
Building Resilient .NET Applications with Polly
5.00/5 (9 votes)
How to write resilient .NET applications ?
Introduction
Microservices are an architectural style that structures a software application as a collection of small, independent, and loosely coupled services. In a microservices architecture, the application is broken down into a set of independently deployable services, each representing a specific business capability. These services can be developed, deployed, and scaled independently, allowing for greater flexibility, maintainability, and scalability.
Nevertheless, this emerging paradigm brings forth certain challenges, particularly in the realm of overseeing distributed architectures and formulating effective responses when one of the microservices encounters performance issues. Frequently, these scenarios are initially disregarded at the project's outset, occasionally overlooked even as the application transitions to production. They are then hastily addressed, often during urgent or late-night situations prompted by user complaints.
Throughout this series, we will explore the adept handling of such issues using a robust library specifically designed for these challenges. We will delve into the implementation of practical use cases in C# with Azure Functions, observing how they respond when confronted with problems. Enter Polly.
The following textbook on this subject is a timeless classic and deserves a place on the shelf of every developer. It extends beyond resilience patterns and covers a myriad of expansive and general practical use cases.
This article was originally posted here.
What are Distributed Architectures?
Distributed architectures refer to a system design in which components or modules of a software application are distributed across multiple computers or servers, often geographically dispersed. Unlike a traditional monolithic architecture where all components are tightly interconnected and reside on a single platform, distributed architectures distribute the workload and functionality among various nodes in a network.
Common examples of distributed architectures include microservices architectures and their main goal is to enhance scalability, improve performance, and increase reliability by leveraging the capabilities of multiple interconnected systems. For a more in-depth exploration of all the challenges and intricacies associated with implementing microservices serverless architectures, we encourage the reader to refer to our dedicated post on the subject (How to implement a serverless architecture on Azure).
The figure below illustrates an example of a distributed architecture.

What Occurs in the Event That One of the Components Becomes Unresponsive?
At the risk of sounding like broken record, I'll say it again: expect failures.
Nygard Release It!: Design and Deploy Production-Ready Software
Continuing with the aforementioned example, what are the potential consequences if the Account service experiences a delay?
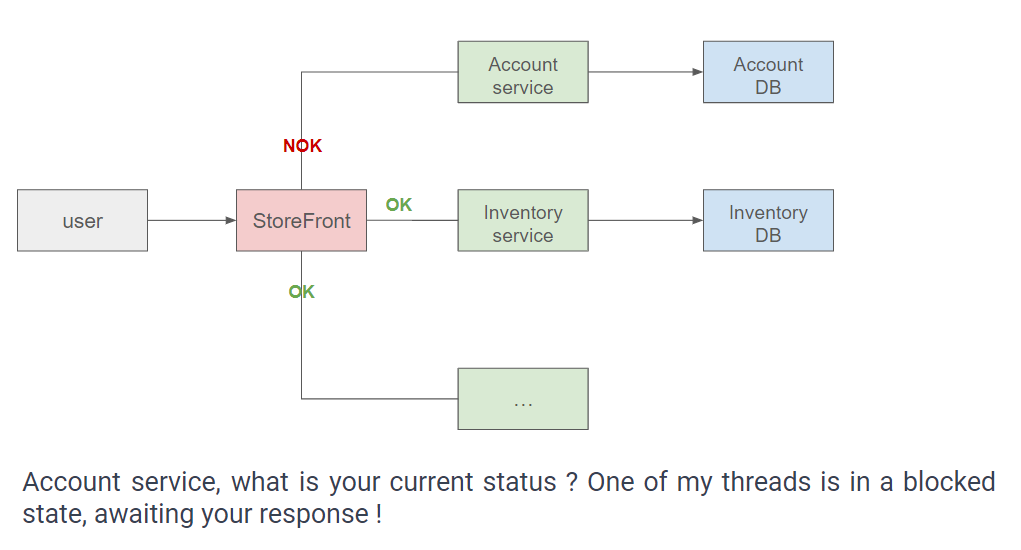
-
A user initiates an attempt to visit a page within the
StoreFrontapplication. -
Subsequently, the application allocates a new thread to handle this request and endeavors to establish communication with various services, including the Account service.
-
The Account service is unresponsive, so the thread tasked with processing the request becomes suspended, desperately awaiting a response from the server. Regrettably, it is unable to execute any other tasks during this period of delay.
-
When another user accesses the site, the application allocates a thread to manage the new request. However, a similar scenario unfolds as this thread also becomes suspended, attributable to the unresponsiveness of the Account service. The consecutive request is consequently affected by the service downtime.
-
This cycle persists repeatedly until no more threads are available to handle new requests. In certain cloud platforms, additional instances of the
StoreFrontapplication may be deployed as a workaround. However, they encounter identical issues, resulting in numerous servers awaiting responses, all with blocked threads. To exacerbate the situation, these servers incur charges from the cloud platforms, all stemming from the unavailability of a single service.
This type of issue can manifest even if the Account service is not the primary instigator, such as when the Account database experiences unresponsiveness.

