|
Apologies for the oversight. I ought to have included the information which the troubleshooting guide advises to provide before reporting any bugs.
Here are the details from the system info tab:
Server version: 2.5.4
System: Windows
Operating System: Windows (Microsoft Windows 11 version 10.0.22631)
CPUs: Intel(R) Core(TM) i9-10850K CPU @ 3.60GHz (Intel)
1 CPU x 10 cores. 20 logical processors (x64)
GPU (Primary): NVIDIA GeForce GTX 1650 (4 GiB) (NVIDIA)
Driver: 522.30, CUDA: 11.8 (up to: 11.8), Compute: 7.5, cuDNN: 8.9
System RAM: 32 GiB
Platform: Windows
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
.NET framework: .NET 7.0.10
Default Python:
Video adapter info:
NVIDIA GeForce GTX 1650:
Driver Version 31.0.15.2230
Video Processor NVIDIA GeForce GTX 1650
Intel(R) UHD Graphics 630:
Driver Version 31.0.101.2115
Video Processor Intel(R) UHD Graphics Family
System GPU info:
GPU 3D Usage 5%
GPU RAM Usage 2.5 GiB
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
|
|
|
|
|

Log excerpt below:
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 705, in forward
y = self.model(x, augment=augment) # forward
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 515, in forward
y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 209, in forward
return self._forward_once(x, profile, visualize) # single-scale inference, train
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 121, in _forward_once
x = m(x) # run
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 59, in forward
x[i] = self.m[i](x[i]) # conv
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\conv.py", line 460, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: cuDNN error: CUDNN_STATUS_MAPPING_ERROR
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 705, in forward
y = self.model(x, augment=augment) # forward
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 162, in __exit__
self.dt = self.time() - self.start # delta-time
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Client request 'custom' in queue 'objectdetection_queue' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Request 'custom' dequeued from 'objectdetection_queue' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 669, in forward
with dt[0]:
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 158, in __enter__
self.start = self.time()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Client request 'custom' in queue 'objectdetection_queue' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Request 'custom' dequeued from 'objectdetection_queue' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 669, in forward
with dt[0]:
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 158, in __enter__
self.start = self.time()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
Instead of rebooting the entire system, I simply restarted the Yolo 5.6.2 service, and it began working again. Nevertheless, the reliability of the service is concerning, and I'm unsure of how to proceed. I even acquired a GTX 1650 specifically in improve inference, yet I find myself at a loss for solutions. Thus, I am posting here in the hope of discovering what might be causing this frustrating problem. Although it operates, it can unexpectedly stop working, as I've noted as this is pretty concerning.
|
|
|
|
|
In my above response, I outlined the recurring issue and shared log excerpts that pinpointed the onset of errors to 13:21:28 on the 20th of February, 2024. These errors persisted for several hours until they were detected and addressed by restarting the YOLOv5 6.2 service, which temporarily resolved the problem. Despite this workaround, concerns regarding the service's reliability remain.
I have since realised a crucial detail was omitted from my initial system configuration description. Specifically, I did not mention that I was utilising the integrated GPU (iGPU) alongside the dedicated Nvidia GTX 1650 GPU. My intention was to optimise the system's performance for inference tasks, allocating the iGPU for display purposes and dedicating the GTX 1650 exclusively to computational AI processing. This dual-GPU setup, I presumed, would offer the best of both worlds: efficient display management and powerful, dedicated AI processing capabilities.
However, the persistent issue and the specific nature of the error messages suggest that this configuration might be contributing to the problem. The error logs indicating "an illegal memory access was encountered" and "CUDNN_STATUS_MAPPING_ERROR" hint at potential complications arising from this dual-GPU setup.
In light of this, I have taken steps to modify my system's configuration. I entered the BIOS settings and disabled iGPU support, making the GTX 1650 the sole graphics card in use. It is my hope that this change might eliminate the aforementioned errors and enhance the system's stability and performance.
I am sharing this update to provide a complete picture of my system's setup and the measures I've taken to address the issue. While it is possible that using both the iGPU and the Nvidia GTX 1650 in tandem might have been overly ambitious or complicated the system's configuration, identifying the exact cause of the problem has proven challenging.
