|
IF YOU ARE HAVING A PROBLEM
- Take a look at the logs in
C:\Program Files\CodeProject\AI\logs and see if there's anything in there that screams 'something broke'.
- Check the FAQs in the CodeProject.AI Server documentation
- Make sure you've tested the server using the Explorer (blue link, top middle of the dashboard) to ensure it's a server issue rather than something else such as Blue Iris or another app using CodeProject.AI server.
- If there's no obvious answer, then copy and paste into a message the contents of the System Info tab, describe what you are doing, and what you see, and what you would expect.
Always include a copy and paste from the System Info tab of the dashboard. It gives us a ton of info on your setup. If an individual module is failing, click the 'Info' button to the right of the module's name in the status list and copy and paste that info too.
How to reinstall a module
Option 1. Go to the install modules tab on the dashboard and try re-installing the package. Make sure you have enough disk space and a reliable internet connection.
Option 2: (Option 1 with a vengeance): If that fails, head to the module's folder ([app root]\modules\module-id), open a terminal in admin mode, and run ..\..\setup. This will force a manual reinstall using the install script.
Docker: In Docker you will need to open a terminal into the docker container. You can do this using Docker Desktop, or Visual Studio Code with the Docker remote extension, or on the command using using docker attach. Then do a cd /app/modules/module-id where module-id is the id of the module you need to resinstall. Next, run sudo bash ../../setup.sh --verbosity info to force a manual reinstall of that module. (Set verbosity as quiet, info or loud to get less or more info)
cheers
Chris Maunder
modified 18-Feb-24 15:48pm.
|
|
|
|
|
If you are a Blue Iris user and you are using custom models, then you would notice that the option, in Blue Iris, to set the custom model location is greyed out. This is because Blue Iris does not currently make changes to CodeProject.AI Server's settings. It can be done by manually starting CodeProject.AI with command line parameters (not a great solution), or editing the module settings files (a little messy), or setting system-wide environment variables (way easier). For version 1.6 we added an API to allow any app to change our settings programmatically, and we take care of stopping/restarting things and persisting the changes.
So: Blue Iris doesn't currently change CodeProject.AI Server's settings, so it doesn't provide you a way to change the custom model folder location from within Blue Iris.
Blue Iris will still use the contents of this folder to determine the calls it makes. If you don't specify a model to use in the Custom Models textbox, then Blue Iris will use all models in the custom models folder that it knows about.
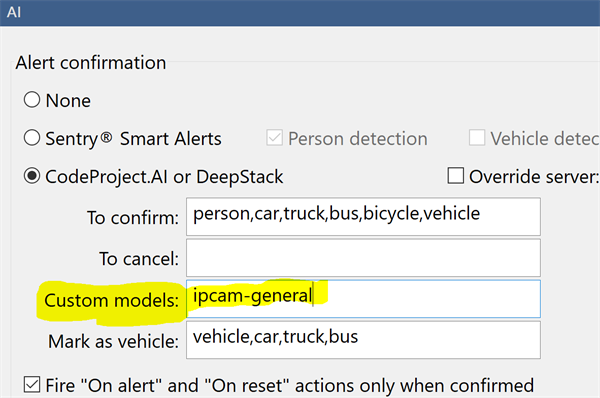
Here we've specified a specific model to use. The Blue Iris help file explains more about how this works, including inclusive and exclusive filters on the models it finds.
CodeProject.AI Server doesn't know about Blue Iris' folder, so it can't tell what models it may be expected to use, nor can it tell Blue Iris about what models CodeProject.AI server has available. Our API allows Blue Iris to get a list of the AI models installed with CodeProject.AI Server, and also to set the folder where these models reside. But Blue Iris doesn't, yet, use that API.
So we do a hack.
At install time we sniff the registry to find where Blue Iris thinks the custom models should be. We then make empty copies of the models that we have, and copy them into that folder. If the folder doesn't exist (eg you were using C:\Program Files\CodeProject\AI\AnalysisLayer\CustomObjectDetection\assets, which no longer exists) then we create that folder, and then copy over the empty files.
When Blue Iris looks in that folder to decide what custom calls it can make, it sees the models, notes their names, and uses those names in the calls. CodeProject.AI Server has those models, so when the calls come through we can process them.
