Introduction
You, or one of your colleagues is guilty of everlooking the simplest coding problems... We are all busy individuals, often thinking in imperative programming style, overlooking the consequences of our otherwise innocent actions. This article is a story of one such occurrence ...
Background
How many times have you or someone you know written a piece of code which looks like this:
string retValB;
string retValC;
try
{
retValB = doc.SelectSingleNode("//B").InnerText;
retValC = doc.SelectSingleNode("//C").InnerText;
}
catch
{
retValB = "0";
retValC = "1";
}
There are a few problems with this approach. One, if the retrieval of the B value should fail, the true value of retValC will never be retrieved from the XML document. Two, it takes much more time to attempt a retrieval and fail, than to check if the value is available in the first place.
Example
Consider this example:
using System;
using System.Xml;
namespace ConsoleApplication2
{
internal class Program
{
private static string M1(XmlDocument doc)
{
return doc.SelectSingleNodeOrEmptyElement("//B", "0").InnerText;
}
private static string M2(XmlDocument doc)
{
string retVal;
try
{
retVal = doc.SelectSingleNode("//B").InnerText;
}
catch
{
retVal = "0";
}
return retVal;
}
private static string M3(XmlDocument doc)
{
if (doc.SelectSingleNode("//B") != null)
{
return doc.SelectSingleNode("//B").InnerText;
}
return "0";
}
private static string M4(XmlDocument doc)
{
return doc.SelectSingleNodeInnerTextOrDefault("//B", "0");
}
private static void Main(string[] args)
{
var doc = new XmlDocument();
doc.LoadXml("<R><A>A</A></R>");
var a = doc.SelectSingleNode("//A").InnerText;
var b = M1(doc);
var c = M2(doc);
var d = M3(doc);
var e = M4(doc);
Console.WriteLine(a);
Console.WriteLine(b);
Console.WriteLine(c);
Console.WriteLine(d);
Console.WriteLine(e);
}
}
public static class XmlExtensions
{
private static readonly XmlDocument StaticXmlDocument = new XmlDocument();
private static readonly Func<string, XmlNode> EmptyNode = s =>
{
var newNode = StaticXmlDocument.CreateNode(XmlNodeType.Element,
"EMPTY_ELEMENT_FROM_XPATH", null);
newNode.InnerText = s;
return newNode;
};
public static string SelectSingleNodeInnerTextOrDefault
(this XmlNode node, string xpath, string defaultInnerText = "")
{
if (node.SelectSingleNode(xpath) != null)
{
return node.SelectSingleNode(xpath).InnerText;
}
return defaultInnerText;
}
public static XmlNode SelectSingleNodeOrEmptyElement
(this XmlNode node, string xpath, string defaultInnerText = "")
{
var selected = node.SelectSingleNode(xpath) ?? EmptyNode.Invoke(defaultInnerText);
return selected;
}
}
}
All four methods, M1-M4, an over-simplification of common usage scenarios, perform the same function, but at a drastically different cost to the application.
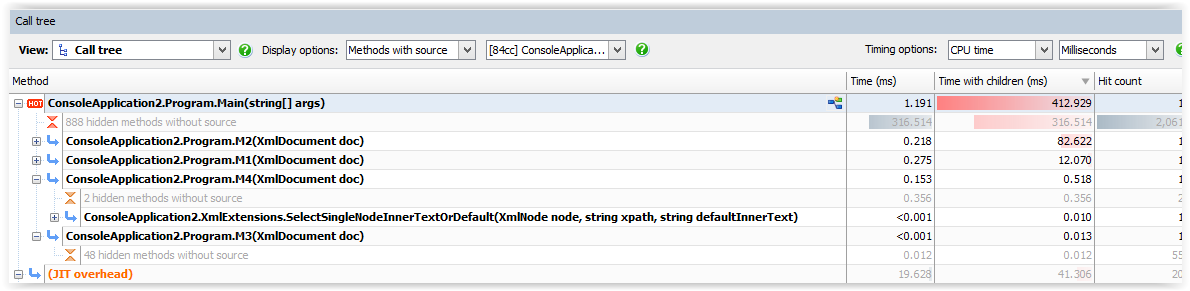
So M2, which depends exclusively on try/catch block, performs the worst at 82ms. M3, which relies on in-line node existence check, takes only 0.013ms. Second best performing is the extension based approach, M4, clocking at 0.518ms., That is over 80ms save for each iteration.
