Introduction
Rough
Set theory, proposed by Pawlak, is an effective approach for data analysis and
its main goal is synthesizing approximation of a crisp set in terms of a pair
of sets which give the upper and lower approximation of the original set. The
starting point of Rough Set theory is an observation that the objects having
the same description (same attribute-values) are indiscernible (similar) with
respect to the set of defined attributes and this process is very hard and
sensible when some attribute-values are missing. With Rough Set Sara tool, I
tried to demonstrate some of Rough set concepts for non-expert users. Also, you
can update this tool to define other concepts.
Background
To
introduce the concepts of Rough Sets, let's begin with a data table IS
whose rows represent a set of objects in the universe (e.g. persons, balls, books,
etc.) and columns represent a set of attributes that describe those objects (e.g.
color, shape, age, etc.), formally IS= (U, AT), an Information table
"attribute-value System", where U is the set of objects
and AT is the set of attributes. Every attribute a ∈ AT
has a set of values Va called "Domain of a"
such that a: U→ Va. The information table assigns a value a(x)
from Va
to each attribute a and each object x in the universe U.
If Va contains missing value for at
least one attribute a, then IS is called incomplete
information table, otherwise it is complete.
With
any subset of attributes P  AT, there
is an associated equivalence relation IND (P) = {(x, y) ∈ U2
| ∀ a ∈ P, a(x) =a(y)}. The relation IND
(P) is called a P-indiscernibility relation.
AT, there
is an associated equivalence relation IND (P) = {(x, y) ∈ U2
| ∀ a ∈ P, a(x) =a(y)}. The relation IND
(P) is called a P-indiscernibility relation.
IND (P) = ∩ IND (a) where a ∈ P.
A fundamental problem
discussed in rough set is whether the whole knowledge extracted from data sets
is always necessary to classify objects in the universe; this problem arises in
many practical applications and will be referred to as knowledge reduction. The
two fundamental concepts used in knowledge reduction are the core and reduct.
Intuitively, a reduct of knowledge is its essential part, which suffices to
define all basic classifications occurring in the considered knowledge, whereas
the core
is in a certain sense it’s most important part. Let P set of attributes and let a ∈ P, the attribute a
is dispensable in P if: IND (P) =IND (P - {a}), otherwise a is
indispensable attribute. The set of attributes A, where A P is
called a reduct of P if: IND (A) = IND (P) and P may have many reducts denoted
as RED (P). The set of all indispensable attributes in P
will be called the core of P and denoted as CORE (P) where
CORE (P) = ∩ RED (P).
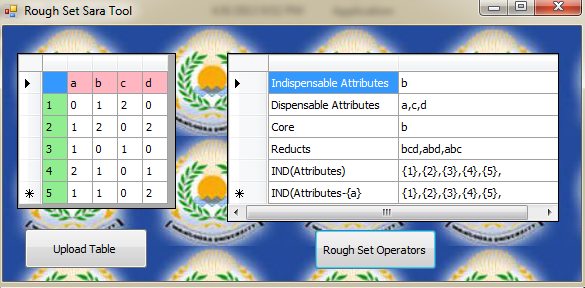
For example consider the following information table:
| U/AT
| a
| b
| c
| d
|
| 1
| 0
| 1
| 2
| 0
|
| 2
| 1
| 2
| 0
| 2
|
| 3
| 1
| 0
| 1
| 0
|
| 4
| 2
| 1
| 0
| 1
|
| 5
| 1
| 1
| 0
| 2
|
When the full set of attributes is considered P= {a, b, c, d}, we see the following equivalence classes "classification
of the objects in the universe":
IND (P) = {{1}, {2}, {3}, {4}, {5}}
Thus all objects are distinguishable under
all set of attributes but if we exclude the attribute b from the set of
attributes, we see the following equivalence classes:
IND (P - {b}) = {{1}, {2, 5}, {3}, {4}}
Thus objects 2&5 are classified as being
similar under this set of attributes which means that the attribute b is important
in distinguishing those two objects from each other.
IND (P - {b}) ≠ IND (P) which means that the two classifications
are not equal. So, b is indispensable attribute.
While IND (P - {a}) = {{1}, {2}, {3}, {4}, {5}} and thus IND (P - {a}) = IND (P). So, a is dispensable
attribute and the set= {b, c, d} without attribute a represent one reduct of the set P.
The reduct set can be used to represent the same classification as a set of attribute P but with minimum number of
attributes required for this classification. The intersection among all reducts of the set P produces the core set of
attributes which represent the most important ones in performing classification correctly.
Using the code
First, the information table that contains a set of attribute-values is located in the text file named Table in Debug folder. You can change these
values according to your needs and your information but note in the same format as provided in the text file.
For simplicity I gave the attributes names such as a, b, c, etc. and these names are given automatically according to the number of columns you
inserted in the Table file. Also, the number of objects is computed according to the number of rows in the text file.
My code has three classes: Attribute, Object, and RoughSet. The class Attribute defines an attribute name and
value for each object in the universe. The class Object defines an object in the universe with its attribute-values information. The
class RoughSet defines a framework for the information table that is supplied in the text file (Table) with a set
of rough set operators that are discussed previously such as:
-
Indecernibility
()
---->IND
(AT) where AT= all attributes defined in the information table that are
given in the text file Table. Indecernibility (object NameAttr) ---->IND (AT - {a}) where the
indecernibility
is computed here with excluding the attribute a that is passed to the
method by its name. Moreover, you can update this method by providing a list of
excluded attributes or other defined attributes such as b, d, ..etc.
Also,
there are a set of methods to compute dispensable, indispensable
attributes as well as core and reducts.
public List<List<object>> Indecernibility()
{
List<List<object>> Result = new List<List<object>>();
for (int i = 0;i< __Objects.Count; i++)
{
List<object> Temp = new List<object>();
Temp.Add(__Objects[i].__Name);
for (int j = 0; j < __Objects.Count; j++)
{
if (i == j)
continue;
else
{
List<Attribute> AttVali = ((List<Attribute>)h[__Objects[i].__Name]);
List<Attribute> AttValj = ((List<Attribute>)h[__Objects[j].__Name]);
for (int f = 0; f < AttVali.Count; f++)
{
if (AttVali[f].value.ToString() == AttValj[f].value.ToString())
{
if (f == AttVali.Count - 1)
{
Temp.Add(__Objects[j].__Name);
}
else
{
continue;
}
}
else
{
break;
}
}
}
}
Result.Add(Temp);
}
return Result;
}
References
For more information about Rough Sets and its Concepts, read the following book "Rough Sets: Theoretical Aspects of Reasoning about data" by Zdzislaw Pawlak.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









