
Record Types in the Practical Type System (PTS)
5.00/5 (2 votes)
This article explains why we need native record types, and how they work in PTS.
Table of Contents
Note
This is part 3 in a series of articles titled How to Design a Practical Type System to Maximize Reliability, Maintainability, and Productivity in Software Development Projects.
It is recommended (but not required for experienced programmers) to read the articles in their order of publication, starting with Part 1: What? Why? How?.
For a quick summary of previous articles you can read Summary of the Practical Type System (PTS) Article Series.
Introduction
Record types are frequently used in all kinds of software development projects.
For example, an ERP application might have record types customer and supplier, with attributes identifier, name, address, etc.
Note
A record is also called structure, struct, or compound data.
A record type is conceptually similar to a table definition in a database.
A record instance is conceptually similar to a row in a database table.
Because records are omnipresent, a practical type system should provide a comprehensive set of features that are easy to use and cover all aspects of working with records.
This article first explains why record types need to be natively supported in a type system. Then you'll see how record types work in PTS — each feature being illustrated by simple source code examples.
Why Do We Need Record Types?
Suppose we need a data structure to store RGB colors.
The structure has a name field of type string, to store the name of the color. Moreover, it has three integer fields: red, green, and blue, to store the RGB values.
To make the data structure more reliable and practical let's add the following conditions:
-
Field
namecan only contain letters and spaces, and its length must be between 3 and 50 characters. -
Fields
red,green, andbluemust contain an integer value between 0 and 255.The default value for each field is 0. For example, if we create an object without specifying a value for
red, its value will be 0. -
Each object must be immutable — after its creation, it's impossible to change the value of a field.
-
To fully comply with the PTS Design Rule, invalid hard-coded color objects should be reported at compile-time.
For example, creating an invalid object with
red=1000results in an error at compile-time (not just at run-time).
Apart from the last condition, this looks like a trivial exercise, and it should be easy to implement this in any programming language, shouldn't it?
How much code would you need to write this in your favorite programming language, and how would the code look like?
Let's first have a look at error-prone solutions in simple type systems, and then see code written in Java, Kotlin, and PTS.
Note
Readers only interested in the PTS code can skip this part.
List
A quick and dirty solution would be to use a list to store an RGB color object. This could be done in pretty much any programming language, since the list type is a well supported, fundamental type.
For example, we could do this (using JavaScript syntax):
red = [ "red", 255, 0, 0 ];
Needless to say, code like this would be extremely error-prone.
Using the first element to store the name, the second one to store the red value, etc., is just a convention that would need to be applied everywhere in the code. There is no protection against accidentally violating this positional convention. Moreover, if the list is mutable (as in most programming languages), there is no protection against adding, removing, or changing elements after the object has been created. Finally, if the structure is changed later on (e.g. field alpha is added because we want to specify the opacity for a color and use an RGBA color model), we'll have to manually update the codebase — with the risk of forgetting to do so, or accidentally leaving out some places.
We won't waste time showcasing all the ugly things that could happen.
Map
A slightly better approach would be to use a map instead of a list.
Here is a JavaScript example:
red = {
"name": "red",
"red": 255,
"green": 0,
"blue": 0
};
Using a map instead of a list improves the code and is less error-prone, because now fields are named. For example, to get the value for green, we can write color["green"] instead of color[2] (indexes start at 0).
However, using a map is still very error-prone, especially if the map is mutable. There is no protection against converting a valid color object into anything else that might eventually be unrecognizable. For example, consider this code:
red = {
"name": "red",
"red": 255,
"green": 0,
"blue": 0
};
console.log("before:" + JSON.stringify(red));
red["name"] = undefined;
red["red"] = "I was a number, but now I'm a string.";
red["read"] = 255; // typo in field name
delete red.green;
delete Object.assign(red, { foo: red.blue }).blue;
console.log("after: " + JSON.stringify(red));
Here is the output:
before:{"name":"red","red":255,"green":0,"blue":0}
after: {"red":"I was a number, but now I'm a string.","read":255,"foo":0}
Moreover, if the data structure is changed later on (e.g. a field is added, renamed, or removed), there are no safeguards in place to ensure that we update any code that accesses or creates these objects. As with lists, all could easily end up in a maintenance nightmare, especially in medium- or large-scale projects.
Note
ECMAScript 2015 (ES6) introduced classes in JavaScript.
Under the hood, however, JavaScript classes are built on prototypes, which essentially means that they are mutable, heterogeneous maps disguised as classes. Therefore, all problems mentioned above also exist for JavaScript classes. For an advanced explanation, read Justen Robertson's article As a JS Developer, ES6 Classes Are What Keep Me Up at Night.
Hence, so-called JavaScript "classes" are very different and less robust than classes/records/structures in C, C++, C#, Go, Java, Python, Rust, and other languages.
Records in Java
Advanced type systems provide record types, also called structures, struct, or compound data.
In Java, we can use a record type and define RGBColor as follows:
public record RGBColor (
String name,
int red,
int green,
int blue ) {
public String toString() {
return name + " (" + red + ", " + green + ", " + blue + ")";
}
}
Note
Record types were introduced in Java 14 (March 2020).
Prior to Java 14, the code for RGBColor looked like this:
public class RGBColor {
private final String name;
public String getName() { return name; }
private final int red;
public int getRed() { return red; }
private final int green;
public int getGreen() { return green; }
private final int blue;
public int getBlue() { return blue; }
public RGBColor ( String name, int red, int green, int blue) {
this.name = name;
this.red = red;
this.green = green;
this.blue = blue;
}
// TODO equals(), hashCode(), toString()
}
Both Java versions are semantically equivalent (they both represent a record with immutable fields), but the new code is obviously easier to read, write, and maintain.
For more information about records in Java you can read Lokesh Gupta's article Java Records.
Using a record type instead of a map is a huge improvement, because now each instance of RGBColor is guaranteed to have the same set of fields during its whole lifetime.
If the record type is changed later on (a field is added, removed, renamed, or its type is changed) then all code that uses the type is auto-checked by the compiler. We are protected from forgetting to refactor code if the record type changes.
Moreover, Java record instances are always immutable, which makes them less error-prone.
However, the cardinality of our type is orders of magnitude higher than it should be. The initially specified conditions for valid RGBColor objects are not fulfilled. We didn't yet apply the PTS Coding Rule. For example, each color value (defined as a 32-bit integer) can store a value in the range -2,147,483,648 to 2,147,483,647, although we specified that values must be in the range 0 .. 255.