I am eager to hear your thoughts or suggestions on this matter. Could the dual-GPU setup have been a contributing factor to the issues experienced? Any insights or recommendations on how to proceed would be greatly appreciated as I strive to achieve the optimal setup for reliable and efficient inference performance.
Thank you for your attention and assistance.
|
|
|
|
|
That's good thinking but I don't think that will make any difference. The YOLO6.2 code uses PyTorch which will use either 'cpu' or 'cuda' as the device on your setup, meaning plain old CPU or your CUDA enabled GPU. It won't even spare a sideways glance at your iGPU.
I noticed your card has 4GB RAM. I'm just wondering if that is the issue here: running out of headroom.
Can you try using a smaller model size, or if you actually would like to use the iGPU, you could switch to the .NET Object detection module which uses DirectML
cheers
Chris Maunder
|
|
|
|
|
Dear Chris,
Thank you for your insights. I understand your point about PyTorch leveraging either 'cpu' or 'cuda' for computations, which essentially rules out the use of the IGPU for display output only. I initially opted for the Nvidia 1650 because I was aware that using the iGPU for AI tasks could significantly burden the CPU, which is not ideal.
Regarding the 4GB RAM on the Nvidia card, it's a common specification across similar models, and it appears to be the card of choice for many within the CodeProject AI community. Most setups I've researched seem to employ a medium model, which led me to believe that this configuration should be sufficient. The idea that CPAI might exhaust memory to the point of failure is somewhat surprising to me. Surely, there must be a threshold of efficiency and performance that allows for effective operation without constant failures due to memory limitations?
For the time being, I have disabled onboard GPU support in the BIOS and am exclusively using the Nvidia 1650. I plan to monitor how this configuration performs over the next few days. This should hopefully provide some clarity on whether the 4GB RAM is indeed the bottleneck or if there might be other underlying issues at play.
I am keen to hear your thoughts on whether CPAI inherently demands more memory than what the Nvidia 1650 can provide, or if there are adjustments and optimizations that could mitigate these memory consumption issues.
Best regards,
|
|
|
|
|
I have a NVIDIA 1030 and it's pretty basic but still does OK. The trick is definitely to balance accuracy and model size, so I'd definitely recommend trying a smaller model size (the dashboard allows you to do this via the gear icons on each module). Also try to minimise the number of modules you have that are using the GPU.
cheers
Chris Maunder
|
|
|
|
|
Upon waking, I found the system had failed again, prompting me to now switch to a smaller model as you have suggested.
My current setup includes only the Object Detection (YOLOv5 .NET), Object Detection (YOLOv5 3.1), and Face Processing modules, with the .NET and Face modules disabled. Is disabling these sufficient, or should they be uninstalled?
Another critical question is whether the number of cameras using CPAI affects performance. I'm using three cameras with CPAI, considering whether to limit the system to just the most crucial camera if necessary, though ideally, there shouldn't be a restriction on the number of cameras I would have presumed but I thought I'd ask.
Thanks again
|
|
|
|
|
I'm reaching out again to share an update and seek further assistance with the persistent issues I've been experiencing with the CPAI setup.
Following your suggestion, I've adjusted my setup to utilise a smaller model size (small not tiny), hoping this would alleviate the CUDA errors and improve system stability. Unfortunately, the issue persists, with CPAI crashing recurrently within a 10-12 hour timeframe. This pattern has become evident through manual logging, as CPAI does not retain log files adequately. Since November 2023, I've been actively seeking solutions on the Blue Iris forum to reduce false flags, which led me to integrate CPAI into my system. However, the stability issues have become a significant concern.
I've found it necessary to circumvent this problem is to restart the CPAI service at least twice daily to maintain operation outside the 10-12 hour crash window, a workaround that is far from ideal.
Conversations with a moderator on the Blue Iris Forum revealed that their system, running a medium-sized model, has remained stable since 31 January, who runs the same GPU 1650 4GB Ram, utilising the same drivers etc. starkly contrasting with my experience where the system fails to last more than 10 hours.
