
Simple Approach to Voronoi Diagrams
4.99/5 (42 votes)
Discussion of simple variants of Voronoi diagram
Layout
- Introduction
- Boundary-based Voronoi diagram
- Point location query
- The idea of a simple variant
- Brute force method
- Grid method
- Inverted list
- Computational complexity
- Update operations
- More advanced variants of Voronoi diagrams
- C++ implementation
- Visualization of the Voronoi diagram and the distance transform
- Performance test
- Using C++ code
- Comparison with C# implementation
- Delaunay Triangulation
- References
- History
Introduction
The Voronoi diagram (see Figure 1) is a fundamental geometric structure that has numerous applications. For a more detailed description, see the article in Wikipedia [1] and references there.

Unfortunately, the efficient programming representation of a Voronoi diagram requires quite complex data structures. The high cost of development and maintenance of these data structures is a serious obstacle to take advantage of this powerful mathematical concept in practice.
Here, we discuss an affordable and effective Voronoi diagram using interchangeable STL containers. The main advantages of this approach are the simplicity of the representation, the low cost of development and maintenance, and the adaptability to a wide range of user algorithms. The benefits come at the expense of the performance, which is, nevertheless, much better than that of the brute force approach. The suggested variant of a Voronoi diagram should be useful for the fast development of algorithms that require the facilities of a Voronoi diagram and for the development of advanced and more efficient representations of a Voronoi diagram.
Boundary-Based Voronoi Diagram
By definition, the Voronoi diagram represents a sub-division of the two dimensional space into regions induced by an input set of points, which are called sites in traditional terminology. Each region has a polygonal boundary that contains all points of the plane nearest to the region site. These regions are also called Voronoi cells.

The widely used boundary-based representations of a Voronoi diagram, such as shown in Figure 2, store sets of sites, cells, edges and vertices. The complexity of these representations is associated not only with the data sets, but also with the need to support adjacency relationships between elements of different types of a representation. For example, an edge must be linked to previous and next edges in a boundary of a cell and additionally, the edge must store at least one link to the cell enclosed by the boundary. These representations are useful for the efficient traversal of a Voronoi diagram and the computation of parameters of Voronoi cells, such as area and perimeter.
Point Location Query
One of the main facilities of a Voronoi diagram required in applications is the algorithm for planar point location, which looks for a given query point a cell that contains the point. The point location problem is of significant importance. Many types of specific problems, which arise in practice, can be reduced to the point location problem. A typical example is the task that involves computing the number of customers who live in the area of a shopping center.
Despite the rich data set, the boundary-based representations do not offer anything better than a search with linear running time. One method applies the test point in a polygon to Voronoi cells. Another method finds the nearest site through the computation of the distance from a query point to each site. For efficient search operations with logarithmic running time, the representation of a Voronoi diagram should use spatial indexing based on either an R-tree or a directed acyclic graph (DAG). The development and integration of yet another advanced data structure makes the implementation and maintenance of an efficient Voronoi diagram quite challenging and costly.
The Idea of a Simple Variant
The idea of a practical variant of a Voronoi diagram is to reduce the representation complexity by storing and using the smallest possible number of data sets. In the proposed minimal variant, a Voronoi diagram is represented by a set of sites only. The second element of this representation is an algorithm of the nearest neighbor search. This algorithm is designed to support the facilities of a Voronoi diagram: point location, finding the neighbors of a site and the construction of the boundary of a cell. If the nearest neighbor search has a simple implementation, this approach delivers the main benefit of this representation of a Voronoi diagram - the low cost of development and maintenance. Another benefit of this variant is the minimum space requirement.
Brute Force Method
In the early stages of development, it is reasonable to consider and implement the brute force variant of a Voronoi diagram. It is based on the simple algorithm that calculates the distance between a query point and each Voronoi site and finds the site with the first minimum distance. The ease of implementing the brute force variant comes at the expense of the efficiency of operations required in user algorithms. The method has linear running time. It is too slow for large data sets.
The main question for the simple representation of a Voronoi diagram is whether it is possible to improve the efficiency of the nearest neighbor search without the development of complex spatial data structures required for point location query.
Grid Method
The inefficiency of the brute force approach can be addressed by the popular grid method. The simplest variant of this method builds equally sized square cells. Each grid cell stores a list of points it contains.