Note
We can't use type byte for RGB values, because byte (in Java) is a signed integer in the range -128 .. 127.
We could have used type short (16-bit integer) instead of int (32-bit integer), but Java has no short literals. Hence, we would need to write (short) 10, instead of just 10, which is impractical.
We could have used a single 32-bit integer to store all three 8-bit RGB values, and then use bit manipulation operations to extract the three values, but that wouldn't suit the purpose of this exercise (i.e. how to work with integer ranges).
Moreover, field name lacks constraints, which means that any gibberish (e.g. $%7^) — or even malicious HTML or SQL code not limited in length (e.g. <script>malicious ...</script>) — could be stored in it.
Why should we care about this? Because practice teaches us: The consequences of uncaught invalid data values in software applications are often unanticipated and unpredictable, and they vary largely, from innocuous to huge disasters, depending on the domain.
For example, if RGBColor isn't auto-protected against invalid values then the following message:

... might suddenly be displayed like this:

How's that possible? Why did the message go away?
Well, it actually didn't. Suppose that instead of coding:
RGBColor textColor = new RGBColor ( "red", 255, 0, 0 );
... we accidentally introduce an off-by-one error (256 instead of 255):
RGBColor textColor = new RGBColor ( "red", 256, 0, 0 );
^
If the value for red (256) is later converted to an 8-bit value (by keeping only the right eight bits of the 32-bit value), then the 8-bit value will be 00000000 (eight zeros), because the binary representation of 256 is 100000000 (a 1 followed by eight zeros). As a result, the text color will be black, instead of red. Hence, the text didn't disappear — it just became invisible because of displaying black text on a black background.
Note
One could argue that the same problem of black text on a black background could also occur with a statement like textColor = new RGBColor ( "red", 0, 0, 0 ), which is obviously wrong, but accepted by the compiler which doesn't know anything about colors.
That's true. However, the probability for this problem is orders of magnitude higher if the 32-bit integers aren't checked. All values from 256 to 2,147,483,647 whose eight right bits are zero, as well as all negative values whose eight right bits are zero, would also lead to black text.
Of course, similar problems can also occur with other valid RGB values, all within the 0–255 range (e.g. (1, 1, 1)), because very dark text on a black background is unreadable for humans. But again, the probability is much higher with unchecked integers. Later on we'll see how to totally eliminate the risk of bad text/background color combinations.
A More Reliable Java Record
In order to fulfill all conditions specified at the beginning of this exercise, let's improve our Java record to render it more reliable and practical. We need to protect all record fields against invalid values, and the RGB fields should have a default value of 0.
There are different ways to refactor our previous record example. In the code below, reusable classes are defined to store a color name and its value, and the builder pattern (common in Java) is used to create objects with default values. I'll skip the details, since understanding this code is irrelevant to the topic at hand. Just look at the size of the new code:
public record RGBColor (
ColorName name,
RGBValue red,
RGBValue green,
RGBValue blue ) {
public record ColorName ( String value ) {
private static final Pattern NAME_REGEX = Pattern.compile ( "[a-zA-Z ]{3,100}" );
public ColorName {
Objects.requireNonNull ( value );
if ( !NAME_REGEX.matcher ( value ).matches () ) {
throw new IllegalArgumentException ( "'" + value + "' is invalid. The name must match the regex " + NAME_REGEX + "." );
}
}
public String toString() { return value; }
}
public record RGBValue ( int value ) {
public RGBValue {
if ( value < 0 || value > 255 ) {
throw new IllegalArgumentException ( "'" + value + "' is invalid. The value must be in the range 0 to 255." );
}
}
public String toString() { return String.valueOf ( value ); }
}
public static class Builder {
private ColorName name;
private RGBValue red = new RGBValue ( 0 );
private RGBValue green = new RGBValue ( 0 );
private RGBValue blue = new RGBValue ( 0 );
public Builder() {}
public Builder name ( String name ) {
this.name = new ColorName ( name );
return this;
}
public Builder red ( int red ) {
this.red = new RGBValue ( red );
return this;
}
public Builder green ( int green ) {
this.green = new RGBValue ( green );
return this;
}
public Builder blue ( int blue ) {
this.blue = new RGBValue ( blue );
return this;
}
public RGBColor build() { return new RGBColor ( name, red, green, blue ); }
}
public RGBColor {
Objects.requireNonNull ( name );
Objects.requireNonNull ( red );
Objects.requireNonNull ( green );
Objects.requireNonNull ( blue );
}
public static Builder builder() { return new Builder(); }
public String toString() {
return name.value + " (" + red.value + ", " + green.value + ", " + blue.value + ");";
}
}
If you think that this is a lot of code, difficult to understand (especially for Java newbies), and that nobody wants to write and maintain code like this, then you're not alone! We had to type 196 characters (whitespace included) for our first, non-reliable version, and now our code has mutated into a mess of 1,993 characters. That's about 10 times more characters to read, write, and maintain! What's more, the code would be even larger if we provided more suitable versions of methods equals and hashCode, taking into account only the color values, but not the name (for more information read Java equals() and hashCode() Contracts).
Moreover, now we're in violation of the Don't repeat yourself (DRY) principle. For example, renaming field name would require us to edit code in eight different places, and the compiler wouldn't check if we have consistently replaced all occurrences.
Anyway, on the positive side RGBColor is now more reliable and more practical to use. Color objects can now be created like this:
RGBColor black = RGBColor.builder()
.name("black")
.build();
RGBColor red = RGBColor.builder()
.name("red")
.red(255)
.build();
RGBColor backgroundColor = RGBColor.builder()
.name("yellowgreen")
.red(255)
.green(205)
.blue(50)
.build();
This code is verbose too — but at least it's more reliable. Trying to create a color with invalid values will now result in a run-time error. The risk of displaying a black screen with red=256 has been eliminated — the following run-time error would be displayed:
Exception in thread "main" java.lang.IllegalArgumentException: Invalid value for 'red': 256. The value must be in the range 0 to 255. ...
It's interesting to note that condition 1 of the PTS Design Rule (easy to write code) was fulfilled when we wrote the first Java version of the RGBColor record type, but condition 2 (no invalid values) was violated. Now we have the exact opposite situation: condition 1 is violated, but 2 is fulfilled.
However, this doesn't come as a surprise, because we know that it is generally hard, and sometimes very hard, to write reliable and safe code.
Are we done?
No, not yet!
Instead of getting a run-time error, we'd strongly prefer to get a compile-time error for invalid values.