Blue Iris doesn't use the models. It uses the list of model names.
If you have your own models in the Blue Iris folder
You will need to copy them to the CodeProject.AI server's custom model folder (by default this is C:\Program Files\CodeProject\AI\AnalysisLayer\ObjectDetectionYolo\custom-models)
If you've modified the registry and have your own custom models
If you were using a folder in C:\Program Files\CodeProject\AI\AnalysisLayer\CustomObjectDetection\ (which no longer existed after the upgrade, but was recreated by our hack) you'll need to re-copy your custom model into that folder.
The simplest solutions are:
- Modify the registry (Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Perspective Software\Blue Iris\Options\AI, key 'deepstack_custompath') so Blue Iris looks in
C:\Program Files\CodeProject\AI\AnalysisLayer\ObjectDetectionYolo\custom-models for custom models, and copy your models into there.
or
- Modify
C:\Program Files\CodeProject\AI\AnalysisLayer\ObjectDetectionYolo\modulesettings.json file and set CUSTOM_MODELS_DIR to be whatever Blue Iris thinks the custom model folder is.
cheers
Chris Maunder
|
|
|
|
|
This message has been flagged as potential spam and is awaiting moderation
|
|
|
|
|

and if dockers don't work
|
|
|
|
|
I receive several messages daily from BI with Error 500. I have installed Codeproject on Windows 11 and Ubuntu. The Coral TPU is an M2 so no USB! I have tried the last stable as well as the current beta always the same error... What can I do about it? It is very annoying...
|
|
|
|
|
In my experience, it probably means you're having BI send images too frequently. CPAI doesn't seem to queue the incoming jobs, and instead will abandon ones that it isn't ready for, sending back the error. So either decrease the model size, or increase the "analyze one image each [ ]" value and see if that helps. Also discussed on this thread:
CodeProject.AI Server: AI the easy way.[^]
|
|
|
|
|
I had set my Blue Iris AI settings to have a minimum confidence level of 40%, in the main settings. Apparently when CPAI detects anything with a confidence below this, it returns an error code 500.
I set the BI minimum to like 10% and now no more error 500s with the Coral. Apparently a lot of what it was detecting was around 30% confidence.
Not sure if this fixes the "numpy" errors with code 500 on the latest CPAI 2.8 release, because I've gone back to 2.6.2 because of the bugs in that release, but it worked for version 2.6.2 at least.
|
|
|
|
|
I know there are a lot of variables at play here, but just as another data point, lowering the confidence level did not have the same impact for me.
|
|
|
|
|
I'm working on training some of my own models for Blue Iris, and I'm wondering if there is any gain or loss of efficiency if I do one large model or several small. For example, if I trained three models; one model for people, one for vehicles, and one for animals, and then stacked them in the custom models like
objects:0,people.pt,vehicles.pt,animals.pt so they all ran. Versus one single model trained on people, vehicles, and animals.
My only real desire for splitting them up is that people and vehicles already have some fairly well trained models and a ton of open datasets. They would both be pretty easy to train once and probably forget about for a while. Whereas animals, depending on the animal, probably won't be and I'll be updating and retraining often.
It got me wondering if there is a computational tradeoff and I'm hoping someone here might have the answer.
|
|
|
|
|
There is roughly a doubling of runtime for each increase in model size within the family. (YOLOv8s vs YOLOv8m, for example.) So running two models is roughly the compute load of a single model the next size up. And that single larger model will, in theory, be more accurate. There doesn’t seem to be significant additional load for each additional class.
With that said, there is overhead in creating the dataset for training a single model with additional classes. Any given label needs > 10k examples for best performance. Often labels co-occur in an image and all of these images need to be appropriately labeled. This is more tricky the more images and classes you are dealing with. (Maybe there are model training tricks to get around this?)
modified 4 days ago.
|
|
|
|
|
I think I asked my question in a confusing way, I didn't mean large and small as in v8m and v8s. I was speaking more of the classes per model. In other words, I could have one yolov8s model named all.pt with 4 classes (cat, dog, car, truck). Or two yolov8s models, one named mammels.pt with cats and dogs and one named vehicles.pt with cars and trucks.
