
Introduction
The code is capable of searching any "Office document", "*.txt", "*.htm", "*.html" files, etc.
You have an option in the code to specify the file patterns you want to include during indexing. Included is the IndexManager namespace which is the core library of the project. The Search Documents project is basically a demo project which shows you how to use the index manager class. In this example, I have used the IndexManager class to build something like a desktop search, you may use the IndexManager to build an intranet search engine, etc.
We will begin by defining the data structures we would require to store the indexes for documents. We need to understand here that we would require storing a global index which represents a collection of unique words extracted from each of the documents which we intend to search. We define a document class which would represent a document that we would use to store the information about the document such as the location of the document, name of the document and a hashtable "index" which will represent the indexed representation of the text contained in the document.
[Serializable]
public class Document
{
private string _name = string.Empty;
private string _filename = string.Empty;
private string _applicationdirectory = string.Empty;
private string _virtualdirectory = string.Empty;
private Hashtable _index;
public Document(){}
public void SetContent(string sContent){}
public Hashtable Index
{
get { return _index;}
set { _index = value;}
}
public string Name
{
get { return _name; }
set { _name = value; }
}
public string FileName
{
get { return _filename; }
set { _filename = value; }
}
public string ApplicationDirectory
{
set {_applicationdirectory = value;}
get { return _applicationdirectory;}
}
public string VirtualDirectory
{
get { return _virtualdirectory;}
set { _virtualdirectory = value;}
}
}
What follows is the definition of the Documents class which is a collection of documents.
[Serializable]
public class Documents : CollectionBase
{
public void Add(Document document)
{
List.Add(document);
}
public void Remove(Document document)
{
List.Remove(document);
}
public Document this[int index]
{
get { return (Document) List[index];}
set { List[index] = value;}
}
}
We need to parse the documents, extract the words from the documents and build our global word list as well as the indexes for each of the documents.
We will now look at a Word Breaker implementation.
We could use the English_US wordbreaker implementation which is free to use in most of the cases. If not, it can be verified using the GetLicenceToUse call defined within the WordBreaker interface we would create.
For more details on WordBreaker and WordSink interfaces, you can refer to this link.
We begin by looking up the class ids which we would use to define the COM interfaces for the word breaker interface we would develop.
Look for the key WBreakerClass in the path HKey Local Machine\SYSTEM\CurrentControlSet\Control\ContentIndex\Language in the registry. This class id will be used to mark our WordBreaker COM interface.
Also look up the file indexsrv.h in the location "../Program Files\Microsoft Visual Studio .NET 2003\Vc7\PlatformSDK\Include", search for the class id for the IWordBreaker interface. You may use this to mark the interface IWordBreaker.
[ComImport]
[Guid("D53552C8-77E3-101A-B552-08002B33B0E6")]
[InterfaceType(ComInterfaceType.InterfaceIsIUnknown)]
public interface IWordBreaker
{
....
}
There is an excellent article here which can guide you how to implement a WordBreaker for the search engine.
In the present case, we will not use the IWordBreaker and IWordSink interfaces, rather we would use regular expression to achieve somewhat similar results.
Here is a snap shot of the BreakWords method in the WordCollector class:
public void BreakWords(string sString)
{
Regex regEx=new Regex("([ \\t{}():;., \n\r\\s*])");
string [] strArray = regEx.Split(sString.ToLower());
foreach(string str in strArray)
{
if(str == string.Empty) continue;
if(str.Length == 1)
{
bool found = false;
foreach(string c in regexpatterns)
{
if (str == c)
{
found = true;
break;
}
}
if (found) continue;
}
if (fetchunique)
{
if (!arrCombined.Contains(str) && !StopWords.ContainsKey(str))
arrCombined.Add(str);
}
else
if (!StopWords.ContainsKey(str))
arrCombined.Add(str);
}
}
You can improve the above method further by filtering the special characters from the list of words/characters retrieved this way.
Using stopwords, a collection of words we would like to eliminate from indexing as well as search, we will instantiate word collector class like:
public WordCollector(string [] stopwords)
{
if (StopWords == null)
{
StopWords = new Hashtable();
double dummy = 0;
foreach (string word in stopwords)
{
AddWords(StopWords, word, dummy);
}
}
}
We would now write a method called LoadDocument which will call the WordBreaker to break the words from a text and return the result in an ArrayList.
private ArrayList LoadDocument(string sString, ref ArrayList ar, bool uniquewords)
{
WordProcessor.WordCollector wc =
new IndexManager.WordProcessor.WordCollector(stopwordslist);
wc.fetchunique = uniquewords;
wc.BreakWords(sString);
ar = Combine(ar, wc.arrCombined);
return wc.arrCombined;
}
The above implementation of the word splitter is slow when the documents being parsed are huge, in which case the IWordSink can help.
Finally, we are ready to populate the data structures with the indexing information for the documents.
We will maintain a global collection of words in a hashtable which will be used to generate the hashes for each of the documents we process. The hash for each of these documents will be called the "Index".
For any input document, we parse the document to collect the set of unique words and populate a global list of words. After we have processed all the documents, we have a global list of unique words which will be used to calculate the hash for each of the documents.
We go back to each of the documents and compare the word list from each of them to the global list of words to populate a hash table associated with each document.
You will have to be familiar with the concepts of term weighting to completely understand the implementation of the algorithm.
You may refer to this article for the details of implementing a "Building a Vector Space Search Engine".
What you would find in my sample project is an implementation of the "Vector Space Search Engine" in C#.
Once we have indexed the documents, we serialize the documentscollection object and persist it in the local file system. When you issue a search, this persisted object is de-serialized and the Vector operations are performed on the indexes (which are necessarily hash tables).
You would also find the usage of IFilter within this project which is used to filter and parse the text from documents.
You may refer to this article for a detailed understanding and usage of the IFilter.
I have also included a simple implementation of the directory selector. To enhance the performance, it loads only up to depth 1 initially and loads the rest as required. This will be used to select the directory which you want to index and later search in.
The current implementation does not support recursive searching within directories although I have implemented an asynchronous indexing which would prevent the program from choking in case the user inadvertently selects a folder with too many files.
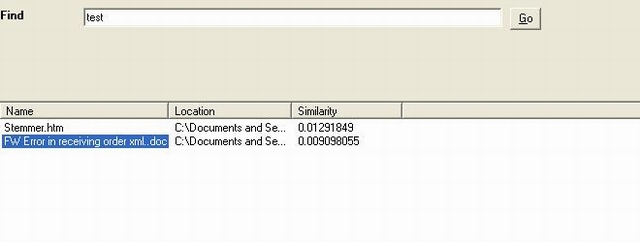
Steps to Use
- From file menu, choose "File->Search In" to specify the folder containing the files to Index and to search. (Sub folders will not be included in indexing.)
- Choose: Tools -> Index, this will index all the files in the folder specified above.
- Finally: we are ready to Search
History
- 14th September, 2006: Initial post
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