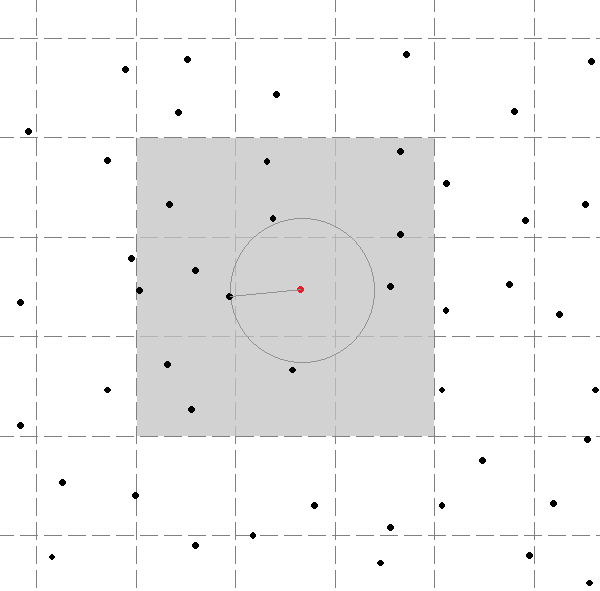
The search starts from a cell that contains a query point and continues in cells adjacent to visited cells (see Figure 3). The search stops when the distance between a query point and a closest unvisited cell becomes greater than the minimum distance between the query point and a point in the processed data sub-set.
The grid method is significantly simpler than a method based on a spatial data structure, but it is not completely trivial and has a number of limitations. This method provides the best performance, when the distribution of the spatial data is uniform. The optimal size of a cell depends on the density of the data. The performance of this method degrades, when a grid has too many empty cells or when the average number of points in one cell becomes too large. Even if the distribution of the spatial data is uniform, the grid cells must be rebuilt to avoid loss of performance as the number of points in the spatial data set varies. The re-build operation is the major disadvantage of the grid method. It complicates the implementation and can cause performance degradation of user algorithms.
Inverted List
In this article, we will focus on the method of "inverted list" or "inverted file", which has a number of attractive features. This is one of the simplest methods from the implementation perspective. It is slightly more difficult than the brute force method, but it is simpler than the grid method and spatial indexing. In terms of performance, this method delivers quite reasonable improvement compared to the brute force method, although it cannot compete with methods using spatial index structures. Unlike the grid method, this method does not require a rebuild operation as the spatial data set grows or shrinks.
The method of inverted list is based on an ordered data set. It imposes an order on elements using the values of one of the attributes. For a set of two dimensional points, this requirement implies that the set of Voronoi sites can be sorted by X-coordinate (or Y-coordinate) of a point. However, in computational geometry, a more suitable option is to use lexicographic ordering.
The key observation that helps develop the new more efficient nearest neighbor search algorithm is that the lexicographic order of sites significantly reduces the range of search. As the following Figure 4 shows, the order allows the algorithm to avoid the search in regions, which are quite distant from a query point. Thus, unlike an unordered set, there is no need to compute the distance between a query point and each site. This fact explains the performance gain over the brute force method.

The improved nearest neighbor search algorithm has two stages. First, the algorithm finds a given query point an initial position in the set of sites. This position provides two sites whose X-coordinates form the range, which contains the X-coordinate of the query point. Then, the initial position is used to start two sequential searches in increasing and decreasing lexicographic order of sites. A search moves forward or backward and computes the distance between a query point and a current site. Each search stops when the absolute value of the difference between X-coordinates of a query point and a current site is greater than the computed minimum distance from the query point to a site in the processed subset.
The following C++ code illustrates the computation of the minimum distance using forward search of this algorithm:
while ( it_cur != it_end )
{
dist_cur = Distance ( *it_cur , pnt ) ;
dist_x = fabs( it_cur->X() - pnt.X() ) ;
if ( dist_cur < dist_min )
dist_min = dist_cur ;
if ( dist_x > dist_min )
break ;
++it_cur ;
}
This piece of code is only slightly longer than a typical implementation in the brute force method:
for ( ; it_cur != it_end ; ++it_cur )
{
dist_cur = Distance ( *it_cur , pnt ) ;
if ( dist_cur < dist_min )
dist_min = dist_cur ;
}
Computational Complexity
The performance of this algorithm is determined by the second stage of processing. On average, the running time of each sequential search is proportional to the square root of the number of sites. The search for an initial position is more efficient. In an ordered container, it has logarithmic running time in the worst case.