Same model sizes, same number of classes, the only difference is splitting this into two models with 2 classes each vs one model with 4 classes.
|
|
|
|
|
The two models take twice as long to run as a single model.
|
|
|
|
|
Here is a YOLOv8 model I just trained with data primarily from the COCO Dataset with just person, vehicle, and animal objects if you want to give it a try. My training results are also in the repo. GitHub - nmbgeek/ipcam-yolo-models[^]
|
|
|
|
|
Hello!
I have setup a camera at my bird feeder and have been monitoring it using Blue Iris. I am wondering if it would be possible to train the AI to identify what species a bird is when it comes to the feeder. I'm happy with what I have now with detection but would love to quantify what species I get. Thanks in advance for any help!
|
|
|
|
|
Short answer is yes. I'm working on some custom models myself. The longer short answer is:
- Collect a bunch of pictures of the birds
- Label all the different bird species
- Train a model on those
- Collect more, use the first model to help you label these
- Train a model
- Repeat until you get good results
The long answer of how to do it is multiple days of research and figuring out how everything fits together, what you need to label images, SDK's and API's for the assisted labeling, etc. It's not an easy process at this point that someone has put together a good app to do. That said, in the next couple of days I plan on documenting my current workflow. I'll try to remember to come back and post here, but if not, keep an eye on nullsec.us and GitHub - BeanBagKing/YOLO_Training: Scripts and Errata for YOLO Training[^]
|
|
|
|
|
|
I only have one module installed on my CPAI, Object Detection Coral 2.3.4. If I have it started, the autostart is set to true. If I restart my system, CPAI starts up fine, but the coral module is not running unless I go in and manually start it. If I check the info before starting it, the autostart is set to false. In Blue Iris, I have Auto start/stop with Blue Iris unchecked.
Blue Iris 5.9.6.4
CodeProject 2.6.5.0
|
|
|
|
|
CodeProject 2.6.5.0 has an issues with saving settings CodeProject 2.8 fixes the issue.
|
|
|
|
|
I installed 2.8 and it fixed the issue. Thanks for your help, Mike!
|
|
|
|
|
I installed version 2.1.1 (2024-06-21) and I did not use download cache.
I receive the following error when I press start, and OCR aborts. System setup below.
Am I doing something wrong?
07:26:18:Update OCR. Setting AutoStart=true
07:26:18:Restarting Optical Character Recognition to apply settings change
07:26:18:
07:26:18:Module 'Optical Character Recognition' 2.1.1 (ID: OCR)
07:26:18:Valid: True
07:26:18:Module Path: <root>\modules\OCR
07:26:18:Module Location: Internal
07:26:18:AutoStart: True
07:26:18:Queue: ocr_queue
07:26:18:Runtime: python3.9
07:26:18:Runtime Location: Local
07:26:18:FilePath: OCR_adapter.py
07:26:18:Start pause: 1 sec
07:26:18:Parallelism: 0
07:26:18:LogVerbosity:
07:26:18:Platforms: all,!windows-arm64
07:26:18:GPU Libraries: installed if available
07:26:18:GPU: use if supported
07:26:18:Accelerator:
07:26:18:Half Precision: enable
07:26:18:Environment Variables
07:26:18:MIN_COMPUTE_CAPABILITY = 6
07:26:18:MIN_CUDNN_VERSION = 7
07:26:18:
07:26:18:Started Optical Character Recognition module
07:26:19:OCR_adapter.py: Using PIL for image manipulation (Either OpenCV or numpy not available for this module)
07:26:19:OCR_adapter.py: Traceback (most recent call last):
07:26:19:OCR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\OCR\OCR_adapter.py", line 12, in
07:26:19:OCR_adapter.py: from OCR import init_detect_ocr, read_text
07:26:19:OCR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\OCR\OCR.py", line 10, in
07:26:19:OCR_adapter.py: from paddleocr import PaddleOCR
07:26:19:OCR_adapter.py: ImportError: cannot import name 'PaddleOCR' from 'paddleocr' (unknown location)
07:26:19:Module OCR has shutdown
07:26:19:OCR_adapter.py: has exited
---
System Setup + Coral dual TPU
---
Server version: 2.6.5
System: Windows
Operating System: Windows (Microsoft Windows 11 version 10.0.22631)
CPUs: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz (Intel)
1 CPU x 6 cores. 12 logical processors (x64)
GPU (Primary): Intel(R) UHD Graphics 630 (1,024 MiB) (Intel Corporation)
Driver: 30.0.100.9864
System RAM: 16 GiB
Platform: Windows
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
Runtimes installed:
.NET runtime: 8.0.8
.NET SDK: 8.0.304
Default Python: Not found
Go: Not found
NodeJS: Not found
Rust: Not found
Video adapter info:
Intel(R) UHD Graphics 630:
Driver Version 30.0.100.9864
Video Processor Intel(R) UHD Graphics Family
Microsoft Remote Display Adapter:
Driver Version 10.0.22621.3672
Video Processor
System GPU info:
GPU 3D Usage 30%
GPU RAM Usage 0
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
|
|
|
|
|
I have an NVIDIA GeForce GTX 1060 card in my Windows 10 machine. It is a gen 7 Intel core i7 processor.