Each time the Account service requires information from this database, it allocates a thread, which, in turn, becomes suspended due to the database failure. Consequently, all threads within the Account service become occupied, awaiting responses, leading back to the previous scenario where the Account service begins to hang.
These illustrations exemplify chain reactions and cascading failures, where a disruption in one layer initiates a corresponding disruption in a calling layer.
An obvious example is a database failure. If an entire database cluster goes dark, then any application that calls the database is going to experience problems of some kind. What happens next depends on how the caller is written. If the caller handles it badly, then the caller will also start to fail, resulting in a cascading failure. (Just like we draw trees upside-down with their roots pointing to the sky, our problems cascade upward through the layers.)
Nygard Release It!: Design and Deploy Production-Ready Software
What is the Issue at Hand, Precisely?
In our scenario, the issue emerges when one of the components experiences a breakdown. However, fundamentally, this situation arises whenever we need to access another resource within the platform or the farm. The moment multiple servers are involved in the process, as is common in distributed architectures, there is an increased risk of encountering complications. These potential failure points are identified as integration points: integration points are the myriad connections between two computers.
- An integration point can encompass a connection between a web application and a service.
- It can encompass a connection between a service and a database.
- It can encompass any HTTP request taking place within the application.
Distributed systems pose thus unique challenges related to communication, data consistency, fault tolerance, and overall system complexity. Effective design and implementation are crucial to harness the benefits of distribution while mitigating the potential challenges associated with it.
Fortunately, there are established patterns and best practices to mitigate such issues. Common data structures can be employed to circumvent challenges, and even more advantageous is the existence of a library where everything is pre-implemented, sparing the need for manual implementation. The next post will delve into the presentation of this library.
Installing the Environment
Deploying the Flawed Service
-
Create a new solution and add a new Azure Function project named
EOCS.Polly.FaultyServicein it.
-
Add a new class named FaultyService.cs for example and the following code to it.
public class FaultyService { public FaultyService() { } [FunctionName(nameof(GetNeverResponding))] public async Task<IActionResult> GetNeverResponding ([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { while (true) { } return new OkResult(); } }
Information
Indeed, this code lacks significant complexity, with its only noteworthy aspect being that the request never concludes.
- Add a new class named StartUp.cs and the following code to it:
[assembly: WebJobsStartup(typeof(StartUp))] namespace EOCS.Polly.FaultyService { public class StartUp : FunctionsStartup { public override void Configure(IFunctionsHostBuilder builder) { } } } - Run the program and note the url.

Deploying the Calling Service
-
In the same solution, add a new Azure Function project named
EOCS.Polly.CallingService. -
Add a new class named CallingService.cs for example and the following code to it.
public class CallingService { public CallingService() { } [FunctionName(nameof(GetAccountById))] public async Task<IActionResult> GetAccountById ([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var client = new HttpClient(); var response = await client.GetAsync ("http://localhost:7271/api/GetNeverResponding"); return new OkResult(); } }
Information 1
In a real-world scenario, the URL should be stored in the configuration file and obtained through dependency injection.
Information 2
The code above simply initiates an HTTP request to our flawed service. The objective is to examine the consequences when a service becomes unresponsive.
- Add a new class named StartUp.cs and the following code to it.
[assembly: WebJobsStartup(typeof(StartUp))] namespace EOCS.Polly.CallingService { public class StartUp : FunctionsStartup { public override void Configure(IFunctionsHostBuilder builder) { } } }
The final configuration should resemble the picture below.

Important
Do not forget to correctly configure the startup projects.