With parallel execution, 1000 times, the difference is still quite significant:

M2, took 116ms. M4 only 27.314ms, while M1, only 13.344ms. So for 1000 checks, we have saved over one tenth of a second, in a parallel execution scenario for 1000 elements.
In a sequential execution, the impact is even more significant:
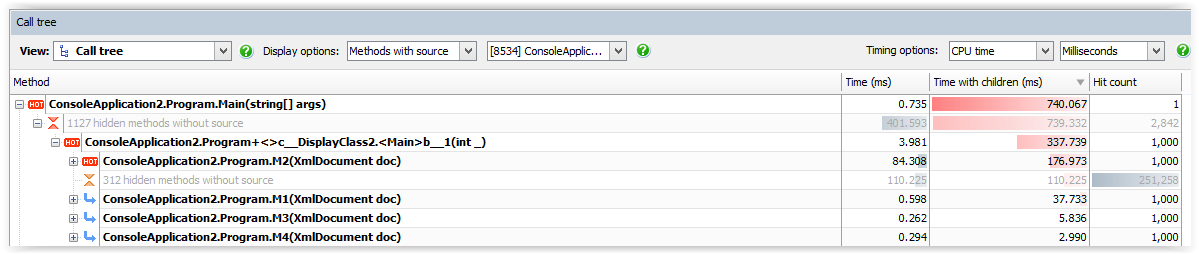
M2 taking almost 177ms to process 1000 objects, while M4 now becoming the fastest with almost 3ms.
Now the methods listed here, M1-M4, are only to capture and demonstrate the performance of each approach. In a production version, given the original buggy example, to avoid having to code each retrieval separately like this:
string retValB;
string retValC;
try
{
retValB = doc.SelectSingleNode("//B").InnerText;
}
catch
{
retValB = "0";
}
try
{
retValC = doc.SelectSingleNode("//C").InnerText;
}
catch
{
retValC = "1";
}
You would simply use the new extension method:
string retValB = doc.SelectSingleNodeInnerTextOrDefault("//B", "0");
string retValC = doc.SelectSingleNodeInnerTextOrDefault("//C", "1");
string retValD = doc.SelectSingleNodeInnerTextOrDefault("//D");
This is all under the assumption that some XML elements in your input data are optional, and default values for them are known and permitted.
Other Scenarios
Consider this example:
using System;
using System.Globalization;
namespace ConsoleApplication5
{
class Program
{
static void Main(string[] args)
{
for (int i = 0; i < 1000; i++)
{
string goodOrBadDate = i % 2 == 0 ?
string.Empty : DateTime.Now.ToString(CultureInfo.InvariantCulture);
var dateOne = ConvertUsingExceptionBased(goodOrBadDate);
var dateTwo = ConvertUsingFramework(goodOrBadDate);
}
}
private static DateTime ConvertUsingFramework(string goodOrBadDate)
{
DateTime dateTime;
if (DateTime.TryParse(goodOrBadDate, out dateTime))
return dateTime;
return default(DateTime);
}
private static DateTime ConvertUsingExceptionBased(string goodOrBadDate)
{
try
{
return DateTime.Parse(goodOrBadDate);
}
catch (Exception)
{
return default(DateTime);
}
}
}
}

They perform exactly the same function, but using the built-in .NET Framework method makes it 142 times faster.
Takeaway
To ensure the highest degree of performance of code we write, we cannot rely on convenience alone. We must properly assess impact and select an approach which is convenient to use, but also best, or second best performing. In this case, we have shown how exception-based programming style leads to unintended side-effects and degradation in performance.
A seasoned IT Professional. Programming and data processing artist. Contributor to StackOverflow.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






