Step-by-Step Guide to Implement Machine Learning V - Support Vector Machine
May 14, 2019
5 min read
machine-learning
slack
by Ryukkkk
Contributor
Introduction
Support Vector Machine(SVM) is a classifier based on the max margin in feature space. The learning strategy of SVM is to make the margin max, which can be transformed into a convex quadratic programming problem. Before learning the algorithm of SVM, let me introduce some terms.
Functional margin is defined as: For a given training set T, and hyper-plane(w,b), the functional margin between the hyper-plane (w,b) and the sample(xi, yi) is:
The functional margin between hyper-plane (w,b) and the training set T is the minimum of
Functional margin indicates the confidence level of the classification results. If the hyper-parameters (w,b) change in proportion, for example, change (w,b) into (2w,2b). Though the hyper-plane hasn't changed, the functional margin expend doubles. Thus, we apply some contrains on w to make the hyper-plane definitized , such as normalization ||w|| = 1. Then, the margin is called geometric margin: For a given training set T, and hyper-plane(w,b), the functional margin between the hyper-plane (w,b) and the sample(xi, yi) is:
Similarly, the geometric margin between hyper-plane (w,b) and the training set T is the minimum of
Now, we can conclude the relationship between functional margin and geometric margin:
SVM Model
The SVM model consists of optimization problem, optimization algorithm and classify.
Optimization Problem
When the dataset is linearly separable, the supports vectors are the samples which are nearest to the hyper-plane as shown below.
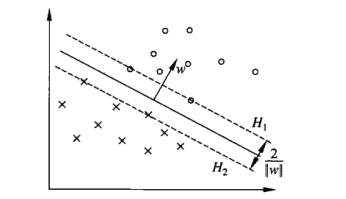
The samples on H1 and H2 are the support vectors.The distance between H1 and H2 is called hard margin. Then, the optimization problem of SVM is:
When the dataset is not linearly separable, some samples in the training set don't satisfy the condition that the functional margin is larger than or equal to 1. To solve the problem, we add a slack variable for each sample
(xi, yi). Then, the constraint is:
Meanwhile, add a cost for each slack variable. The target function is:
where C is the penalty coefficient. When C is large, the punishment of misclassification will be increased, whereas the punishment of misclassification will be reduced. Then, the optimization problem of SVM is:
The support vectors are on the border of margin or between the border and the hyper-plane as shown below. In this case, the margin is called soft margin.
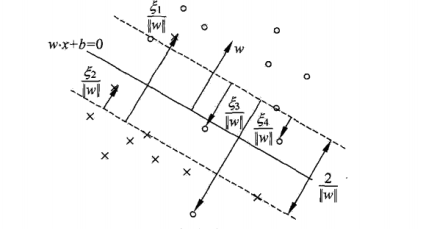
It needs to apply kernel trick to transform the data from original space into feature space when the dataset is not linearly separable. The function for kernel trick is called kernel function, which is defined as:
where is a mapping from input space to feature space, namely,
The code of kernel trick is shown below:
def kernelTransformation(self, data, sample, kernel):
sample_num, feature_dim = np.shape(data)
K = np.zeros([sample_num])
if kernel == "linear": # linear function
K = np.dot(data, sample.T)
elif kernel == "poly": # polynomial function
K = (np.dot(data, sample.T) + self.c) ** self.n
elif kernel == "sigmoid": # sigmoid function
K = np.tanh(self.g * np.dot(data, sample.T) + self.c)
elif kernel == "rbf": # Gaussian function
for i in range(sample_num):
delta = data[i, :] - sample
K[i] = np.dot(delta, delta.T)
K = np.exp(-self.g * K)
else:
raise NameError('Unrecognized kernel function')
return KAfter applying kernel trick, the optimization problem of SVM is:
where is the Lagrange factor.
Optimization Algorithm
It is feasible to solve the SVM optimization problem with traditional convex quadratic programming algorithms. However, when the training set is large, the algorithms will take a long time. To solve the problem, Platt proposed an efficient algorithm called Sequential Minimal Optimization (SMO).
SMO is a kind of heuristic algorithm. When all the variables follow the KKT condition, the optimization problem is solved. Else, choose two variables and fix other variables and construct a convex quadratic programming problem with the two variables. The problem has two variables: one chooses the alpha which violated KKT conditions, the other is determined by the constraints. Denote, the are the variables, fix
. Thus,
is calculated by:
If is determined ,
is determined accordingly. In each iteration of SMO, two variables are updated till the problem solved. Then, the optimization problem of SVM is:
When there is only two variable, it is a simple quadratic programming problem, as shown below:
Because the constraint is:
when ,
when , because
,
.
The optimized value follows:
where L and H are the lower bound and upper bound of the diagonal line, which is calculated by:
The uncutting optimized value follows:
where E1 and E2 are the difference between the prediction value g(x) and the real value. g(x) is defined as:
So far, we get feasible solutions for :
There are two loops in SMO, namely, outside loop and inner loop.