Given these circumstances, I'm at a loss for how to proceed. The recurrent failures despite model size adjustments, and the apparent anomaly in system behaviour compared to others in the community, suggest there may be an underlying issue not yet identified.
In our previous discussions, you mentioned the possibility of switching to the .NET Object detection module which uses DirectML as an alternative. However, won't this switch mess up inference times ?
Could you please advise if there's anything more I can do to diagnose and resolve these stability issues? Is there a possibility that the driver versions I'm using could be contributing to the problem, or is there any additional information I can provide that might offer further insights? The lines of code provided in the error messages, particularly those related to CUDA errors and illegal memory access, have not offered a clear path to resolution.
This situation is particularly frustrating, given the time and effort invested in finding a viable solution. The necessity of frequent service restarts is untenable, and I'm eager to find a more permanent fix to ensure reliable system operation.
Any assistance or insights you can offer would be greatly appreciated. Thank you for your time!
Kind regards
ZK
|
|
|
|
|
Just an update . Version 2.5.6 installed and no more errors with CUDA.. Very odd but great nonetheless!
|
|
|
|
|
Our free, local install Artificial Intelligence server. Any platform, any language.
How can I change English to another language in UI interface and in recognition? Now it can recognize only english words.
|
|
|
|
|
Any *programming* language. I guess we should not have made the assumption on that term.
cheers
Chris Maunder
|
|
|
|
|
|
The main article CodeProject.AI Server: AI the easy way.[^] has the changelog at the end, and I try and keep that one as up to date as possible. The docs also have a changelog[^] but as you can see it's a little behind the main article by a patch version
cheers
Chris Maunder
|
|
|
|
|
I've just started to try and run CodeProject AI. I'm using Windows 7 SP2 on a laptop with an Intel i3 processor. CodeProject.AI Server installs and sits as a service. However, entering http://localhost:32168 results in:
Firefox can’t establish a connection to the server at localhost:32168
IE doesn't work, and Google Chrome doesn't work. Does someone have advice on how to get to the dashboard so I can proceed to testing?
Rick g
|