Should I be able to just run the latest of all the CUDA stuff, including the CUDA drivers, CUDA Toolkit, cuDNN together with the latest NVIDIA graphics and the Microsoft .NET stuff? I am only using CP.AI for use with BlueIris.
Currently I am confused from the article where it lists restriction for CUDA with NVIDIA cards - "CodeProject.AI Server: AI the easy way." at:
CodeProject.AI Server: AI the easy way.[^]
and:
GPU Not Being Used · Issue #26 · codeproject/CodeProject.AI-Server · GitHub[^]
The article also mentions "Newer cards such as the GTX 10xx, 20xx and 30xx series, RTX, MX series are fully supported", so does this mean that my GTX 2060 card does not have these restrictions?
I have researched my card in the NVIDIA documentation. It seems that my card is "NVIDIA Pascal" with a "CUDA Compute Capability" of 6.0. according to the table at the link below, unless I am analysing this wrongly, I should be good for the latest versions such as "cuDNN 9.4.0 for CUDA 12.x, "CUDA Toolkit Version" and "NVIDIA Driver Version for Windows" etc.
Support Matrix — NVIDIA cuDNN v9.4.0 documentation[^].
Currently I tried to keep with mostly with the article recommended versions, but it doesn't seem to be working correctly. The versions I am running are:
CP.AI Server 2.6.5
NVIDIA CUDA - 11.8
NVIDIA Graphics driver - 560.81
CUDNN - 9.0
(Not sure how relevent the below Mircosoft .NET stuff is, if at all)
Microsoft .NET Runtime - 7.0.20.33717
Microsoft ASP.NET Core - 7.0.20.2469
Microsoft .NET SDK 7.0.410 - 7.4.1024.27207
One possible issue could be running cuDNN 9.0 instead of 8.9.4. I used 9.0 as it comes with a proper windows installer whereas 8.9.4 is either a rather messy manual install method or a batch file method install script (future maintenance issue risks such as uninstall etc) from the above CP.AI article link. I would rather install all the latest possible drivers, runtimes, SDK's though.
I can add CP.AI log files that might show what is going wrong, but can't see how to upload the file here (my first post).
I will just past the first part of the log here:
|
|
|
|
|
I think you should lower the graphics driver. I'm using Tesla P4 which is also Pascal.
Here is the data on my GPU:
GPU (Primary): Tesla P4 (8 GiB) (NVIDIA)
Driver: 538.15, CUDA: 11.8.89 (up to: 12.2), Compute: 6.1, cuDNN: 8.9
I remember that I was trying to update the driver version, and I think, above 538.15 the CPAI stops using my GPU for some reason. I kept it this specific setup because it works. This is the website where I got the driver "Drivers for NVIDIA RTX Virtual Workstation (vWS) | Compute Engine Documentation | Google Cloud[^]
I did not look into why the newer driver will make CPAI stop using the GPU, but I believe it has something to do with the compatibility of other elements such as cuDNN, CUDA, the modules in the ALPR or YOLO (Object Detection in general). They all need to be aligned in order to make it work.