Besides leading to more reliable code, errors detected at compile-time can also be nicely reported in an IDE, as soon as the bug has been typed. Thus, if we type 256 instead of 255, the illegal value would immediately be displayed as a bug, together with a human-friendly error message, a helpful tip to fix the bug, and (cherry on the cake) a clickable list of possible solutions.
Note
This level of IDE support — an undeniable productivity booster — was demonstrated in section Example of the first article in this series, were an illegal enumerated value was used in Java code.
Here is an image of the bug shown in IntelliJ™ IDEA:

Unfortunately, the bugs we're dealing with in this exercise (an invalid string or an integer literal out of a specified range) can't be reported at compile-time — neither in Java nor in other popular programming languages, as far as I know.
Maybe there are third-party static source code analyzers able to report such bugs — after the tool has been properly configured. But even if such a tool existed, it wouldn't be an ideal solution because it would require installation, proper configuration, and learning how to use it; and it will depend on maintenance by its third party developers to ensure that it's kept up to date with new versions of the programming language. That's not what we want — we want this level of support to just work out of the box.
Note
To support rich source code editing features like auto-completion, go to definition, and bug detection, modern languages often provide implementations of the Language Server Protocol (LSP).
LSP implementations typically use a (possibly LSP-optimized) compiler to detect bugs. Hence only bugs detected at compile-time can be reported in the IDE.
Another intriguing technology on the rise is to detect bugs using AI algorithms integrated in IDEs — a topic too vast to be discussed here.
Kotlin Code
Here is a solution written in Kotlin, a modern JVM language:
data class RGBColor (
val name:ColorName,
val red:RGBValue = RGBValue(0),
val green:RGBValue = RGBValue(0),
val blue:RGBValue = RGBValue(0) ) {
data class ColorName ( val name:String ) {
companion object {
val NAME_REGEX = Regex("[a-zA-Z ]{3,100}")
}
init {
require ( name.matches(NAME_REGEX))
{ "'$name' is invalid. The value must match the regular expression $NAME_REGEX." }
}
override fun toString(): String = name
}
data class RGBValue (val value:Short ) {
init {
require (value in 0..255 )
{ "'$value' is invalid. The value must be in the range 0 .. 255." }
}
override fun toString(): String = value.toString()
}
constructor ( name: String, red: Short = 0, green: Short = 0, blue: Short = 0 ) :
this ( ColorName(name), RGBValue(red), RGBValue(green), RGBValue(blue) )
override fun toString(): String = "$name ($red, $green, $blue)"
}
Note
Kotlin has an unsigned 8-bit integer type (values from 0 to 255) called UByte that luckily fits our specific use case and could have been used instead of a Short value wrapped in RGBValue. But I didn't use UByte in this example, because I want to show a more general solution to constrain integer values to a range (min .. max) — a solution that could also be applied in other cases.
I'm not a Kotlin expert. If there is a better way to write this code, then please leave a comment.
Unlike Java, Kotlin doesn't need a Builder class, because it supports named parameter assignments and default values for record fields (whereas Java doesn't). Moreover, Kotlin types are non-nullable by default, which eliminates the need for null-checks. As a result, the size of the Kotlin code is about 50% of its Java counterpart — a significant improvement. However, the above still looks like "too much code".
Client code looks like this:
val black = RGBColor(name = "black")
val red = RGBColor(name = "red", red = 255)
val backgroundColor = RGBColor (
name = "yellowgreen",
red = 154,
green = 205,
blue = 50 )
Nice!
However, hard-coded invalid values (e.g. red=256) are still only detected at run-time, not at compile-time.
PTS Code
Here's the code written in PTS:
type color_name = string ( pattern = "[a-zA-Z ]{3,50}" )
type color_value = integer ( range = 0 .. 255 )
type RGB_color
att name color_name
atts type:color_value default:0
red
green
blue
.
fn to_string = """{{name}} ({{red}}, {{green}}, {{blue}})"""
.
We'll soon explore the syntax, but this code can be summarized as follows:
-
First we define type
color_name, which is a constrained string that must match the regular expression[a-zA-Z ]{3,50}(only letters and spaces; min. 3 characters, max. 50). -
Then we define type
color_value— an integer in the range0 .. 255. -
These types are then used in type
RGB_color— a record type composed of attributesname,red,green, andblue.
The above code fulfills all conditions specified.
The code size (314 characters) is about 15% of the Java code, and about 30% of the Kotlin code:
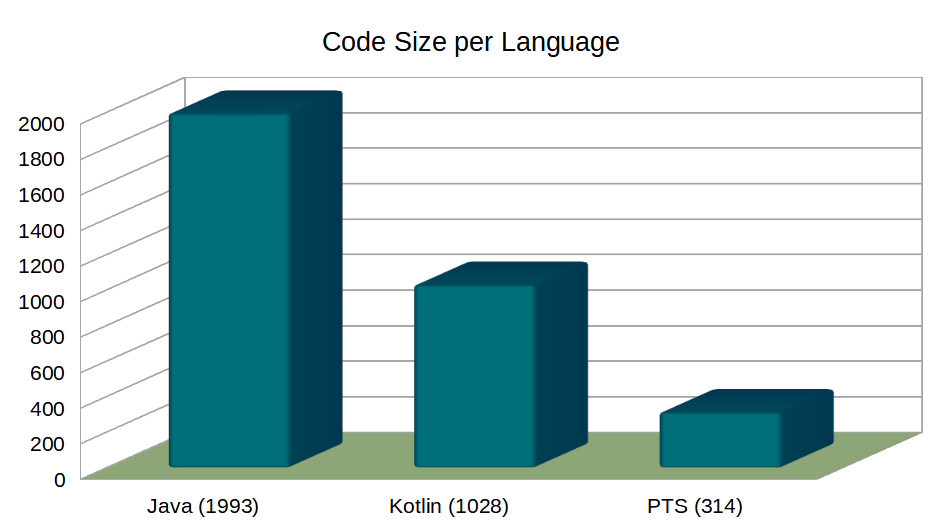
Obviously, these numbers are just suggestive — they can vary largely in other cases. But they are useful to illustrate the potential for improving reliability and maintainability, while keeping code succinct.
Usage of our RGB_color record looks like this:
const black = RGB_color.create ( name = "black" )
const red = RGB_color.create ( name = "red", red = 255 )
const background_color = RGB_color.create (
name = "yellowgreen"
red = 154
green = 205
blue = 50 )
write_line ( black.to_string )
write_line ( red.to_string )
write_line ( background_color.to_string )
Output:
black (0, 0, 0) red (255, 0, 0) yellowgreen (154, 205, 50)
Hard-coded invalid values (e.g. red=256) are detected at compile-time.