Running the Application
We will now test our application by executing a GET request through Fiddler (or Postman) and observe the ensuing results.
-
Start the application.
-
Execute the following request.

It's evident that this request appears to be without a response.
![]()
What is transpiring aligns precisely with what we illustrated earlier: the calling thread is suspended due to a downstream service experiencing a delay. How to address such a situation? Polly to the rescue!
What is Polly?
Polly is a resilience and transient-fault-handling library designed to help developers handle faults in their applications by providing policies to define and implement fault-handling logic. Polly allows developers to define strategies for various scenarios, such as handling transient faults, retries, timeouts, and circuit breaking (more on this in the subsequent posts).
Polly is particularly beneficial in the context of microservices and we will now explore its practical implementation.
What was the Issue in the Previous Scenario?
The problem arose from a service that never responded. Since the calling code did not enforce timeouts, the thread became suspended. Game over.
The timeout is a simple mechanism allowing you to stop waiting for an answer once you think it won't come. (...) It's essential that any resource pool that blocks threads must have a timeout to ensure that calling threads eventually unblock, whether resources become available or not.
Nygard Release It!: Design and Deploy Production-Ready Software
Installing Polly
- Add the Polly Nuget package to the
EOCS.Polly.CallingServiceproject.

Important
For this series, we are utilizing Polly version 8.
Configuring Polly
Various methods exist to address the challenges posed by network issues or failures in integration points. In Polly, these methods are termed resilience strategies (formerly policies). These strategies can also be combined; for instance, we can implement a timeout policy and fallback to a default value in case of failure. This introduces the concept of a resilience pipeline, which is the amalgamation of multiple strategies for managing a request.
Information
Additional details can be found in the documentation (here).
- Edit the code in the
GetAccountByIdmethod.[FunctionName(nameof(GetAccountById))] public async Task<IActionResult> GetAccountById ([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var pipeline = new ResiliencePipelineBuilder().AddTimeout (TimeSpan.FromSeconds(5)).Build(); // Execute the pipeline asynchronously var response = await pipeline.ExecuteAsync(async token => { var client = new HttpClient(); return await client.GetAsync ("http://localhost:7271/api/GetNeverResponding", token).ConfigureAwait(false); }); return response.IsSuccessStatusCode ? new OkResult() : new BadRequestResult(); }
Upon executing the request via Fiddler, we now receive a response.

Information 1
Now, we indeed receive a response, even though it may be an error 500. It's important to note that Polly doesn't magically resolve the issue with the flawed service but prevents this problem from propagating throughout the entire system: this phenomenon is what is referred to as resilience. In this case, the response might not be the expected one, but crucially, calling threads are not blocked. It's essential to acknowledge that the responsibility to promptly resolve the ongoing issue still rests with us.
Information 2
In a real-world scenario, it is likely that we would prefer to utilize dependency injection instead of creating the pipeline for each request.
Handling Failure
In the previous code, we settle for returning an error 500, but such an error is rather generic and doesn't offer much insight into the underlying problem. It would be more beneficial to provide additional information to developers, especially when we ascertain that a timeout has occurred.
- Edit the code in the
GetAccountByIdmethod.[FunctionName(nameof(GetAccountById))] public async Task<IActionResult> GetAccountById ([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var pipeline = new ResiliencePipelineBuilder().AddTimeout (TimeSpan.FromSeconds(5)).Build(); try { // Execute the pipeline asynchronously var response = await pipeline.ExecuteAsync(async token => { var client = new HttpClient(); return await client.GetAsync ("http://localhost:7271/api/GetNeverResponding", token); }); return new OkResult(); } catch (TimeoutRejectedException) { return new BadRequestObjectResult ("A timeout has occurred while processing the request."); } }
Upon executing the request via Fiddler, we now receive a error 400.

So, we explored the installation and configuration of Polly in a very basic scenario. However, this case was somewhat trivial (in the strict sense, using Polly for a simple timeout is unnecessary). Moving forward, we will dedicate our focus to examining more sophisticated scenarios.
What are Transient Failures?
Transient failures are temporary and typically short-lived errors or issues that occur in a system but are not indicative of a permanent problem. These failures are often transient in nature, meaning they may resolve themselves after a brief period or with a subsequent attempt. Common examples of transient failures include temporary network issues, intermittent service unavailability, or momentary resource constraints.

