
Code optimization tutorial - Part 3
4.82/5 (15 votes)
Beginner optimization tutorial
Introduction
Welcome to part 3 of the code optimization tutorial!
In this part we will look at the techniques that can be applied when we use threads to solve a problem.
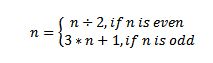
I will solve the same problem as last time, this time taking advantage of multiple processor cores.
Problem statement (complete problem): for every number n between 1 and 1000000 apply the following function: until the number becomes 1, counting the number of time the function was applied.
Because of hardware limitations, the algorithm will be executed for all the numbers between 1 and 100000. No input number from the keyboard will be read and the program will print the result and the execution time(in milliseconds) needed to compute the result.
The test machine will be a laptop with the following specs: AMD Athlon 2 P340 Dual Core 2.20 GHz, 4 GB of RAM, ATI Mobility Radeon 5470 graphics adapter, Windows 7 Ultimate x64.
Language used for implementation: C++ (Visual Studio 2010).
DirectCompute can be also used in C#, by using SharpDX or SlimDX or OpenCL (but I have not explored yet these possibilities).
Also, for the OpenCL implementation, I can not obtain a GPU context. I think that this a driver problem.
Prerequisites
You should read my previous articles: Code Optimization Tutorial - Part 1, Code Optimization Tutorial - Part 2.
Also some knowledge about WinAPI is recommended, but not mandatory.
SSE2 Implementation
First I will implement the algorithm using SSE2 intrinsics (main_v10.cpp). Because my CPU does not support SSE4(which adds support for packed equality compare instructions), I was forced to reduce the range of the numbers processed (maximum 100000).
I extract the data from the queue, 4 numbers at a time and pack them into a 128 bits variable, then I enter a while loop and compute the current cycle for each number:
while ((comparedValue.m128i_i64[0] != 0) || (comparedValue.m128i_i64[1] != 0))<o:p />
{
//compute last bit of every number
oddBit = _mm_and_si128(numbersToProcess, oneValue);
//compute numbers / 2
tempNumber = _mm_srli_epi32(numbersToProcess, 1);
//compute bit mask
mask = _mm_cmpeq_epi32(oddBit, oneValue);
//add 1 to (odd number)/2
tempNumber = _mm_add_epi32(tempNumber, oddBit);
//mask out even numbers
numbersToProcess = _mm_and_si128(numbersToProcess, mask);
//increment current number of cycles
currentCycles = _mm_add_epi32(currentCycles, oneValue);
//update the numbers to process
numbersToProcess = _mm_add_epi32(tempNumber, numbersToProcess);
//add to the current cycle count for the odd numbers
currentCycles = _mm_add_epi32(currentCycles, oddBit);
//check if the number is equal to 1
comparedValue = _mm_cmpeq_epi32(numbersToProcess, oneValue);
//check if the number is smaller than 1
mask = _mm_cmplt_epi32(numbersToProcess, oneValue);
//or the results together from the operations
comparedValue = _mm_or_si128(comparedValue, mask);
//invert the results of the or operation
comparedValue = _mm_xor_si128(comparedValue, ffValue);
//0 the bit of the numbers smaller or equal
//to 1 to avoid side effects(like infinite loops)
numbersToProcess =_mm_and_si128(numbersToProcess, comparedValue);
}
After exiting the while loop, the maximum cycle count will be computed.
Execution time for this implementation is: 23.97 ms.
DirectCompute Implementation
In the DirectCompute implementation (shader.hlsl/main_v11.cpp) I’m running the algorithm on the GPU.
The ComputeShader works by using the thread ID as the number that has to be processed and applies the following algorithm to it:
while(nr > 1)
{
nr2 = nr >> 1;
if(nr & 0x1)
{
nr2 = nr2 + nr + 1;
count++;
}
count++;
nr = nr2;
}
In the part that runs on the CPU, I create the Direct3D device, I setup the output buffer and the unstructured access view, then I call the Dispatch function to process 100000 numbers. After the ComputeShader is done, I copy the output to a buffer which can be read by the CPU and I compute the maximum value.
The execution time for this version is: 185.97 ms.
I assume that this time is due to the time-consuming copy operation needed to copy the output data from the GPU memory to the system RAM or it’s generated by the fact that I am not performing the thread dispatch correctly. (This is my first program using DirectCompute and I am not so familiar with the dispatch process).
OpenCL Implementation
The OpenCL version of the code suffers from the fact that I can not obtain a GPU device (I think this is a driver problem since I can run DirectCompute programs on my computer).
In the setup part, the program gets a device, it creates a command queue, then creates the input and output buffers, then it loads the program and it compiles it and lastly, it obtains the kernel function.
To solve the problem, I apply the following strategy:
I divide the 100000 into chunks of 320 numbers (I obtain the best result with this chunk size), I upload the numbers to the input buffer, then I run the kernel and then I read the result and I compute the maximum.
The execution time is: 46.19 ms.
Points of Interest
The conclusion of this article is that you should always try to take advantage of the SIMD (Single Instruction Multiple Data) processing units of the CPU or GPU.
For the DirectCompute version the amount of data that needs to be copied from GPU memory to CPU memory is very large so, a possible optimization would be to split the data in batches. Another possible optimization would be to compute the maximum cycle count on the GPU and read only that value on the CPU.
For the OpenCL version, it would be interesting to see what happens when the code is able to obtain a GPU context.
History
- 30.07.2012 - Initial release.