Wrapping Up
Quote:If builders built buildings the way programmers wrote programs, then the first woodpecker that came along would destroy civilization.
Writing reliable software is a challenging task in many programming languages, often requiring significant effort and time investment. This difficulty can lead programmers to prioritize development speed and convenience over reliability, resulting in code that is less reliable than it could be — and ought to be. Consequently, many projects are plagued by bugs that creep into production, but could have been easily prevented by means of a better type system.
It is widely known that the costs to find and fix bugs increase exponentially when they are detected late in the development/maintenance cycle. A bug detected in production can be orders of magnitudes more expensive to fix than the same bug found at compile-time.
A type system should therefore simplify the process of writing reliable code, so that developers are more productive and can focus on the logic of their code. This is especially important in large/complex projects and in safety-critical environments, such as software written for space aviation, medical facilities, traffic lights automation, self-driving cars, etc.
How Does It Work?
This section provides an overview of PTS record types — a showcase of features, rather than a comprehensive specification and implementation details.
We'll have a look at numerous, simple code examples to illustrate each feature.
Basic Syntax
A PTS record type is composed of a name and a set of attributes. Each attribute is defined by a set of properties: a unique name, a type, and other optional properties.
Here is a preliminary version of record type RGB_color with four attributes:
record type RGB_color
att name type:string
att red type:integer
att green type:integer
att blue type:integer
.
Note
PTS attributes are called fields or properties in some programming languages.
In the att lines, type: (property name + separator) can be omitted:
record type RGB_color
att name string
att red integer
att green integer
att blue integer
.
Attributes can also be defined within an atts block, in which case the att keyword preceding each attribute can be omitted:
record type RGB_color
atts
name string
red integer
green integer
blue integer
.
.
If several attributes have the same properties (e.g. two attributes are of the same type), then the code can be kept succinct by defining the common properties once, in an atts line:
type RGB_color
att name string
atts type:integer
red
green
blue
.
.
Function to_string
Each PTS type has a method named to_string which returns a string representing a short, human-readable description of an instance/object.
The compiler provides a default implementation for to_string. By default, to_string would return the following string for color green:
[RGB_color [name green][red 0][green 255][blue 0]]
To provide a customized description, we can override the default implementation by explicitly defining function to_string, as follows:
type RGB_color
att name string
atts type:integer
red
green
blue
.
// example output: green (0, 255, 0)
fn to_string = """{{name}} ({{red}}, {{green}}, {{blue}})"""
.
The above function uses string interpolation, which is supported with so-called triple-quoted strings ("""..."""). Attributes (or expressions of any complexity) can be inserted by embedding them in a pair of double curly brackets ({{...}}).
Creating Records
Instances/objects of type RGB_color can be created as follows:
const green RGB_color = RGB_color.create ( name="green" red=0 green=255 blue=0 )
// PTS supports type inference.
// Therefore the type of the constant (RGB_color) can be omitted.
const yellow = RGB_color.create (
name = "yellow"
red = 255
green = 255
blue = 0
)
write_line ( green )
write_line ( yellow )
Output:
green (0, 255, 0) yellow (255, 255, 0)
Named input argument assignments, as used in the above RGB_color.create function calls, are less error-prone and more readable than positional assignments. Therefore, PTS requires named assignments for function calls, except in the following two cases:
-
A function with a single input parameter is called.
The following statements are both allowed:
greet ( message = "Hello" ) greet ( "Hello" )
-
The object reference passed as argument has the same name as the input parameter. Example:
const title = "Info" const message = "All is well." show_info ( title = title, message = message, modal = true ) // Alternative show_info ( title, message, modal = true )
The following code is therefore invalid, because it uses positional assignments:
const red = RGB_color.create ( "red", 255, 0, 0 ) // INVALID!
To understand why this shorter syntax is not supported, let's suppose that later on the order of the color values is changed in the type definition. Instead of red, green, blue, the order is inverted to blue, green, red (for whatever mysterious reason). Then the expression RGB_color.create ( "red", 255, 0, 0 ) would no longer create a red color object — it would incorrectly create a blue color, and there would neither be a compile-time nor a run-time error.
Using color blue instead of red might not be the end of the world. But imagine the following function signature:
fn transfer_money ( amount decimal, to_account string, from_account string )
... and the following statement (which is invalid in PTS since it uses positional assignments):
transfer_money ( 1_000_000.00, "bob_account", "alice_account" )
Note that the above statement doesn't tell us which account is being credited, unless we look at the function definition. Now imagine that later on the function signature is changed to a more intuitive order of input parameters:
fn transfer_money ( amount integer, from_account string, to_account string )
If we forget to adapt the function call, then one million is incorrectly transferred from Bob to Alice, instead of from Alice to Bob.
Bugs like this can't occur when named assignments are used, because the compiler automatically re-arranges the order, based on matching names. Named assignments also clearly tell us which account is credited:
transfer_money (
amount = 1_000_000.00
from_account = "alice_account"
to_account = "bob_account" )
Moreover, named assignments eliminate the problems that can arise in languages where overloaded constructors cannot have the same input parameter types. For example, in Java, developers are sometimes unable to use idiomatic constructors — they are required to use static methods to create objects, or use the Builder pattern, as we did in section A More Reliable Java Record. This problem is exemplified in the Stackoverflow question Constructor overloading same arguments.
Named assignments, paired with default values (explained in the next section) eliminate these problems — improving the code in terms of readability, reliability, and maintainability.
Default Values
The optional property default is used to specify a default value for an attribute.
This enables us to define a default value of zero for attributes red, green, and blue, as required by our initial exercise specification:
type RGB_color
att name string
atts type:integer default:0
red
green
blue
.
.
Instead of writing:
const red = RGB_color.create ( name = "red" red = 255 green = 0 blue = 0 )
... we can now simply write:
const red = RGB_color.create ( name = "red" red = 255 )
If a default value is defined, it can be retrieved programmatically at run-time. For example, to get the default value for attribute red we can code:
const default_red = RGB_color.atts.red.default
write_line ( """Default value for red: {{default_red}}""" )
// Same in one line:
write_line ( """Default value for red: {{RGB_color.atts.red.default}}""" )
Output:
Default value for red: 0
The ability to get the default value programmatically at run-time is useful in various situations. For example, in a GUI application, we can pre-fill a text input field with the default value specified in the type.