In the context of distributed systems, where various components communicate over a network, transient failures can be more prevalent. These failures are often unpredictable and can occur due to factors such as network congestion, temporary server unavailability, or brief spikes in resource utilization.
What is a Retry Strategy?
A retry strategy is a mechanism employed to automatically reattempt an operation that has initially failed. This approach involves making multiple consecutive attempts to execute the same operation with the expectation that subsequent attempts might succeed, especially in cases where the failure is transient or due to intermittent issues. Retry strategies aim to improve the resilience and reliability of applications by providing a mechanism to recover from transient failures without manual intervention.
In the context of Polly, a retry strategy involves defining a strategy that specifies the conditions under which retries should occur, the maximum number of retries, and the duration between consecutive retry attempts. This can be particularly useful in handling transient faults, network glitches, or other intermittent issues that may cause an operation to fail temporarily.
Simulating Transient Errors
- Edit the
FaultyServiceclass.public class FaultyService { // ... [FunctionName(nameof(GetWithTransientFailures))] public async Task<IActionResult> GetWithTransientFailures ([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var counter = CounterSingleton.Instance.Increment(); if (counter % 3 == 1) return new InternalServerErrorResult(); else return new OkResult(); } } public class CounterSingleton { private static CounterSingleton _instance; private int _index = 0; private CounterSingleton() { } public static CounterSingleton Instance { get { if (_instance == null) _instance = new CounterSingleton(); return _instance; } } public int Increment() { _index++; return _index; } }Here, we are simulating transient failures by intentionally triggering a bad request once out of every three attempts. This specific operation is executed using a counter implemented as a singleton.
- Edit the
CallingServiceclass in order to call this method.public class CallingService { public CallingService() { } [FunctionName(nameof(GetAccountById02))] public async Task<IActionResult> GetAccountById02([HttpTrigger (AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var client = new HttpClient(); var response = await client.GetAsync ("http://localhost:7271/api/GetWithTransientFailures").ConfigureAwait(false); return response.IsSuccessStatusCode ? new OkResult() : new InternalServerErrorResult(); } }
This request returns an error 500 in the event of an error and a typical error 200 when everything proceeds as expected.
Upon executing this request via Fiddler, we can indeed observe that an error occurs once out of every three attempts.

Information
In our specific case, our code is deterministic, meaning errors are not truly transient. In real-life scenarios, such errors would typically manifest randomly. However, we employ this simulation for illustrative purposes.
Implementing a Retry Strategy With Polly
Wait and retry strategies are commonly employed to handle transient errors, and Polly provides a convenient means to implement such strategies effortlessly.
- Edit the
CallingServiceclass to implement a retry strategy.[FunctionName(nameof(GetAccountById02))] public async Task<IActionResult> GetAccountById02([HttpTrigger (AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req, ILogger log) { var options = new RetryStrategyOptions<HttpResponseMessage>() { Delay = TimeSpan.Zero, MaxRetryAttempts = 3, ShouldHandle = new PredicateBuilder<HttpResponseMessage>().HandleResult (response => response.StatusCode == HttpStatusCode.InternalServerError), }; var pipeline = new ResiliencePipelineBuilder<HttpResponseMessage>().AddRetry (options).Build(); // Execute the pipeline asynchronously var response = await pipeline.ExecuteAsync(async token => { var client = new HttpClient(); return await client.GetAsync ("http://localhost:7271/api/GetWithTransientFailures", token); }); return response.IsSuccessStatusCode ? new OkResult() : new BadRequestResult(); }
Here, we implement a retry strategy with a maximum of 3 attempts. This implies that if a transient failure occurs, the calling service will not promptly return an error; instead, it will reattempt processing the request at least 3 times.
Upon executing this request via Fiddler, we can now observe that these transient failures are effectively handled.

Information
Additional configuration options are available to customize the retry strategy, including settings for the maximum number of attempts and the delay between two retry attempts. For more comprehensive details, please refer to the documentation.
The retry strategy does have a drawback though: if the remote service is entirely down, we will still attempt to reach it, consuming threads in the calling function. A resilient strategy must consider this and implement a circuit breaker. We will explore how to quickly implement it with Polly. But, to avoid overloading this article, readers interested in this implementation can find the continuation here.
History
- 22nd January, 2024: Initial version