In theory, square root running time does not look quite impressive. However, compared to the brute force search, the discussed algorithm offers a performance improvement by orders of magnitude. For instance, when the number of Voronoi sites is 10,000, this algorithm is 100 times faster than linear search.
In the context of a Voronoi diagram, one of the important advantages of the discussed nearest neighbor search algorithm is efficient support for rectangular range queries. It can be used to find all of the neighbors of a site and construct its cell in one pass of the algorithm.
Another advantage of this algorithm is that a set of two dimensional points can be ordered by various methods and comparison operations. This fact is useful to optimize performance of the nearest neighbor search in specific applications. The optimization can be achieved by sorting point sites using projected distances onto the line, which is the most suited for a given distribution of sites.
Update Operations
So far, we have discussed simple algorithms that do not modify a Voronoi diagram. Many real world applications require not only traversal and search, but also insertion and erasure operations that change the number of sites and cells, and modify boundaries of cells. The performance and ease of implementing update operations are important in such applications.
In computational geometry, efficient update operations on spatial data structures are particularly challenging. They work well only with the specific input, which assumes certain types of data distribution and the order of insertions and erasures. Any deviation from the ideal input leads to balance and performance problems. It is not an unusual situation that an update operation invalidates an invariant and an algorithm must re-build data sets of a representation.
The advantage of the proposed simple variant of a Voronoi diagram is that it completely avoids all of these difficulties. In order to obtain required efficient update operations, it is sufficient to choose a suitable data structure that represents a set of sites. Balanced search trees are good candidates for this task. In addition to efficient search and traversal, they support insertion and erasure with logarithmic running time.
More Advanced Variants of Voronoi Diagrams
Although the simple variant of a Voronoi diagram does not store detailed space partition data sets of cells and edges, it can be used in many applications of this geometric structure. The nearest neighbor search enables the construction of the boundary of a Voronoi cell by finding all of the neighbors of its site. Obviously, the computation of the perimeter and area of a cell is less efficient compared to boundary-based Voronoi diagram, but the performance of this method can be acceptable for some applications.
Another reasonable option is to use the discussed nearest neighbor search in a boundary-based representation of a Voronoi diagram. This simple algorithm offers an alternative to the spatial indexing method using complex data structures, such as a tree or a DAG. However, it requires that a set of sites be stored in an ordered container.
C++ Implementation
The simple variants of a Voronoi diagram can be implemented in many programming languages. The C++ standard library offers powerful facilities that enable the development of many programming solutions with the minimal effort. We will take advantage of the STL containers and algorithms to implement the discussed ideas.
The performance of the simple variants of a Voronoi diagram depends primarily on the data structure that represents a set of sites. The STL has several types of basic data structures that support unified interfaces of containers and iterators. This fact suggests that the optimal programming solution should take advantage of the interchangeable standard containers in the form of a generic algorithm. It can be parameterized on types of containers, iterators and supporting algorithms.
Each variant of a Voronoi diagram has specific requirements that determine the simplicity and ease of implementation. The discussed simple variants of a Voronoi diagram differ in how sites are stored in a set and how they can be accessed.
The brute force variant of a Voronoi diagram is particularly attractive due to minimal requirements. This variant does not place any restriction on how data are stored in a container. It only requires that a container provides access to each element. In C++11, any standard container that provides a forward iterator meets these requirements. Thus, all of the following containers are suitable for the brute force variant of Voronoi diagram: set, unordered_set, vector, deque, list and forward_list.
The representation of a Voronoi diagram based on an inverted list is slightly less trivial. This variant has the following requirements. It assumes that a container, which represents a set of Voronoi sites, stores the data in lexicographic or sorted order. The container must provide an efficient algorithm to find an initial search position in the set of sites and must support forward and backward sequential searches.
When performance matters, the variety of suitable STL containers is significantly reduced compared to the brute force variant. Here are some reasons why specific STL containers are not suitable for the implementation of the improved variant of a Voronoi diagram. A singly linked list (std::forward_list) does not provide efficient access to a previous element. A doubly linked list (std::list) is inefficient for finding an initial search position. A container based on a hash table (std::unordered_set) does not maintain lexicographic or sorted order of sites.