Data Validation
In PTS, data validation is a critical aspect, because it enables us to adhere to the PTS Coding Rule (introduced in the first part of this PTS article series, titled What, Why, and How?):
Quote:All data types in a software project should have the lowest possible cardinality.
— PTS coding rule
Ultimately, rigorous data validation results in more robust, reliable and secure code, and reduces the time spent to find and fix bugs.
The following sections show how data validation for records can be applied to individual attributes, as well as to the record as a whole.
Attributes Validation
There are two ways to validate an attribute:
- Add a constraint to the type of the attribute
Example:
type RGB_color att name string ( pattern: "[a-zA-Z ]{3,50}" ) atts type:integer ( range: 0 .. 255 ) default:0 red green blue . .Here we declare attribute
nameto be of typestring— but we added the constraint that the value must match the regular expression[a-zA-Z ]{3,50}, as required by our initial specification.Moreover we constrain the three color values to be in the range
0 .. 255.Note
Constrained types will be fully covered in a subsequent PTS article.
- Use an explicitly defined constrained type
This option should be used if the same constrained type is used elsewhere in the code (to honor the DRY principle). In the code below we first create new, reusable types, called
color_nameandcolor_value. These types are then used in typeRGB_color.type color_name = string ( pattern: "[a-zA-Z ]{3,50}" ) type color_value = integer ( range: 0 .. 255 ) type RGB_color att name color_name atts type:color_value default:0 red green blue . .
Function check
Before looking at different ways to define attribute validation rules, it is helpful to first understand how validation works under the hood.
Note
Readers not interested in implementation details can skip this section.
The functions shown in this section are simplified examples, just to illustrate how PTS data validation could be implemented.
Consider the following statement, which defines type color_name — a string constrained to match the regular expression [a-zA-Z ]{3,50}:
type color_name = string ( pattern: "[a-zA-Z ]{3,50}" )
Each time a constrained type is declared, the compiler implicitly creates a function named check for the constrained type. This function takes a value as input, and returns null if the value is valid, or else an object of type invalid_value_error (a type defined in the standard library of a PTS implementation). In case of an invalid value, the error object returned by the function contains additional information (error message, identifier, etc.) that can be explored by client code — for instance to display an error message to the user.
Here is an example of function check, specifically created by the compiler for the above declaration of type color_name that uses a pattern property:
fn check ( value string ) -> invalid_value_error or null
const pattern = pattern.create ( "[a-zA-Z ]{3,50}" )
if value.matches_pattern ( pattern ) then
return null
else
return invalid_value_error.create (
message = """'{{value}}' is invalid because it does not match the regular expression '{{pattern}}'."""
id = "INVALID_VALUE"
)
.
.
Note that the actual body code of the check function created by the compiler varies — it depends on the properties defined in the source code. For example, as we'll see soon, the error message returned by the function can be customized in the source code by means of the property error_message.
Function check is implicitly called each time an instance of color_name is created.
We can also call this function explicitly, for instance to check if a given value would be valid. The following example code checks if "<script>" would be a valid color name:
const error = color_name.check ( "<script>" )
if error is null then
write_line ( "OK" )
else
write_line ( error.message )
.
Output:
'<script>' is invalid because it does not match the regular expression '[a-zA-Z ]{3,50}'.
OK. Now consider the definition of attribute name of type color_name:
att name color_name
To check attribute name, the compiler also implicitly creates a specific function for attribute name. This function is defined in type RGB_color, which contains the attribute. It is named check_name (i.e. the prefix check_, followed by the attribute identifier). The function has an input parameter name of type string, and returns null if the value is valid, or else an object of type invalid_object_attribute_error (another type defined in the standard library of a PTS implementation). The body of the function delegates the check to color_name.check, and converts any invalid_value_error object into an invalid_object_attribute_error object. A simplified version of check_name could look like this:
fn check_name ( name string ) -> invalid_object_attribute_error or null
const type_error = color_name.check ( name )
if type_error is null then
return null
else
return invalid_object_attribute_error.create (
message = type_error.message
id = "INVALID_OBJECT_ATTRIBUTE"
)
.
.
Function check_name is implicitly called each time an instance of RGB_color is created.
We can also call this function explicitly, for instance to check if a given value would be valid. The following code shows how to check if "<script>" is a valid value for attribute name:
const error = RGB_color.check_name ( "<script>" )
if error is null then
write_line ( "OK" )
else
write_line ( error.message )
.
Output:
'<script>' is invalid because it does not match the regular expression '[a-zA-Z ]{3,50}'.
Custom Error Messages
As seen in the previous section, an invalid color name would produce an error message like this:
'<script>' is invalid because it does not match the regular expression '[a-zA-Z ]{3,50}'.
While such a generic error message can be understood by software developers, and might be acceptable during prototyping, it is of little help for end-users who are unfamiliar with regular expressions. Therefore we can provide a customized error message through the error_message property. Moreover, we can provide a customized error identifier. Here is an example:
type color_name = string (
pattern: "[a-zA-Z ]{3,50}"
error_message: "A color name must contain between 3 and 50 characters. Only letters and spaces are allowed."
error_id: "INVALID_COLOR_NAME" )
Note
Under the hood, properties pattern, error_message, and error_id are all taken into account when the compiler creates function color_name.check (described in section Function check).
Instead of hard-coded values for pattern, error_message, and error_id, we could also provide an expression that evaluates to a string. For example, we could call a function to retrieve a localized error message from a resource file.
Attribute Property check
Using the pattern property is fine if a string actually needs to be restricted by a regular expression. If we need a more general way to constrain a string, we can use the check property. This property requires a boolean expression to check whether a given value is valid. If the boolean expression evaluates to true, the value is valid — otherwise it is invalid. Therefore, instead of coding:
type color_name = string ( pattern: "[a-zA-Z ]{3,50}" )
... we could also write:
type color_name = string ( check: value.matches ( pattern.create ( "[a-zA-Z ]{3,50}" ) ) )
Note
Under the hood, the compiler will use the check property to create an appropriate color_name.check function (described in section Function check).
Property check can be used to constrain any type — not just strings, but also all other scalar types, as well as collections, record types, etc.
Suppose we need a type representing a prime number. First, we need a function that checks whether an integer is a prime number. This function takes an integer as input and returns a boolean. Suppose that function is_prime_number exists already in module math. Then type prime_number can easily be defined as follows:
type prime_number = integer ( check: math.is_prime_number ( value ) )
A valid prime number can now be created with prime_number.create ( 17 ). However, prime_number.create ( 2 ) would result in a compile-time error.