In the outside loop, choose the alpha which violated KKT conditions, namely,
First, search the samples follow .If all the samples follow the condition, search the whole dataset.
In the inner loop, first search the which make
maximum. If the chosen
doesn't decrease enough, first search the samples on the margin border. If the chosen
decreases enough, stop search. Else, search the whole dataset. If we can find a feasible
after searching the whole dataset, we will choose a new
.
In each iteration, we updated b by:
For convenience, we have to store the value of , which is calculated by:
The search and update code is shown below:
def innerLoop(self, i):
Ei = self.calculateErrors(i)
if self.checkKKT(i):
j, Ej = self.selectAplha2(i, Ei) # select alpha2 according to alpha1
# copy alpha1 and alpha2
old_alpha1 = self.alphas[i]
old_alpha2 = self.alphas[j]
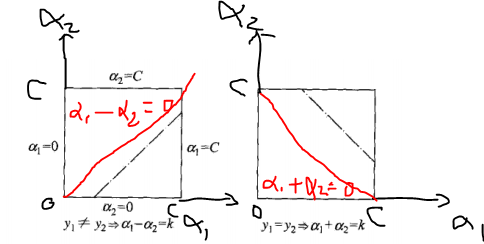
# determine the range of alpha2 L and H in page of 126
# if y1 != y2 L = max(0, old_alpha2 - old_alpha1),
H = min(C, C + old_alpha2 - old_alpha1)
# if y1 == y2 L = max(0, old_alpha2 + old_alpha1 - C),
H = min(C, old_alpha2 + old_alpha1)
if self.train_label[i] != self.train_label[j]:
L = max(0, old_alpha2 - old_alpha1)
H = min(self.C, self.C + old_alpha2 - old_alpha1)
else:
L = max(0, old_alpha2 + old_alpha1 - self.C)
H = min(self.C, old_alpha2 + old_alpha2)
if L == H:
# print("L == H")
return 0
# calculate eta in page of 127 Eq.(7.107)
# eta = K11 + K22 - 2K12
K11 = self.K[i, i]
K12 = self.K[i, j]
K21 = self.K[j, i]
K22 = self.K[j, j]
eta = K11 + K22 - 2 * K12
if eta <= 0:
# print("eta <= 0")
return 0
# update alpha2 and its error in page of 127 Eq.(7.106) and Eq.(7.108)
self.alphas[j] = old_alpha2 + self.train_label[j]*(Ei - Ej)/eta
self.alphas[j] = self.updateAlpha2(self.alphas[j], L, H)
new_alphas2 = self.alphas[j]
self.upadateError(j)
# update the alpha1 and its error in page of 127 Eq.(7.109)
# new_alpha1 = old_alpha1 + y1y2(old_alpha2 - new_alpha2)
new_alphas1 = old_alpha1 + self.train_label[i] *
self.train_label[j] * (old_alpha2 - new_alphas2)
self.alphas[i] = new_alphas1
self.upadateError(i)
# determine b in page of 130 Eq.(7.115) and Eq.(7.116)
# new_b1 = -E1 - y1K11(new_alpha1 - old_alpha1) -
y2K21(new_alpha2 - old_alpha2) + old_b
# new_b2 = -E2 - y1K12(new_alpha1 - old_alpha1) -
y2K22(new_alpha2 - old_alpha2) + old_b
b1 = - Ei - self.train_label[i] * K11 * (old_alpha1 - self.alphas[i]) -
self.train_label[j] * K21 * (old_alpha2 - self.alphas[j]) + self.b
b2 = - Ej - self.train_label[i] * K12 * (old_alpha1 - self.alphas[i]) -
self.train_label[j] * K22 * (old_alpha2 - self.alphas[j]) + self.b
if (self.alphas[i] > 0) and (self.alphas[i] < self.C):
self.b = b1
elif (self.alphas[j] > 0) and (self.alphas[j] < self.C):
self.b = b2
else:
self.b = (b1 + b2)/2.0
return 1
else:
return 0Classify
We can make a prediction using the optimized parameters, which is given by:
for i in range(test_num):
kernel_data = self.kernelTransformation(support_vectors, test_data[i, :], self.kernel)
probability[i] = np.dot(kernel_data.T, np.multiply
(support_vectors_label, support_vectors_alphas)) + self.b
if probability[i] > 0:
prediction[i] = 1
else:
prediction[i] = -1Conclusion and Analysis
SVM is a more complex algorithm than previous algorithms. In this article, we simplify the search process to make it a bit more easy to understand. Finally, let's compare our SVM with the SVM in Sklearn and the detection performance is displayed below:

The detection performance is a little worse than the sklearn's , which is because the SMO in our SVM is simpler than sklearn's.
The related code and dataset in this article can be found in MachineLearning.
License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)