I hope it helps.
|
|
|
|
|
Thanks, there seems to be dependency issues as you have also found. I don't even need anything as fancy as ALPR or Face Recognition. Just need basic YOLO object detection.
Also I wish I new how to attach my log file here. I tried to add it online here but doesn't take and reports my post as spam and warns my that I might annoy other users if the message is over a certain length (maybe less than 200 lines wich I don't think is excessive).
I really need to know what the issue is, or is it just that CP.AI is not keeping up with keeping compatible with the latest drives etc that it is dependent on. If there are intricate dependencies, then we need clear documentation for it. We don't want a try this or try that or try different combinations hoping all the planets will align.
I am hoping that a CP.AI developer or at least someone intimately familiar with the project code can explain why we are having these issues and what needs to be done on the CP.AI side to address it. And also add detailed documentation related to dependencies, particularly when utilising hardware such as an NVIDIA card to speed up the processing.
I will try adding a small portion of the log again below. It starts to go wrong I thing where I have shown the output in bold, which sows as red on the actual server hlog screen.
Quote: 12:30:36:System: Windows
12:30:36:Operating System: Windows (Microsoft Windows 10.0.19045)
12:30:36:CPUs: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz (Intel)
12:30:36: 1 CPU x 4 cores. 8 logical processors (x64)
12:30:36:GPU (Primary): NVIDIA GeForce GTX 1060 (6 GiB) (NVIDIA)
12:30:36: Driver: 560.81, CUDA: 11.8.89 (up to: 12.6), Compute: 6.1, cuDNN: 9.0
12:30:36:System RAM: 32 GiB
12:30:36:Platform: Windows
12:30:36:BuildConfig: Release
12:30:36:Execution Env: Native
12:30:36:Runtime Env: Production
12:30:36:Runtimes installed:
12:30:36: .NET runtime: 7.0.20
12:30:36: .NET SDK: 7.0.410
12:30:36: Default Python: Not found
12:30:36: Go: Not found
12:30:36: NodeJS: Not found
12:30:36: Rust: Not found
12:30:36:App DataDir: C:\ProgramData\CodeProject\AI
12:30:36:Video adapter info:
12:30:36: DisplayLink USB Device:
12:30:36: Driver Version 11.2.3146.0
12:30:36: Video Processor
12:30:36: Intel(R) HD Graphics 630:
12:30:36: Driver Version 23.20.16.4849
12:30:36: Video Processor Intel(R) HD Graphics Family
12:30:36: NVIDIA GeForce GTX 1060:
12:30:36: Driver Version 32.0.15.6081
12:30:36: Video Processor NVIDIA GeForce GTX 1060
12:30:36: DisplayLink USB Device:
12:30:36: Driver Version 11.2.3146.0
12:30:36: Video Processor
12:30:36: DisplayLink USB Device:
12:30:36: Driver Version 11.2.3146.0
12:30:36: Video Processor
12:30:36: DisplayLink USB Device:
12:30:36: Driver Version 11.2.3146.0
12:30:36: Video Processor
12:30:36:STARTING CODEPROJECT.AI SERVER
12:30:36:RUNTIMES_PATH = C:\Program Files\CodeProject\AI\runtimes
12:30:36:PREINSTALLED_MODULES_PATH = C:\Program Files\CodeProject\AI\preinstalled-modules
12:30:36:DEMO_MODULES_PATH = C:\Program Files\CodeProject\AI\src\demos\modules
12:30:36:EXTERNAL_MODULES_PATH =
12:30:36:MODULES_PATH = C:\Program Files\CodeProject\AI\modules
12:30:36:PYTHON_PATH = \bin\windows\%PYTHON_NAME%\venv\Scripts\python
12:30:36:Data Dir = C:\ProgramData\CodeProject\AI
12:30:36:Server version: 2.6.5
12:30:39:
12:30:39:Module 'Object Detection (YOLOv5 6.2)' 1.9.2 (ID: ObjectDetectionYOLOv5-6.2)
12:30:39:Valid: True
12:30:39:Module Path: <root>\modules\ObjectDetectionYOLOv5-6.2
12:30:39:Module Location: Internal
12:30:39:AutoStart: True
12:30:39:Queue: objectdetection_queue
12:30:39:Runtime: python3.7
12:30:39:Runtime Location: Shared
12:30:39:FilePath: detect_adapter.py
12:30:39:Start pause: 1 sec
12:30:39:Parallelism: 0
12:30:39:LogVerbosity:
12:30:39:Platforms: all,!raspberrypi,!jetson
12:30:39:GPU Libraries: installed if available
12:30:39:GPU: use if supported
12:30:39:Accelerator:
12:30:39:Half Precision: enable
12:30:39:Environment Variables
12:30:39:APPDIR = <root>\modules\ObjectDetectionYOLOv5-6.2