Now suppose we need a list containing between 10 and 20 prime numbers. Here is the code:
type prime_numbers = list<prime_number> ( size_range: 10 .. 20 )
In this code size_range is a specific property supported for type list, used to constrain the number of elements in the list.
Attribute Property check_code
Property check only supports type constraints that can be expressed with a boolean expression. This is often sufficient. However, if we need finer control over the attribute validation and/or the generated error, we can instead use a check_code property.
The value of check_code is the body of the implicitly created function described in section Function check. This function takes an attribute value as input, and returns null if the value is valid, or else an object of type invalid_object_attribute_error. The code can do whatever needs to be done to check the value, and return a more specific and user-friendly error message depending on the error encountered.
Here is an example of how to do this for attribute name, using property check_code:
type RGB_color
att name string (
check_code:
if name.matches ( pattern.create ( "[a-zA-Z ]{3,50}" ) ) then
return null
.
const length = name.length
const error_message = case
when length < 3:
"""Name is invalid because it has only {{length}} characters. It must at least have 3 characters."""
when length > 50:
"""Name is invalid because it has {{length}} characters. More than 50 characters are not allowed."""
otherwise:
"Name can only contain letters and spaces."
.
return invalid_object_attribute_error.create (
message = error_message
id = "INVALID_COLOR_NAME" )
.
)
...
.
Programmatic Attribute Validation
If an attribute uses a constrained type, we can programmatically check at run-time whether a given value is valid, by calling the check_{attribute_name} function which the compiler implicitly creates for the attribute (as described in section Function check). The function takes an attribute value as input, and returns null if the value is valid, or else an object of type invalid_object_attribute_error. In the latter case the error object returned by the function contains additional information (error message, identifier, etc.) that can be explored by client code — for example to display an ad hoc error message to the user.
The code below shows how to check whether a value provided by the user at run-time is valid for attribute name:
const user_value = GUI_dialogs.ask_string ( message = "Please enter a color name" )
if RGB_color.check_name ( user_value ) as input_error is null then
GUI_dialogs.info ( message = "Value is OK." )
else
GUI_dialogs.error (
title = "Invalid color name"
message = input_error.message )
.
Record Validation
Besides constraining individual attributes, it is sometimes necessary to constrain the whole record instance, using two or more interrelated attributes.
This can be achieved with a check or a check_code property defined at the record level.
Record Property check
Consider a point in a 2-dimension space. Suppose that point (0, 0) is not allowed. That is, x and y cannot both be zero. We can use a check property to specify this:
record type point_2D
atts type:integer
x
y
.
check: not ( x =v 0 and y =v 0 )
.
Note
Operator =v is used in PTS syntax for comparing values, and #v for negated comparisons. Hence, instead of:
check: not ( x =v 0 and y =v 0 )
... we could also write:
check: x #v 0 or y #v 0
Customized error messages and identifiers can be specified with properties error_message and error_id:
record type point_2D
...
check: not ( x =v 0 and y =v 0 )
error_message: "x and y cannot both be zero."
error_id: "INVALID_POINT_2D"
.
Note
Under the hood, the compiler creates function point_2D.check, taking into account properties check, error_message, and error_id.
The function takes one input argument per attribute, and returns null if the values are valid, or else an object of type invalid_object_error.
The signature looks like this:
fn check ( x integer, y integer ) -> invalid_object_error or null
Attribute and record validations can be combined. For example, if x and y must be in the range -100 .. 100, we can do this:
record type point_2D
atts type:integer ( range: -100 .. 100 )
x
y
.
check: not ( x =v 0 and y =v 0 )
.
Record Property check_code
Similar to the check_code property for individual attribute validation, there is also a check_code property available for finer control over record validation. The value of check_code is the body of the check function that takes one input argument per attribute, and returns null if the values are valid, or else an object of type invalid_object_error.
Let's look at an example.
At the end of section Records in Java we mentioned the risk of displaying dark text on a black background, leading to unreadable text. To eliminate this problem, we can define type light_RGB_color, and use this type for the text. Type light_RGB_color has the same attributes as the previously created type RGB_color. Therefore, we can use type inheritance (explained later) for type light_RGB_color. Then we only need to add a check_code property to ensure that the color is light:
type light_RGB_color
inherit RGB_color // inherit all attributes, and function 'to_string'
check_code:
if color_utils.is_light_color ( red, green, blue ) then
return null
else
return invalid_object_error.create (
message = "The color is too dark."
id = "INVALID_DARK_COLOR" )
.
.
.
Note
Color algorithms can be quite complex (and the topic is definitely beyond the scope of this article). Therefore, in the above code I just assumed the code has access to a third-party color_utils library with function is_light_color.
So far we assumed that the background color is always black. However, if the background color is variable, then we would need to ensure that the combination of text and background colors result in text that's easy to read. For example, if the text color is (100, 100, 100), and the background color (100, 100, 110), then the contrast is too low and this pair of colors should not be allowed. This constraint can be achieved as follows:
type readable_RGB_color_pair
att text_color RGB_color
att background_color RGB_color
check_code:
if color_utils.is_readable_text ( text_color, background_color ) then
return null
else
return invalid_object_error.create (
message = """Text color {{text_color}} on background color {{background_color}} is unreadable."""
id = "UNREADABLE_TEXT_COLORS"
)
.
.
.
Note
In this code we assume that function color_utils.is_readable_text checks if there is sufficient contrast and takes into account color accessibility rules for visually impaired people.
For more information you can read Contrast and Color Accessibility and Colors with Good Contrast. You can also have a look at Tristano Ajmone's amply commented implementation of the Delta E 2000 (ΔE*00) algorithm.
Programmatic Record Validation
If a record check or check_code property is defined, we can programmatically check at run-time whether a given set of attribute values would be valid to create an object, by calling the check function which the compiler implicitly creates for the type. The code below shows how to check whether user-provided values for a readable_RGB_color_pair object are valid:
const error = readable_RGB_color_pair.check (
text_color = user_provided_text_color
background_color = user_provided_background_color )
if error is null then
write_line ( "OK" )
else
write_line ( """Invalid colors: {{error.message}}""" )
.
Immutability by Default
Quote:If you don't think managing state is tricky, consider the fact that 80% of all problems in all complex systems are fixed by rebooting.
— Stuart Halloway
Here is a fundamental PTS rule: All data is immutable by default.
For record types, this means that, after a record has been created/initialized with a set of fixed values, it's invalid to re-assign another value to an attribute:
const black = RGB_color.create ( name = "Black" ) black.name = "Red" <<< INVALID!
