
A Deep Dive Into Machine Translation
5.00/5 (1 vote)
In this article we introduce the main theoretical concepts required for building an ML-based translator.
Introduction
Google Translate works so well, it often seems like magic. But it’s not magic — it’s deep learning!
In this series of articles, we’ll show you how to use deep learning to create an automatic translation system. This series can be viewed as a step-by-step tutorial that helps you understand and build a neuronal machine translation.
This series assumes that you are familiar with the concepts of machine learning: model training, supervised learning, neural networks, as well as artificial neurons, layers, and backpropagation.
Before we start coding, we're going to do a quick deep dive into how AI language translation works. If you'd prefer to skip the math and start writing code, you can skip ahead to Tools for Building AI Language Automatic Translation Systems.news
What Makes NMT Tick
Here are the main tools and concepts we’ll use to build an automatic translation machine that, in our case, will translate from English to Russian:
- Recurrent neural networks (RNNs) and long short-term memory (LSTM)
- Encoders and decoders
- Gated recurrent units (GRUs)
- The Attention Mechanism
- Embeddings
- Language models
RNNs and LSTM
First let’s look at the structure of an RNN. A basic one is shown below. As you can see, the structure is built of layers — \(layer_{0},layer_{1},...layer_{k},layer_{k+1},...\) — which form a directed sequence.
The input vector \(X = (X_{0},...X_{n})\) is transformed into an output vector \(Y = (Y_{0},...Y_{n})\).
![]()
Each layer produces an activation \(a_{t}\) (just like any neural network layer) but it also directly produces an output \(Y_{t}\), which is a function of \(a_{t}\).
The equations that describe our simple RNN are as follows:
and
Where: F and G are the activation functions and \(\alpha ,\beta ,\delta ,\epsilon \) are variables that depend on the layer coefficients.
The RNN we are discussing is called many-to-many: many inputs and many outputs. That’s typically what we would use in machine translation (MT). An RNN with a unique input and many outputs is known as a one-to-many RNN, An RNN with many inputs and a unique output is known as a many-to-one RNN.
RNN are not only useful in the MT domain, but also successfully applied for speech recognition, music generation, feeling recognition, and much more.
In the case of MT, we need a slightly different type of RNN:
![]()
In the diagram above, the k components of the input vector are the words of the sentence in English, and the l components of the output vector are the words of the translated sentence in Russian.
LSTMs are advanced, refined RNN architectures that power the more performant RNN designs. In such a design, several (or all) layers are replaced with LSTM cells. These cells are built differently from "ordinary" RNN layers.
Let’s compare an ordinary layer with an LSTM cell. It’s not exactly obvious why the LSTM cell is much more effective than the ordinary RNN layer, but it is definitely more complex.
A LSTM cell has two gates: an input gate  and a forget gate
and a forget gate  . The sigma symbol represents a linear combination[1] with the inputs (+ a constant). It also transfers deep learning hidden states[2].
. The sigma symbol represents a linear combination[1] with the inputs (+ a constant). It also transfers deep learning hidden states[2].

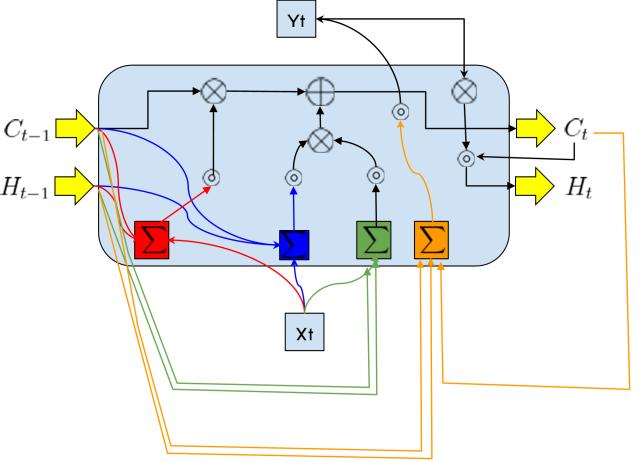
The cell mimics the human concept of forgetting. For example, forgetting non-essential information. It is fully recurrent as it re-inputs the previous states as well.
Explaining in minute detail why the LSTM is good at what it does would take pages, but at least now it's easier to visualize. We also wanted to demonstrate that neural networks are in fact "abstract" logical circuits, conceptually designed rather than coded.
We already illustrated the concept of encoder-decoder in the diagram of the RNN suited for MT above. In fact, these are two RNNs. One is the encoder, which encodes a sequence of words into a fixed-length vector, and the other is a decoder, which performs the same operation in reverse. This RNN is called a sequence to sequence RNN.
Gated Recurrent Unit (GRU)
The GRU is just an LSTM cell with fewer features that can perform better than the "regular" LSTM in certain areas. It can be used to simplify some designs, and will generally perform faster than the regular LSTM. We won’t use GRU in this project, but it's important to mention it here because you'll likely encounter it if you decide to explore AI language translation further.
The Attention Mechanism
The Attention Mechanism is a key concept in NMT that was introduced relatively recently. It gives more "weight" (importance) to one or more words contained in the sentence to translate. This simple mechanism solves many problems that have previously been hard to solve in NMT.
Embeddings
An embedding is a multi-dimensional representation of a word that provides statistical information about it and links it with other "base" words that have a close meaning or a close relationship with that word. For example, the word "lynx" may be embedded as a list of related terms such as (cat, animal, wild), each with some coordinates associated with it.
Word embedding facilitates the skip-gram technique: predicting words that surround a given word.
Language Models
A language model—or language representation of natural language—provides a parameterized view of a language that contains synonyms, similarities between words and sentences, and so on. Some examples of language models commonly used in AI translation systems include BERT, Word2vec, GloVe, and ELMo.
Next Steps
In the next article of this series, we’ll discuss the tools and software required to build a DL-based automatic translation system. Stay tuned!