|
|
|
|
Unfortunately we don't support Windows 7, but that doesn't mean it won't run.
Are there any errors shown in the Windows Event Viewer?
You could also try stopping the service, then going to C:\Program Files\CodeProject\AI\server and running server.exe in a terminal so you can see any output directly. That would show if something's crashing.
cheers
Chris Maunder
|
|
|
|
|
OK . . . . so the "service" was stopped . . . I opened a cmd prompt window . . . . navigated (by changing directories) to the CodeProject.AI server executable . . . and ran it. It seemed to install the server again, but as an app, though there was considerable output in the cmd prompt window:

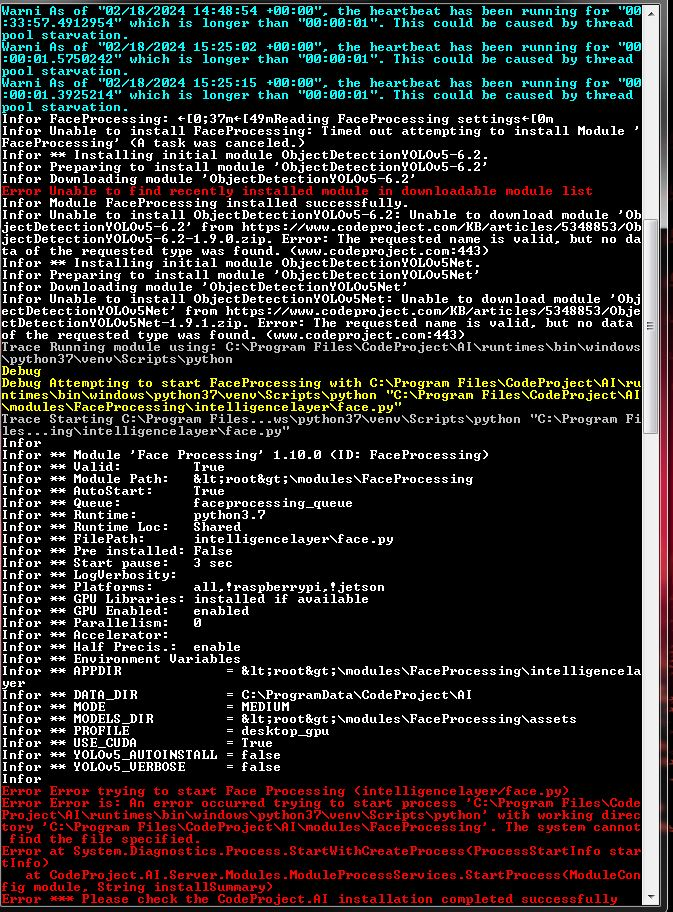
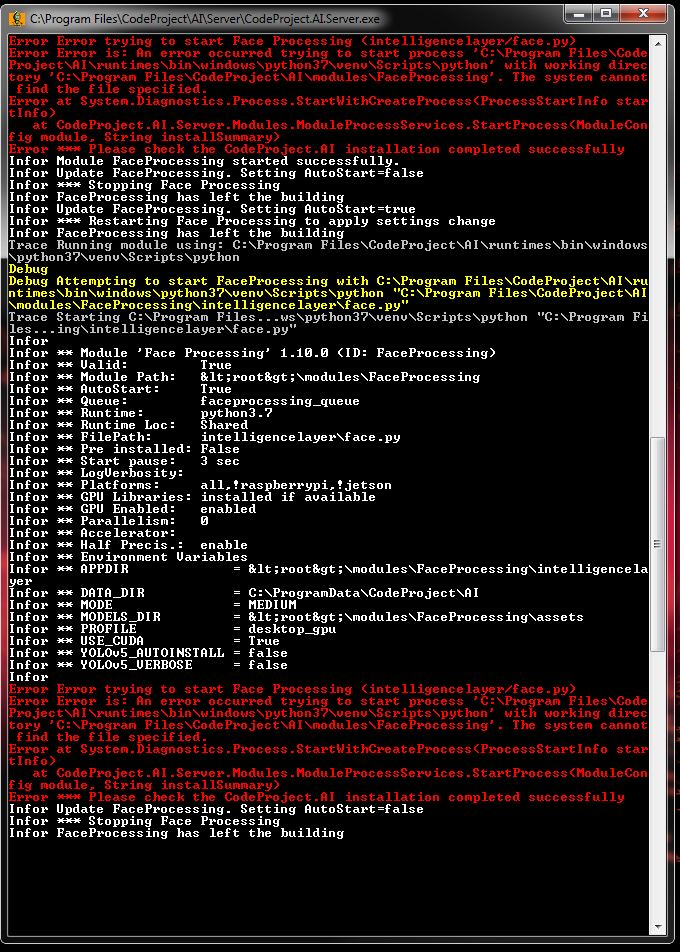
I have no clue what this is telling me, though it seems that some files were missing from the download and install.
None-the-less . . . when I entered http://localhost:32168 into my browser . . .. I did get a Dashboard of sorts. . . . but not exactly what you show on your website:

I then went about looking at the processes and services that were running, and noticed my CPU usage was running at about 70% . . . and with no app taking credit for the CPU usage. Unfortunately, the task manager doesn't report on CPU usage by services. Couldn't find anything to kill, so I uninstalled CodeProject.AI both as an app and as a service for now. CPU usage was still running at 70%. Rebooted the laptop and now all is quiet and well.
If you have any advice on how to get this to run on older laptop running Windows 7 like this, it would be appreciated.
Regards,
Rick g
|
|
|
|
|
When you run the exe directly, it starts up as an exe, rather than as a service. It's still registered as a service (though not sure since we don't have Win7 machines to test this on).
I can see it's trying to install the modules but it's timing out. Now that you're in the thick of things let's go one more step:
Open the terminal to C:\Program Files\CodeProject\AI\modules\FaceProcessing and then type `..\..\setup` and enter. Then go to C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2 and again `..\..\setup`.
The restart the server once both have finished.
cheers
Chris Maunder
|
|
|
|
|
Since I had uninstalled everything . . . I re-installed from the download executable. Then navigated to ...CodeProject\AI\modules directory. Nothing is in there. . . .so I can't go to FaceProcessing nor ObjectDetection....