Attributes can explicitly be declared to be mutable with the mutable keyword preceding att. In the following code, type mutable_wrapper holds a mutable value:
record type mutable_wrapper
mutable att value type:any
.
Note
By convention, the name of mutable types start with the mutable_ prefix (e.g. mutable_wrapper).
After creating a mutable_wrapper object, another value can be assigned to attribute value:
const item = mutable_wrapper.create ( "foo" ) write_object ( item.value ) ... item.value = 123 write_object ( item.value )
Output:
foo 123
Note
The rule "Records are immutable by default" doesn't necessarily mean that the attribute values of an instance can't change. If an attribute holds a value of a mutable type, then the value itself can change, but the same instance in memory is still assigned to the attribute.
For example, consider an attribute holding a mutable list. If an element is added to the list, then the attribute value changes, although the attribute still points to the same mutable list.
Hence, by default attributes in record types are guaranteed to be shallowly immutable, but not necessarily deeply immutable.
Type Parameters
Suppose we need a record type to store a pair of strings. We could do this:
record type string_pair
att item_1 string
att item_2 string
.
If we also need a pair of integers, we can create another type:
record type integer_pair
att item_1 integer
att item_2 integer
.
This quickly becomes cumbersome if we also need pairs for other types, such as decimal, boolean, date, time, etc.
To avoid code duplication we could (but shouldn't) define a single type pair that can hold items of any type:
record type pair
att item_1 any
att item_2 any
.
However, this is a bad solution for two reasons:
-
We lose type safety.
Consider the following code, where we accidentally mix two different types in a pair:
const pair = pair.create ( item_1="foo" item_2=123 )
No compile-time error is generated. Worse, the code doesn't end up in a run-time error either.
This is error-prone.
-
When we access an item, we have to cast it to the correct type (because every item is of type
any). We'll end up writing code like this:if pair.item_1 as item_1 is string then write_line ( item_1 ) else write_line ( "Error: Type string expected." ) .This is impractical.
Both problems are eliminated if we use a type parameter, as follows:
record type pair <item_type>
att item_1 item_type
att item_2 item_type
.
In this code, we declare a type parameter purposely named <item_type> — a placeholder for a concrete type that will be determined whenever an object of type pair is created. For example:
const string_pair pair<string> = pair<string>.create ( item_1="foo" item_2="bar" ) const integer_pair pair<integer> = pair<integer>.create ( item_1=100 item_2=200 )
Type inference allows us to shorten the code:
const string_pair = pair.create ( item_1="foo" item_2="bar" ) const integer_pair = pair.create ( item_1=100 item_2=200 )
If we accidentally use two different types for the items, a compile-time error is reported. Hence we are type-safe again.
Accessing items becomes straightforward too, because the compiler knows the type of the items, and produces an error if we assume the wrong type. We don't need to check the type, and can simply write code like this:
const string_pair = pair.create ( item_1="foo" item_2="bar" ) ... const item_1 string = string_pair.item_1 // type safe! // const test integer = string_pair.item_1 // compile-time error
Type parameters (also known as generic programming, generic type parameters, generics, etc.) are a very useful addition to a type system, because they allow us to write generic code that is type-safe. However, while the basic idea is simple to grasp, type parameters is a complex subject — in my experience, the most challenging feature to get right in a type system. The above example merely scratches the tip of the iceberg. To keep this section short, we'll abstain from delving into details — let's just look at one more example to illustrate the benefits.
In the previous section we defined type mutable_wrapper as follows:
record type mutable_wrapper
mutable att value type:any
.
To increase type-safety, we can again use a generic type parameter:
record type mutable_wrapper <value_type>
mutable att value type:value_type
.
Usage example:
const string_wrapper = mutable_wrapper.create ( "foo" ) ... string_wrapper.value = "bar" // ok // string_wrapper.value = 123 // compile-time error ... const value string = string_wrapper.value // ok // const test integer = string_wrapper.value // compile-time error
If we need a wrapper for any type, we can do this:
const any_wrapper = mutable_wrapper<any>.create ( "foo" )
...
any_wrapper.value = "bar" // ok
any_wrapper.value = 123 // ok
...
case type of any_wrapper.value
when string
write_line ( "It's a string." )
when number
write_line ( "It's a number." )
otherwise
write_line ( "It's something else." )
.
Type Inheritance
Note
Type inheritance must not be confused with implementation inheritance — these are different concepts. PTS type inheritance is similar to interface inheritance in C# and Java. Implementation inheritance (e.g. class inheritance in C#, Java, and other languages) is not covered in this article.
Consider a software application for a shop that sells computer hardware. Here is a very simplified version of type product:
record type product
atts
identifier string
name string
price decimal
.
.
Suppose the shop sells laptops and printers. A laptop has three more string attributes: CPU, RAM and hard_disk. For printers, let's say we need one additional boolean attribute: is_color_capable. Of course, the shop sells other products too (monitor, mouse, keyboard, etc.), and some of them also require additional, specific attributes.
There are several ways to code this, depending on the features supported by the type system. However, as far as I know, a type-safe and practical solution can only be coded if type inheritance is supported. Type laptop can then be defined as follows:
record type laptop
inherit product
atts type:string
CPU
RAM
hard_disk
.
.
The line inherit product states that everything defined in type product is also implicitly defined in type laptop. Hence, type laptop also has attributes identifier, name, and price.
Type printer looks like this:
record type printer
inherit product
att is_color_capable boolean
.
Besides providing type-safety, type inheritance also gives us type substitutability — an important and distinctive OO feature. Objects of type laptop and printer are compatible to type product. That is, each time a product object is required, we can also provide a laptop or printer object. Thus, type inheritance supports the Liskov substitution principle.
Type inheritance is a vast subject — too vast to be fully covered here.
However, there is one specific PTS feature worth mentioning here: in a child type we can redefine members inherited from a parent type, as long as the Liskov substitution principle is preserved. In the case of record types, this allows us, for example, to reduce the type cardinality for inherited immutable attributes, resulting in additional type-safety.
To illustrate this, let's assume that a product identifier is composed of two uppercase letters, followed by 6 digits:
record type product
atts
identifier string ( pattern: "[A-Z]{2}\d{6}" )
...
.
.
Let's also suppose that laptop identifiers must start with "LT", and printer identifiers with "PR". We can achieve this by redefining attribute identifier in types laptop and printer, and use an and_check to add further constraints:
record type laptop
inherit product
redefine
att identifier and_check: identifier.starts_with ( "LT" )
.
.
...
