it might be wiser to put compression (decompression) and encryption (decryption) into one task (no additional buffers and synchronizations) but this is an example just to show possibilities.
Moreover compression using deflate is crap – I know that – it is just an example – if real compression is needed, replace the algorithm. :)
The code uses Microsoft Parallel Extensions Jun08 CTP therefore it is necessary to download and install this library.
Additional note for implementation – DeflateStream class constructor has leaveOpen argument which is absent in CryptoStream class, therefore streams cannot be reused. This seems to be quite inconsistent in design – maybe some Microsoft architect can explain why?
Changelog
- 2009-03-19
SetError method changed - race condition removed (double-check locking pattern used)
- 2009-03-16
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