12:30:39:CUSTOM_MODELS_DIR = <root>\modules\ObjectDetectionYOLOv5-6.2\custom-models
12:30:39:MODELS_DIR = <root>\modules\ObjectDetectionYOLOv5-6.2\assets
12:30:39:MODEL_SIZE = Medium
12:30:39:USE_CUDA = True
12:30:39:YOLOv5_AUTOINSTALL = false
12:30:39:YOLOv5_VERBOSE = false
12:30:39:
12:30:39:Started Object Detection (YOLOv5 6.2) module
14:15:04:Response rec'd from Object Detection (YOLOv5 6.2) command 'detect' (...64a7a1) ['No objects found'] took 4784ms
14:15:04:Object Detection (YOLOv5 6.2): Detecting using actionnetv2
14:15:04:Response rec'd from Object Detection (YOLOv5 6.2) command 'detect' (...06ba2f)
14:15:04:Object Detection (YOLOv5 6.2): [NotImplementedError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 140, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 715, in forward
max_det=self.max_det) # NMS
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 942, in non_max_suppression
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torchvision\ops\boxes.py", line 41, in nms
return torch.ops.torchvision.nms(boxes, scores, iou_threshold)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\_ops.py", line 442, in __call__
return self._op(*args, **kwargs or {})
NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'torchvision::nms' is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
CPU: registered at C:\Users\circleci\project\torchvision\csrc\ops\cpu\nms_kernel.cpp:112 [kernel]
QuantizedCPU: registered at C:\Users\circleci\project\torchvision\csrc\ops\quantized\cpu\qnms_kernel.cpp:124 [kernel]
BackendSelect: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\BackendSelectFallbackKernel.cpp:3 [backend fallback]
Python: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\PythonFallbackKernel.cpp:140 [backend fallback]
FuncTorchDynamicLayerBackMode: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\functorch\DynamicLayer.cpp:488 [backend fallback]
Functionalize: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\FunctionalizeFallbackKernel.cpp:291 [backend fallback]
Named: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\NamedRegistrations.cpp:7 [backend fallback]
Conjugate: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\ConjugateFallback.cpp:18 [backend fallback]
Negative: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\NegateFallback.cpp:18 [backend fallback]
ZeroTensor: registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\ZeroTensorFallback.cpp:86 [backend fallback]
ADInplaceOrView: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:64 [backend fallback]
AutogradOther: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:35 [backend fallback]
AutogradCPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:39 [backend fallback]
AutogradCUDA: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:47 [backend fallback]
AutogradXLA: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:51 [backend fallback]
AutogradMPS: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:59 [backend fallback]
AutogradXPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:43 [backend fallback]
AutogradHPU: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:68 [backend fallback]
AutogradLazy: fallthrough registered at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\core\VariableFallbackKernel.cpp:55 [
...
modified 5 days ago.
|
|
|
|
|
^^ Basically what the previous poster said on the NV drivers. I'm also running BI on a WIN 10 machine, I7-8086 & RTX 2060 Super. I rolled the driver all the way back to 516.94 as it's the last version the CPAI crew says they can guarantee is compatible.
|
|
|
|
|
Appreciate hearing your experience on this.
I can play around with versions and see what works, but the reason I posted here was to understand the reason for the compatibility issue.
Do the CP.AI developers just not have the resources or time or maybe maybe is too difficult a task in making their software compatible for the latest drivers and runtime software that it is defendant on?
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