.
record type printer
inherit product
redefine
att identifier and_check: identifier.starts_with ( "PR" )
.
.
...
.
Now, whenever a laptop object is created, the identifier must pass the check defined in type product and the additional check defined in type laptop. Likewise, printer instances must pass the checks defined in types product and printer.
The with Operator
Sometimes we need to create a copy of an immutable record object, with one or more attributes changed.
Consider the following code:
record type point_3D
atts type:integer
x
y
z
.
.
const location = point_3D.create ( x=100 y=200 z=300 )
Suppose we want to create a new location with the z attribute incremented by 100. Without the with operator we could code:
const new_location = point_3D.create (
x = location.x
y = location.y
z = location.z + 100
)
Code like this is cumbersome to read, write, and maintain, especially for record types with many attributes.
The with operator simplifies the code:
const new_location = location with ( z = location.z + 100 )
As you can see, noise is now eliminated. The code is shortened to what matters, and it doesn't need to be updated anymore if other attributes are added, removed, or renamed later.
Structured Documentation
Pretty much every programming language provides a way to insert comments into source code. Here is an example of comments in PTS:
// single line comment
index = 1 // comment at the end of a line
///
A
multiline
comment
///
Comments can be nested
.///
.///
Besides comments, we also need a way to provide structured documentation that can be retrieved programmatically. In case of record types, we should be able to document the type as a whole, as well as each attribute individually. Each documentation object should at least provide a title and a description.
Here is an example of type RGB_color with documentation for the type and for attribute name:
type RGB_color \
title: "Named RGB color" \
description: "A named color with red, green, and blue values."
att name color_name \
title: "Color name" \
description: "The name of the color."
...
.
Here we use the built-in, optional properties title and description for structured documentation purposes.
Note
The backslash (\) at the end of some lines is used as a line continuation character. No semicolon (;) is used to mark the end of a statement — therefore a line continuation character is needed for statements that spread over multiple lines.
Structured documentation in source code can be retrieved in different ways (not covered in this article). For example, documentation could be accessed programmatically at run-time to build a user-friendly GUI data entry form. Code to retrieve documentation into constants looks like this:
const record_title = RGB_color.doc.title const record_description = RGB_color.doc.description const name_doc = RGB_color.atts.name.doc const name_title = name_doc.title const name_description = name_doc.description
A PTS implementation should allow text to be styled, using markup code such as HTML or PML. For example, to display the field names in italics using PML, we can use the [i ...] syntax, as follows:
description: "A named color with [i red], [i green], and [i blue] values."
The text is rendered like this:
A named color with red, green, and blue values.
Serializing/Deserializing Record Objects
When a record object is serialized, the data contained in memory is written to a standard (or non-standard) text or binary format.
Deserializing is the inverse process — it's used to retrieve (read) objects persisted in a resource.
Serializing/deserializing data is useful in various projects. For example, it can be used to:
-
send data over the wire
-
persist objects into a resource such as a file
-
display data in memory as text (very useful for debugging purposes)
-
use standard OS files as a database, when a real database would be overkill
-
use editable text files to read and write structured configuration data
Unfortunately, code to serialize/deserialize data is cumbersome to write and maintain, and error-prone, especially if it's needed for many different record types. Moreover, reading/writing data is not only useful for records — it is useful for all kinds of data (scalar values, collections, etc.). Therefore a practical type system must provide the fundamental features needed to write generic code once. Then we can use this code again and again to serialize/deserialize any data. For example, writing RGB_color objects to text formats should be as easy as this:
const red = RGB_color.create ( name="red" red=255) write_line ( "XML:" ) XML_writer.write_object_to_STDOUT ( red ) write_line ( "JSON:" ) JSON_writer.write_object_to_STDOUT ( red ) write_line ( "PDML:" ) PDML_writer.write_object_to_STDOUT ( red )
Output:
XML:
<?xml version="1.0" encoding="UTF-8"?>
<RGB_color>
<name>red</name>
<red>255</red>
<green>0</green>
<blue>0</blue>
</RGB_color>
JSON:
{
"RGB_color": {
"name": "red",
"red": 255,
"green": 0,
"blue": 0
}
}
PDML:
[RGB_color
[name red]
[red 255]
[green 0]
[blue 0]
]
Note
For more information about PDML please visit pdml-lang.dev.
To enable the development of serializing/deserializing libraries, a type system must support introspection and reflection, two features that deserve a dedicated article in the context of PTS.
Example
Here is a simplified example of record types used in a bookstore application:
type name = string ( pattern: "[a-zA-Z ]{1,70}" )
type phone_number = string ( pattern: "\+?[0-9 ]{3,15}" )
record type author
atts
first_name name
last_name name
website URL
.
fn to_string = """{{first_name}} {{last_name}}"""
.
record type publisher
atts
name name
phone phone_number
.
fn to_string = name
.
record type book
atts
title string ( length_range: 1 .. 250 )
authors list<author>
publisher publisher
price decimal ( range: 0.00 .. 1_000.00, decimals: 2 )
.
variable att stars \
type: decimal ( range: 1.0 .. 5.0 ) or null \
default: null
fn to_string = """{{title}} by {{authors.to_string}}"""
.
Summary
PTS provides the following key features for record types:
-
concise and clear syntax — without noise or code duplication
-
immutability by default
-
built-in support for easy and flexible data validation, both for individual attributes and for the whole record
-
default values for attributes
-
named attribute assignments to improve readability, reliability, and maintainability
-
type parameters to write generic, type-safe code
-
type inheritance
-
a
withoperator to facilitate creating record copies with some values modified -
a
to_stringfunction for generating short, human-readable descriptions of record objects -
structured documentation
-
support for serializing/deserializing record objects
These features aim to simplify and streamline working with record types, while also increasing reliability, maintainability, and productivity.
In particular, the combination of easy and flexible data validation and immutability by default helps to define very robust record types. A record object can only be created in a valid state, and after creation the state can't change. The object remains in a valid, immutable state during its whole lifetime. This eliminates whole classes of bugs that are often difficult to find and fix, such as bugs caused by non-atomic or non-synchronized state changes, race conditions, and other nasty problems due to shared mutable state in parallel/concurrent runtime environments.
Moreover, the combination of named attribute assignments and default values enable us to reliably create records using different input argument combinations, without the need to define overloaded constructors, or to use the builder pattern.
What's Next?
In the next article we'll have a look at Union Types, a surprisingly useful feature in a practical type system.
Acknowledgment
Many thanks to Tristano Ajmone for his useful feedback to improve this article.