The choice of acceptable efficient containers is essentially determined by the first stage of the nearest neighbor search that finds an initial position in an ordered set of sites. There are two types of data structures that efficiently support the required operation. The arrays and array-based containers provide binary search, which has logarithmic running time. In the C++ standard library, the most suitable container of this type is std::vector. The library function std::lower_bound() implements the required efficient search for an initial position in an ordered container with random access iterators. The same logarithmic running time can be obtained with balanced search trees. The std::set container is normally based on a red-black tree and supports the needed search through the member function std::set::lower_bound().
In C++, std::vector is the default standard container, since it offers the best performance for many types of applications. However, it is not always the best choice for user algorithms that require frequent update operations on a Voronoi diagram. The performance of such algorithms can drop quite significantly due to linear running time of insertion and erasure operations, which is significantly worse than square root running time of the nearest neighbor search. The std::set container that offers update operations with logarithmic running time can deliver much better performance.
In complex user algorithms, the choice of the most efficient standard container is not obvious. The analysis of computational costs of operations is quite difficult and ineffective. A generic algorithm using interchangeable STL containers provides a simple practical method for both tuning performance and selecting a container. The measurement of the running time of a user algorithm for each acceptable container enables one to find the suitable container.
In light of the fact that the STL is a general-purpose library only, the facilities offered by the simple representation of a Voronoi diagram using standard containers are quite impressive. It is particularly interesting that efficient support for update operations is obtained basically for free. With the parameterized solution, it only requires changing the template argument from std::vector to std::set. This strength comes from the key design principle that the standard library provides a wide variety of interchangeable containers with different performance guarantees for interface operations.
At the same time, it is impossible for the standard containers using basic data structures to deliver the best performance in all types of applications. For example, the STL provides limited support for the solutions to problems that require high efficiency of both random access to elements and update operations. The standard containers with random access iterators have linear running time of insertion and erasure operations, whereas the containers with fast update operations support only bidirectional iterators. These limitations can be addressed by applying the key STL design principle mentioned before. The performance of an algorithm can be improved through new efficient data structures. In generic algorithms, these data structures should be used as STL extensions, which support interfaces of the standard containers and iterators.
Visualization of the Voronoi Diagram and the Distance Transform
The visualization of a Voronoi diagram is important in practical applications. Despite the discussed simple representation does not provide the boundaries of cells, it allows one to easily draw a Voronoi diagram on a bitmap. This is an example of an application of the Voronoi assignment model. The drawing method assigns a unique color to each site and then applies the nearest neighbor search algorithm in order to set the color of each pixel. The image of a Voronoi diagram shown in Figure 1 has been obtained using this method.
The distance transform [2] is closely related to a Voronoi diagram (see Figure 5). It calculates the distance between a query point and its nearest site. The distance transform can be visualized by mapping the distance value to the brightness of each pixel, which is used as a query point. This method produces a grayscale image of the distance transform, such as shown below.

Performance Test
The performance of the discussed representation of a Voronoi diagram has been measured using the algorithm that emulates the computation of a distance transform. The choice is explained by the simpler implementation of the distance transform compared to that of a Voronoi diagram. The test generates a random set of two dimensional points that represent sites of a Voronoi diagram and fill a specified rectangle. Each container stores the sites in lexicographic order to guarantee square root computational complexity of the nearest neighbor search. The test measures the total running time required to calculate the distance from each point inside the specified rectangle to its nearest site.
The running times of this test show that std::vector has the best performance. The reason for this is that the contiguous arrangement of elements in this container provides fast random and sequential access to elements required for the test. The computation of a distance transform allows us to measure the performance gain offered by the search in an ordered set compared to the brute force algorithm. On a Windows 7 system, the running time improves by a factor of 2.9 for N = 100 and by a factor of 28 for N = 10,000 points in std::vector. Thus, the performance gain increases by a factor about 10, when N increases by a factor of 100. This result is consistent with the square root estimate that follows from asymptotical computational complexities of these two algorithms.
Using C++ Code
The code has been developed for C++03 compilers. In a C++11 compiler, boost::chrono can be replaced by std::chrono.
