
SortedSplitList - An Indexing Algorithm in C#
4.96/5 (38 votes)
A list for managing tens of millions of objects in your application.
The French version of this article is available at this link.
Introduction
A few years ago, I developed the storage part of a NoSQL DBMS technology.
The server should store data in the form key / value on the disk, and be able to manage various aspects such as transactional system, replication, lock, repair corrupt segments, compaction and counters on the number of data in the database, wasted space ...
To overcoming all these features, the data should be recorded with a header block, and all of these blocks should be placed in several indexes with multiple criteria.
Initially, I used the standard tools provided by the NET
Framework: SortedList, Dictionary, SortedDictionary, but soon, malfunctions were found during load testing.
It was therefore necessary to create my own list to help make a server that can handle very large amounts of data, fast, with low memory usage, with the ability of indexing data sets by sorting several keys.
Background
Before starting to present my solution, I will explain the problem.
For this, we observe the behavior of different algorithms offered by the. NET Framework while trying to inject their 10 million objects with random data.
During these tests, I will collect the amount of memory used and the time spent for each tool tested.
This is the object that will be used to fill our indexes:
public class DataObject
{
private static readonly Random Random = new Random();
private readonly Guid _id = Guid.NewGuid();
private readonly DateTime _date =
new DateTime(Random.Next(1980, 2020),Random.Next(1,12), Random.Next(1,27));
private readonly int _number = Random.Next();
public Guid ID
{
get { return _id; }
}
public DateTime Date
{
get { return _date; }
}
public int Number
{
get { return _number; }
}
}
A factory will generate as much as desired instance in our test:
public static class DataFactory
{
public static List<dataobject> GetDataObjects(int number)
{
var result = new List<dataobject>();
for(int i = 0; i < number; i++)
result.Add(new DataObject());
return result;
}
} You will notice that the factory directly returns a list instead of an enumeration. This is for not affecting the time calculations with the generation time of each object.
We will also establish a performance counter to collect data on the time and amount of memory used by the algorithm:
public class PerfCounter : IDisposable
{
private readonly Stopwatch _stopwatch = new Stopwatch();
private readonly long _currentMemoryUsage = Process.GetCurrentProcess().WorkingSet64;
private readonly string _filePath;
public PerfCounter(string filePath)
{
if( string.IsNullOrEmpty(filePath) )
throw new FileNotFoundException();
string directoryPath = Path.GetDirectoryName(filePath);
if( string.IsNullOrEmpty(directoryPath) )
throw new FileNotFoundException();
Directory.CreateDirectory(directoryPath);
if (!File.Exists(filePath))
File.AppendAllText(filePath, "Memory\tTime\r\n");
_filePath = filePath;
_stopwatch.Start();
}
public void Dispose()
{
_stopwatch.Stop();
GC.Collect();
long memory = Process.GetCurrentProcess().WorkingSet64 - _currentMemoryUsage;
File.AppendAllText(_filePath, _stopwatch.Elapsed.ToString() + "\t" + memory + "\r\n");
}
}
Now we have the needed tools to start our analysis, kick off with the first tool available.
SortedList
A SortedList is a collection of key / value pairs
sorted by key which is accessible by key and by index.
We will inject 1 million random objects using the following method:
private static void TestSortedList()
{
var sortedList = new SortedList<Guid, DataObject>();
for (int i = 0; i < 10; i++) {
List<DataObject> datas = DataFactory.GetDataObjects(100000);
using (var counter = new PerfCounter("c:\\Indexation\\SortedList.txt")) {
foreach (DataObject dataObject in datas) {
sortedList.Add(dataObject.ID, dataObject);
}
}
}
}
Here is the results of this little program:

Total insertion time for 1 million items : 785 seconds
Total memory to index 1 million items : 54 MB
As you can see, the inclusion in a SortedList is extremely slow because it took us 13 minutes to insert one million objects. I call to mind that our goal is to manage tens
of millions of objects, it is unthinkable to use this method.
Why SortedList is so slow?
For a very simple reason: a list is an array stored in a contiguous elements.
![]()
When you add an item to the end of the list, it just stacked like this:
![]()
This provides no cost to the algorithm. This is also why with performance testing on nonrandom data, you can believe that the inclusion in a list is extremely fast because the system adds the data in the list.
By cons, if you want to insert an element in the middle of the list (this is a sorted list), we have no choice to shift the entire block of higher elements to make room for new data, and then pick up this series at the end of the list.