I guess this just isn't going to work on Windows 7.
|
|
|
|
|
Hey,
My network provider (Telekom, quite popular provider in Germany) seems to have issues with the code project hosting. Downloading the installer was very slow at about 50 KB per second with many failed attempts. I managed to get the installer using my mobile plan. However, the connection problem now stops me from installing modules (as I cannot use my mobile-connection on the server), which makes it impossible to use object detection.
I've attached an excerpt from the server logs showing the issue when trying to download the module.
The target folder for the download does not contain any files.
22:47:26:ObjectDetectionYOLOv5Net: Reading ObjectDetectionYOLOv5Net settingsUsed modulesettings.json to get value Object Detection (YOLOv5 .NET)
22:47:26:ObjectDetectionYOLOv5Net: .Used modulesettings.json to get value 1.9.3
22:47:27:ObjectDetectionYOLOv5Net: .Used modulesettings.json to get value dotnet
22:47:27:ObjectDetectionYOLOv5Net: .Used modulesettings.json to get value Shared
22:47:27:ObjectDetectionYOLOv5Net: .Used modulesettings.windows.json to get value bin\ObjectDetectionYOLOv5Net.exe
22:47:27:ObjectDetectionYOLOv5Net: .Used modulesettings.json to get value true
22:47:28:ObjectDetectionYOLOv5Net: .Used modulesettings.json to get value ["all"]
22:47:28:ObjectDetectionYOLOv5Net: .Done
22:47:28:ObjectDetectionYOLOv5Net: Installing module Object Detection (YOLOv5 .NET) 1.9.3
22:47:28:ObjectDetectionYOLOv5Net: Variable Dump
22:47:28:ObjectDetectionYOLOv5Net: moduleName = Object Detection (YOLOv5 .NET)
22:47:28:ObjectDetectionYOLOv5Net: moduleVersion = 1.9.3
22:47:28:ObjectDetectionYOLOv5Net: runtime = dotnet
22:47:28:ObjectDetectionYOLOv5Net: runtimeLocation = Shared
22:47:28:ObjectDetectionYOLOv5Net: installGPU = true
22:47:28:ObjectDetectionYOLOv5Net: pythonVersion =
22:47:28:ObjectDetectionYOLOv5Net: virtualEnvDirPath =
22:47:28:ObjectDetectionYOLOv5Net: venvPythonCmdPath =
22:47:28:ObjectDetectionYOLOv5Net: packagesDirPath =
22:47:28:ObjectDetectionYOLOv5Net: moduleStartFilePath = bin\ObjectDetectionYOLOv5Net.exe
22:47:28:ObjectDetectionYOLOv5Net: Downloading ObjectDetectionYOLOv5Net-DirectML-1.9.3.zip to C:\Program Files\CodeProject\AI\downloads\ObjectDetectionYOLOv5Net\bin
22:47:28:ObjectDetectionYOLOv5Net: Downloading ObjectDetectionYOLOv5Net-DirectML-1.9.3.zip...Checking 'C:\Program Files\CodeProject\AI\downloads\ObjectDetectionYOLOv5Net\ObjectDetectionYOLOv5Net-DirectML-1.9.3.zip'
22:47:54:Response timeout. Try increasing the timeout value
Is this a known issue? Are there any alternative download links I could use to obtain the module?
Best
|
|
|
|
|
|
Is there any chance you could do a tracert to www.codeproject.com and email me the results? (chris@codeproject.com)
cheers
Chris Maunder
|
|
|
|
|
Done 
|
|
|
|
|
Medium on Coral using CPAI used to take like ~114ms on the maximum performance driver. But after updating, it's taking ~14ms per detection, and checking from Blue Iris, the detections are way worse now than before.
I tried Large but that's like ~240ms, so it's too slow. What happened to Medium?
(btw, Coral is always "Lost Contact" now)
|
|
|
|
|
I had the same experience. I have an M.2 single TPU but after the update it was set to Multi-TPU. I disabled Multi-TPU Support and everything is running much better. More accurate detection and about the speed it was before.
|
|
|
|
|
I tried disabling multi-TPU but it's still the same. Seems like Small and Medium are exactly the same now for some reason
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