The standard sequence containers (std::vector, std::list and std::deque) have been included in the sample algorithms to demonstrate how to deal with the container specific code in generic algorithms and to allow a user to compare the performance of various data structures. These containers are not safe in applications, which modify a Voronoi diagram. The update operations violate two invariants: the order and uniqueness of elements in a container. The issue can be addressed with STL extensions, such as array-based Boost::flat_set, that support the interface of std::set. Such a container will improve the solution safety and provide the same efficiency as std::vector.
The code in the namespace VoronoiDemo avoids issues related to numerical errors by using the exact integer type for the X and Y coordinates of two dimensional points. The calculation of the distance between two points has been replaced with the calculation of the squared distance, which also takes advantage of the exact integer type.
Comparison with C# Implementation
The nearest neighbour search developed in C++ delivers quite good performance improvement for small amount of code. This fact makes the algorithm interesting for comparison with its matching C# implementation.
Porting the code from C++ to C# is not too challenging, but there is a subtle implementation detail. C# algorithms use tri-state comparison, whereas standard algorithms in C++ assume that a container data type supports strict weak ordering (simply put, operator less). C# code in the attached file addresses this issue by providing the function AlgoOrderedList.LowerBound() equivalent to std::lower_bound() in C++. In other aspects, C# implementation is simpler than that in C++. In particular, it is not parameterized on the type of a container. It has been written for List only, which means that this demo is not directly suitable for the representation of a mathematical set. The benefit of this C# variant is that it allows us to compare its running times against the fastest C++ variant based on std::vector.
The C++ and C# algorithms have been tested on the same desktop computer with AMD Ryzen 7 PRO 3700 processor, 16GB of RAM and Windows 10 Pro operating system. The attached code supports the measurements of the computation time in milliseconds with Stopwatch in C# and chrono::high_resolution_clock in C++. The executable code was generated in Visual Studio 2019 using console applications with default project settings.
Testing the brute force algorithm confirms that it has linear computational complexity (refer to the table below). C++ algorithm is about 3 times faster than C# algorithm.
| N | 100 | 1,000 | 10,000 |
| C++ | 88 | 830 | 8,180 |
| C# | 270 | 2,900 | 28,700 |
For the algorithm based on the search on an ordered dataset (see the next table), the asymptotical square root complexity is reached at N about 10,000.
| N | 100 | 1,000 | 10,000 | 100,000 |
| C++ | 22 | 58 | 146 | 430 |
| C# | 100 | 240 | 625 | 2,040 |
In this test, the advantage of C++ looks even more impressive. It outperforms C# by a factor close to 5. Despite this fact, the choice of the C# variant of this algorithm is certainly worthwhile in applications. As we can see from comparing running times for N >= 1,000, it is significantly faster than brute force search, including its C++ variant. This test is yet another illustration of the principle that brute force algorithms should be avoided when the size of a dataset can increase by orders of magnitude.
Delaunay Triangulation
This section explains why the Delaunay triangulation is beyond the scope of this article and why its discussion was omitted from the first version of this article.
A triangulation of a set of two dimensional points represents a planar sub-division into a set of triangles. For a given set of points, there exist many triangulations. A Delaunay triangulation is, in some aspects, the most perfect one and it is the dual graph of a Voronoi diagram (see Figure 6). A vertex of a Delaunay triangulation corresponds to a Voronoi cell and its site. The connectivity of vertices in a Delaunay triangulation is defined by boundary edges of Voronoi cells. The Delaunay triangulation has a number of interesting properties that makes it useful in a wide range of practical applications [3].

The similarity of a planar sub-division does not mean that methods, which work well for a Voronoi diagram, can be directly applied to a Delaunay triangulation. In the context of this article, the main distinctive feature of the Delaunay triangulation is that it is a planar graph. An efficient representation of a graph requires that a vertex stores a list of edges to neighbors. For this reason, the Delaunay triangulation has the same level of complexity as boundary-based variants of the Voronoi diagram. The discussed simple representation of a Voronoi diagram based on a set of sites and the nearest neighbor search does not meet this requirement for a graph representation. The Delaunay triangulation is a more complex geometric structure than the Voronoi diagram.
References
- http://en.wikipedia.org/wiki/Voronoi_diagram
- http://en.wikipedia.org/wiki/Distance_transform
- http://en.wikipedia.org/wiki/Delaunay_triangulation
History
- 4th March, 2015: Initial version