
Cleaning Data in a Pandas DataFrame
5.00/5 (7 votes)
In this fifth part of the Data Cleaning with Python and Pandas series, we take one last pass to clean up the dataset before reshaping.

Introduction
This article is part of the Data Cleaning with Python and Pandas series. It’s aimed at getting developers up and running quickly with data science tools and techniques.
If you’d like to check out the other articles in the series, you can find them here:
- Part 1 - Introducing Jupyter and Pandas
- Part 2 - Loading CSV and SQL Data into Pandas
- Part 3 - Correcting Missing Data in Pandas
- Part 4 - Combining Multiple Datasets in Pandas
- Part 5 - Cleaning Data in a Pandas DataFrame
- Part 6 - Reshaping Data in a Pandas DataFrame
- Part 7 - Data Visualization using Seaborn and Pandas
Now that we have one big DataFrame that contains all of our combined customer, product, and purchase data, we’re going to take one last pass to clean up the dataset before reshaping.
Note that we've created a complete Jupyter Notebook with the source data files for this series of modules, which you can download and install locally.
Our current dataset doesn't contain any missing values, but it may still contain values that don't make sense or aren’t the correct data types. Let’s look at some of the ways to find and clean this sort of data.
Cleaning Up the Keys
With our DataFrame combined from the three sets of data, we have some inconsistencies around the dataset itself. To correct this, let's drop a number of duplicate keys and rename some others.
First, let's start a new code block and drop the duplicate identifiers by using the following:
combinedData.drop(columns='customer_num', inplace=True)
combinedData.drop(columns='product_num', inplace=True)

This will drop the customer_num and product_num columns.
Pandas can also rename columns, so let's rename the three "id" columns to something a little more representative:
combinedData = combinedData.rename(columns={'id_x':'purchase_id', 'id_y':'customer_id','id':'product_id'})
This renames the column ID to its corresponding source and cleans up our table quite a bit.
Finding Inconsistent Data
One of the other big causes of data mismatching is finding fields that have data in them that’s inconsistent with the intent of the key. For instance, you might have string values mixed in with numbers. Let’s check our dataset and see whether there are any related issues.
Create a new code block and use a command we saw right at the start:
print(combinedData.dtypes)
print(combinedData.head(2))
And here’s the result:

As you can see from the result, much of the data has been classed generically as objects, with only a few keys being classed as numbers (int64).
Let’s try to convert our purch_date key to a datetime and see if any problems occur.
- The
to_datetimemethod tries to convert values to a datetime type - The
to_to_numericmethod tries to convert values to a numeric type - The
value_countsmethod counts the number of different values - The
str.replacemethod applies replaces characters within a string
Change the code block above to the following:
print(pd.to_datetime(combinedData['purch_date'], errors='coerce').isnull().value_counts())

This code block now tries to convert all the values in the purch_date column and counts how many errors (True) or successes (False) occurred. Luckily, this time we have no errors (the first and second numbers match).
Let's expand this code block to check the numbers and currency keys as well:
print(pd.to_numeric(combinedData['amount'], errors='coerce').isnull().value_counts()) print(pd.to_numeric(combinedData['paid'], errors='coerce').isnull().value_counts()) print(pd.to_numeric(combinedData['cost'], errors='coerce').isnull().value_counts())
Here's the result:

If we look at the figures now, at all of the paid and cost errors, there are two amount values that are also errors. The cost and paid columns should be pretty simple to fix because Pandas doesn’t handle currency values written with dollar sign ($). We’ll fix this by removing all the dollar signs from both amount keys with the following methods before the checks:
combinedData.paid = combinedData['paid'].str.replace('$','')
combinedData.cost = combinedData['cost'].str.replace('$','')
Here's the result:

When we run this cleanup and then the checks, the cost errors have been fixed, but the paid key still has a large number of errors.
Let's find which values are causing errors by changing the test to raise errors. We’ll do so using the following method:
print(pd.to_numeric(combinedData['paid'], errors='raise'))
Here's the result:

It looks like our values also contains a comma delimiter at the thousands mark, so we’ll get rid of those as well:
combinedData.paid = combinedData['paid'].str.replace(',','')
combinedData.cost = combinedData['cost'].str.replace(',','')
That was easy:

Now, when we run this phase of the cleanup, we have only two errors left.
Let's change the amount to raise errors and see what the problem is.
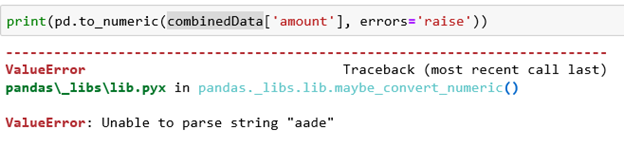
It looks like a string has slipped into two of the rows. Because this is such a small number, we’ll just convert all our keys to be proper types and drop any rows that have null values, which should only be two.
Let's modify our code so we’re left with the final result below:
combinedData.paid = combinedData['paid'].str.replace('$','')
combinedData.cost = combinedData['cost'].str.replace('$','')
combinedData.paid = combinedData['paid'].str.replace(',','')
combinedData.cost = combinedData['cost'].str.replace(',','')
combinedData.purch_date = pd.to_datetime(combinedData['purch_date'], errors='coerce')
combinedData.amount = pd.to_numeric(combinedData['amount'], errors='coerce')
combinedData.paid = pd.to_numeric(combinedData['paid'], errors='coerce')
combinedData.cost = pd.to_numeric(combinedData['cost'], errors='coerce')
combinedData.dropna(subset = ['amount'], inplace=True)
print(combinedData.isnull().sum())
print(combinedData.shape)
print(combinedData.dtypes)
Here's the result:

And now we have our final result: 5,067 rows of cleaned data with correctly assigned types.
Summary
We went through some final iterations of our dataset and cleaned the remaining inconsistencies from our values. We also made sure our dataset had correctly assigned value types and was formed into a complete picture.
Next, we’re going to see how to reshape our data to get it ready for visualizations.
Header image source: https://medium.com/cracking-the-data-science-interview/an-introduction-to-big-data-data-cleaning-a238725a9b2d