Obviously, this is very costly because more are the elements in the list, and more the operation of copy / paste will be long, especially when it will insert elements at the beginning of the list.
Here, the equation for the trendline on the insertion time is ![]()
Thus, importing 10 million random elements in a SortedList takes theoretically 36 hours!
Dictionary
A dictionary is a collection of generic objects of type key / value that is based on the Hashtable algorithm.
As before, we will get the execution time and the amount of memory used by the algorithm for 10 million objects.
Here is the result:

Total insertion time for 10 million items: 2 seconds
Total memory to index 10 million items: 638 MB
The insertion time is much better, but the memory usage is too high.
Imagine if we want to create five indexes with 20 bytes for each object, the weigh for all elements will be 200 MB while the algorithm would take 3 GB and 190 MB of RAM!
Why hashtable takes so much space?
When adding an item in a hashtable, a key is used to calculate a relatively unique number (called hashcode). I say "relatively" because there may be two different keys is the same hashcode, this is called a collision.
To overcome this problem, a hashtable has internally a two-dimensional table (called buckets) that contains entries in the form of structures in several parameters. these are the entries that take up much space.
Usually, an entry is composed of a hashcode, a key, a value and a pointer to the next element, because buckets are actually arrays of linked lists.

The interest of the whole structure is to store data intelligently indexed by hashcode.
Basically, the hashcode is subject to a modulo of the length of the bucket which gives the index where entry is stored. Once the index is known, a loop route all matching entries to compare all the keys and their hashcodes with the item to insert.
If the same key is found, the system will return an error.
If the same hash code is found while the key is different, a new entry is created in the linked list.
If you look at the graph, you can observe that at 6 million objects, memory do an exceptionally raise of 100%. I guess this had to be a pre-allocation in the bucket after a large number of collisions.
Thus, more are objects to index, higher the probability of collision is high, forcing the hashtable to allocate a lot of memory to maintain its level of performance. This technique is not recommended when you want to treat a very large number of objects!
SortedDictionary & SortedDictionary2
According to MSDN, the SortedDictionary class was designed to overcome the problem of insertion speed of a SortedList. Let's see what happens with our test system:

Total insertion time for 10 million items: 5 seconds
Total memory to index 10 million items: 612 MB

Total insertion time for 10 million items: 5 seconds
Total memory to index 10 million items: 649 MB
According to the results, you'll wonder why use a
SortedDictionary rather than just Dictionary? since with equivalent memory consumption, the Dictionary is twice as fast!
Here we come to a second dimension of our problem, indexing at different depths.
All our tests are based on a single key search, but there are cases where we want to sort objects by a combination of date, size and by id. If we wanted to do this with a simple Dictionary, we would have to implement it as follows:
Dictionary<DateTime, Dictionary<int, Dictionary<Guid, DataObject>>> index =
new Dictionary<DateTime, Dictionary<int, Dictionary<Guid, DataObject>>>(); As you can see, we imbricate three dictionaries. This not only adds complexity to the implementation level, but also the amount of memory used will be multiplied by 3, requires 2GB of RAM instead of 650MB of
SortedDictionary.
The SortedDictionary eliminates the problem with the mandatory implementation of a "comparer" that will allow it to do a binary search on a list of internal dictionary.
My Solution: SortedSplitList
On the same model as the previous tests, this is what gives the insertion of 10 million objects in a
SortedSplitList:
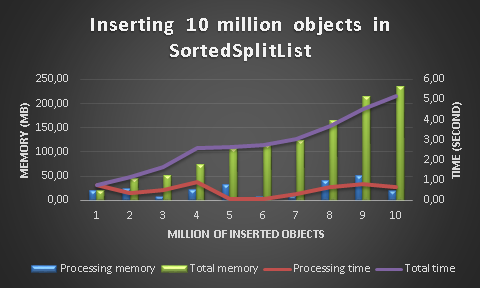
Total insertion time for 10 million items: 5 seconds
Total memory to index 10 million items: 235 MB
The algorithm takes as mush time as SortedDictionary for insertion, but it consume three times lower memory than Dictionary or SortedDictionary !
How It Works ?
To develop this algorithm, I tried to improve the speed of insertion for a standard SortedList.
As explained in the analysis of performance for the
SortedList, the slowness just appears when inserting an element at the beginning of a list. Indeed, the system must first remove all upper elements to element to be inserted, and then re-stacking thereafter.
For realizing the lost time to do this operation, just stack one hundred plates on top of each other, and then insert one into the eighteenth position.
The method is therefore not to work on a single list that can potentially be huge, but to work on several small lists rows:

Internal structure of the SortedSplitList
Suppose we want to insert the element 27. As a first step, we do a binary search on the set of lists to find one that will contain the element;

Search in the list to accommodate the new element
Once the resulting list, simply make a second binary search inside this one, and insert like a classic element sorted list:

Locating integration in the sub-list

Insert the new item.
With this simple method, the impact on the insertion time is greatly reduced while maintaining the advantage of optimal memory consumption!
Using the Code
To use a
SortedSplitList, you must first declare a "comparer" default object you want to index:
Object to index
public class TestObject
{
public int Id { get; set; }
public int Id2 { get; set; }
public DateTime Date { get; set; }
public string Data { get; set; }
}
Default comparer
public class CompareById : IComparer<TestObject>
{
public int Compare(TestObject x, TestObject y)
{
if (x.Id == y.Id)
return 0;
if (x.Id < y.Id)
return -1;
return 1;
}
}
Then create a new instance of SortedSplitList like this:
SortedSplitList<TestObject> sortedSplitList =
new SortedSplitList<TestObject>(new CompareById());
Once done, you can add, retrieve or remove items from the list by using the
Add(), Retrieve() or BinarySearch() and
Remove() RemoveAll() or Clear().
Regarding the Retrieve method, the first argument must be an object instance configured with the parameters on which you want to search.
For example, if I want to find a
TestObject whose identifier is 78 for the value of the Data field, I have to do it the following way:
var searchObject = new TestObject {Id = 78};
var foundObject = sortedSplitList.Retrieve(searchObject);
Console.WriteLine(foundObject != null ? foundObject.Data : "Data not found.");
The BinarySearch() method allows to retrieve the index of the item that is sought, giving the ability to browse the
SortedSplitList according to your needs.
To learn how to work with the object returned by the method BinarySearch (index), see on MSDN dealing with
BinarySearch() method on generic list.
Working with Records Stored in Multiple Criteria
Imagine our TestObject have a composite key of Date + Id. How to store and retrieve an element in a SortedSplitList?
To store items, it's easy. Simply define a default comparer as follows:
public int Compare(TestObject x, TestObject y)
{
int dateResult = x.Date.CompareTo(y.Date);
if (dateResult == 0) {
if (x.Id == y.Id)
return 0;
if (x.Id < y.Id)
return -1;
return 1;
}
return dateResult;
}
Thus, the Add() and Retrieve() methods allow you to work with your composite key elements.
Now, what to do if we want to know all the elements of a given date?
Seeing that allows
SortedSplitList provides access to a enumerator, a beginner in programming would be tempted to use the following method:
foreach (var testObject in sortedSplitListSortedById.Where
(a => a.Date == DateTime.Parse("2003/01/01")))
Console.WriteLine(testObject.Data);
This can work perfectly if your list contains few elements, but the performance of this line of code can be catastrophic if the list contains millions of objects.
The appropriate method in this case is to make a binary search with a specialized search for date compare, then browse through the items on the list in reverse to find the first. Once this is found, simply retrace the list in the right direction by returning only the items that correspond to the search criteria.
If all this sounds complicated to implement, the
PartiallyEnumerate() method may be useful to carry out this task. Here's how to use it.
First of all, we define a special look for the search by date, and only by date:
public class CompareByDate : IComparer<TestObject>
{
public int Compare(TestObject x, TestObject y)
{
return x.Date.CompareTo(y.Date);
}
}
Then we can call the PartallyEnumerate() method, passing it an object of comparison with the date we want, and comparer above:
foreach (var testObject in sortedSplitList.PartiallyEnumerate(new TestObject()
{ Date = DateTime.Parse("01/01/2003") }, new CompareByDate()) )
Console.WriteLine(testObject.Id);
With this method, the foreach will display all the ids Elements dated 01/01/2003 without taking several minutes if our list contains millions of objects.
Conclusion
Although the indexing provided by the .NET framework are more than enough for most needs software tools,
SortedSplitList can be very useful for treating a large volume
of objects in your application, it combines the optimizing memory of a SortedList, the speed of inserting a
SortedDictionary while giving the opportunity to work on multiple keys.
So you can easily index your data based on multiple criteria without fear of too quickly appear an
OutOfMemoryException.