
Neural Network for Recognition of Handwritten Digits in C#
4.93/5 (85 votes)
This article is an example of an artificial neural network designed to recognize handwritten digits.
Introduction
This article is another example of an artificial neural network designed to recognize handwritten digits based on the brilliant article Neural Network for Recognition of Handwritten Digits by Mike O'Neill. Although many systems and classification algorithms have been proposed in the past years, handwriting recognition has always been a challenging task in pattern recognition. Mike O’Neill’s program is an excellent demo to programmers who want to study on neuron network for pattern recognition in general, and especially on convolution neural network. The program has been written in MFC/C++ model, which is a little bit difficult to someone who is not familiar with it. So, I decided to rewrite it in C# with some of my experiments. My program has achieved some results nearly reaching to that of the original, but it is still not optimized enough (convergence speed, error rate, etc.). It is just initial code which simply gets the job done and helps to understand the network, so it is really confusing and needs to be reconstructed. I have been trying to rebuild it as a library so it would be flexible and is easy to change parameters through an INI file. Hopefully, I can get the expected result someday.
Character Detection
Pattern detection or character candidate detection is one of the most importance problems I had to face in my program. In fact, I did not only want to simply rewrite Mike’s program in another language but I also wanted to recognize characters in a document picture. There are some researches that have proposed very good algorithms for object detection that I found in the Internet, but they are too complicated for a free-time project like my own. A small algorithm I found when teaching my daughter drawing solved my problem. Of course, it still has limitations, but it exceeded my expectations in the first test. In the normal, character candidate detection is divided to row detection, word detection and character detection with separate and different algorithms. My approach is little bit different. Detections used same algorithm with functions:
public static Rectangle GetPatternRectangeBoundary
(Bitmap original,int colorIndex, int hStep, int vStep, bool bTopStart)
and:
public static List<Rectangle> PatternRectangeBoundaryList
(Bitmap original, int colorIndex, int hStep, int vStep,
bool bTopStart,int widthMin,int heightMin)
Row, word or character can be detected by simple changing parameters: hStep (horizon step) and vStep (vertical step). Rectangle boundaries also can be detected from top to bottom or left to right by changing bTopStart to true or false. Rectangle can be limited by widthMin and d. The biggest advantage of my algorithm is: it can detect words or character groups which do not lie in a same row.
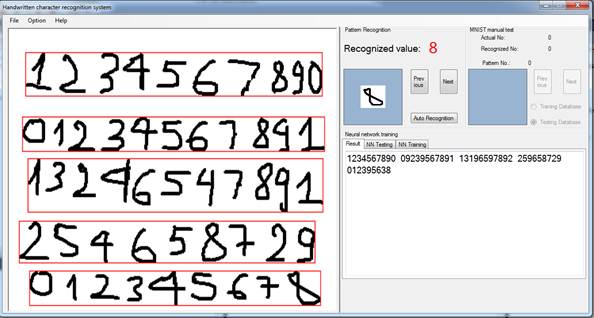
The character candidate recognition can be obtained by function as follows:
public void PatternRecognitionThread(Bitmap bitmap)
{
_originalBitmap = bitmap;
if (_rowList == null)
{
_rowList = AForge.Imaging.Image.PatternRectangeBoundaryList
(_originalBitmap,255, 30, 1, true, 5, 5);
_irowIndex = 0;
}
foreach(Rectangle rowRect in _rowList)
{
_currentRow = AForge.Imaging.ImageResize.ImageCrop
(_originalBitmap, rowRect);
if (_iwordIndex == 0)
{
_currentWordsList = AForge.Imaging.Image.PatternRectangeBoundaryList
(_currentRow, 255, 20, 10, false, 5, 5);
}
foreach (Rectangle wordRect in _currentWordsList)
{
_currentWord = AForge.Imaging.ImageResize.ImageCrop
(_currentRow, wordRect);
_iwordIndex++;
if (_icharIndex == 0)
{
_currentCharsList =
AForge.Imaging.Image.PatternRectangeBoundaryList
(_currentWord, 255, 1, 1, false, 5, 5);
}
foreach (Rectangle charRect in _currentCharsList)
{
_currentChar = AForge.Imaging.ImageResize.ImageCrop
(_currentWord, charRect);
_icharIndex++;
Bitmap bmptemp = AForge.Imaging.ImageResize.FixedSize
(_currentChar, 21, 21);
bmptemp = AForge.Imaging.Image.CreateColorPad
(bmptemp,Color.White, 4, 4);
bmptemp = AForge.Imaging.Image.CreateIndexedGrayScaleBitmap
(bmptemp);
byte[] graybytes = AForge.Imaging.Image.GrayscaletoBytes(bmptemp);
PatternRecognitionThread(graybytes);
m_bitmaps.Add(bmptemp);
}
string s = " \n";
_form.Invoke(_form._DelegateAddObject, new Object[] { 1, s });
If(_icharIndex ==_currentCharsList.Count)
{
_icharIndex =0;
}
}
If(_iwordIndex==__currentWordsList.Count)
{
_iwordIndex=0;
}
}
}
Character Recognition
The Convolution Neural Network (CNN) in the original program is essentially a CNN with five layers, including the input layer. The detail of the convolution architecture has been described by Mike and by Dr. Simard in their article: "Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis". The general strategy of this convolutional network is to extract simple features at a higher resolution, and then convert them into more complex features at a coarser resolution. The simplest way to generate a coarser resolution is to sub-sample a layer by a factor of 2. This, in turn, is a clue to the convolution's kernel's size. The width of the kernel is chosen to be centered on a unit (odd size), to have sufficient overlap to not lose information (3 would be too small with only one unit overlap), but yet to not have redundant computation (7 would be too large, with 5 units or over 70% overlap). Therefore, the convolution kernel of size 5 is chosen in this network. Padding the input (making it larger so that there are feature units centered on the border) did not improve performance significantly. With no padding, a subsampling of 2, and a kernel size of 5, each convolution layer reduces the feature size from n to (n-3)/2. Since the initial MNIST input size is 28x28, the nearest value which generates an integer size after 2 layers of convolution is 29x29. After 2 layers of convolution, the feature size of 5x5 is too small for a third layer of convolution. Dr. Simard also emphasized that if the first layer has fewer than five different features, it decreased performance; while using more than 5 did not improve it (Mike used 6 features). Similarly, on the second layer, fewer than 50 features decreased performance while more (100 features) did not improve it. A summary of the neural network is as follows:
Layer #0: is the gray scale image of the handwritten character in the MNIST database which is padded to 29x29 pixel. There are 29x29= 841 neurons in the input layer.
Layer #1: is a convolutional layer with six (6) feature maps. There are 13x13x6 = 1014 neurons, (5x5+1)x6 = 156 weights, and 1014x26 = 26364 connections from layer #1 to the previous layer.
Layer #2: is a convolutional layer with fifty (50) feature maps. There are 5x5x50 = 1250 neurons, (5x5+1)x6x50 = 7800 weights, and 1250x(5x5x6+1)=188750 connections from layer #2 to the previous layer.
(Not 32500 connections in Mike’s article).
Layer #3: is a fully-connected layer with 100 units. There are 100 neurons, 100x(1250+1) = 125100 weights, and 100x1251 = 125100 connections.
Layer #4: is the final, there are 10 neurons, 10x(100+1) = 1010 weights, and 10x101 = 1010 connections.
Back Propagation
Back propagation is the process that updates the change in the weights for each layer, which starts with the last layer and moves backwards through the layers until the first layer is reached.
In standard back propagation, each weight is updated according to the following formula:
 (1)
(1)
Where eta is the "learning rate", typically a small number like 0.0005 that is gradually decreased during training. However, standard back propagation does not need to be used in the original program because of slow convergence. Instead, the second order technique called “stochastic diagonal Levenberg-Marquardt method”, which was proposed by Dr. LeCun in his article "Efficient BackProp”, has been applied. Although Mike said that it is not dissimilar to standard back propagation, a little theory should help freshmen like me to easier understand the code.
In Levenberg-Marquardt method, rw is calculated as follows:

Assuming a squared cost function:
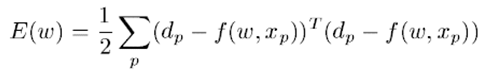
Then the Gradient is:
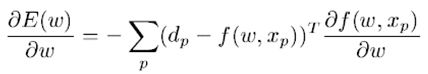
And the Hessian follows as:

A simplifying approximation of the Hessian is square of the Jacobian, which is a positive semi-definite matrix of dimension: N x O.
Back propagation procedures for computing the diagonal Hessian in neural networks are well known. Assuming that each layer in the network has the functional form:
![]()
Using Gaus-Neuton approximation (drop the term that contains ¦’’(y)), we obtain:


and:

A Stochastic Diagonal Levenberg-Marquardt Method
In fact, techniques using full Hessian information (Levenberg-Marquardt, Gaus-Newton, etc.) can only apply to very small networks trained in batch mode, not in stochastic mode. In order to obtain a stochastic version of the Levenberg-Marquardt algorithm, Dr. LeCun has proposed the idea to compute the diagonal Hessian through a running estimate of the second derivative with respect to each parameter. The instantaneous second derivative can be obtained via back propagation as shown in the formulas (7, 8, 9). As soon as we have those running estimates, we can use them to compute individual learning rates for each parameter:

Where e is the global learning rate, and  is a running estimate of the diagonal second derivative with respect to hki. m is a parameter to prevent hki from blowing up in case the second derivative is small, i.e., when the optimization moves in flat parts of the error function. The second derivatives can be computed in a subset of the training set (500 randomized patterns / 60000 patterns of the training set). Since they change very slowly, they only need to be re-estimated every few epochs. In the original program, the diagonal Hessian is re-estimated every epoch.
is a running estimate of the diagonal second derivative with respect to hki. m is a parameter to prevent hki from blowing up in case the second derivative is small, i.e., when the optimization moves in flat parts of the error function. The second derivatives can be computed in a subset of the training set (500 randomized patterns / 60000 patterns of the training set). Since they change very slowly, they only need to be re-estimated every few epochs. In the original program, the diagonal Hessian is re-estimated every epoch.
Here is the second derivative computation function in C#:
public void BackpropagateSecondDerivatives(DErrorsList d2Err_wrt_dXn /* in */,
DErrorsList d2Err_wrt_dXnm1 /* out */)
{
// nomenclature (repeated from NeuralNetwork class)
// NOTE: even though we are addressing SECOND
// derivatives ( and not first derivatives),
// we use nearly the same notation as if there
// were first derivatives, since otherwise the
// ASCII look would be confusing. We add one "2"
// but not two "2's", such as "d2Err_wrt_dXn",
// to give a gentle emphasis that we are using second derivatives
//
// Err is output error of the entire neural net
// Xn is the output vector on the n-th layer
// Xnm1 is the output vector of the previous layer
// Wn is the vector of weights of the n-th layer
// Yn is the activation value of the n-th layer,
// i.e., the weighted sum of inputs BEFORE the squashing function is applied
// F is the squashing function: Xn = F(Yn)
// F' is the derivative of the squashing function
// Conveniently, for F = tanh, then F'(Yn) = 1 - Xn^2, i.e.,
// the derivative can be calculated from the output,
// without knowledge of the input
int ii, jj;
uint kk;
int nIndex;
double output;
double dTemp;
var d2Err_wrt_dYn = new DErrorsList(m_Neurons.Count);
//
// std::vector< double > d2Err_wrt_dWn( m_Weights.size(), 0.0 );
// important to initialize to zero
//////////////////////////////////////////////////
//
///// DESIGN TRADEOFF: REVIEW !!
//
// Note that the reasoning of this comment is identical
// to that in the NNLayer::Backpropagate()
// function, from which the instant
// BackpropagateSecondDerivatives() function is derived from
//
// We would prefer (for ease of coding) to use
// STL vector for the array "d2Err_wrt_dWn", which is the
// second differential of the current pattern's error
// wrt weights in the layer. However, for layers with
// many weights, such as fully-connected layers,
// there are also many weights. The STL vector
// class's allocator is remarkably stupid when allocating
// large memory chunks, and causes a remarkable
// number of page faults, with a consequent
// slowing of the application's overall execution time.
// To fix this, I tried using a plain-old C array,
// by new'ing the needed space from the heap, and
// delete[]'ing it at the end of the function.
// However, this caused the same number of page-fault
// errors, and did not improve performance.
// So I tried a plain-old C array allocated on the
// stack (i.e., not the heap). Of course I could not
// write a statement like
// double d2Err_wrt_dWn[ m_Weights.size() ];
// since the compiler insists upon a compile-time
// known constant value for the size of the array.
// To avoid this requirement, I used the _alloca function,
// to allocate memory on the stack.
// The downside of this is excessive stack usage,
// and there might be stack overflow probelms. That's why
// this comment is labeled "REVIEW"
double[] d2Err_wrt_dWn = new double[m_Weights.Count];
for (ii = 0; ii < m_Weights.Count; ++ii)
{
d2Err_wrt_dWn[ii] = 0.0;
}
// calculate d2Err_wrt_dYn = ( F'(Yn) )^2 *
// dErr_wrt_Xn (where dErr_wrt_Xn is actually a second derivative )
for (ii = 0; ii < m_Neurons.Count; ++ii)
{
output = m_Neurons[ii].output;
dTemp = m_sigmoid.DSIGMOID(output);
d2Err_wrt_dYn.Add(d2Err_wrt_dXn[ii] * dTemp * dTemp);
}
// calculate d2Err_wrt_Wn = ( Xnm1 )^2 * d2Err_wrt_Yn
// (where dE2rr_wrt_Yn is actually a second derivative)
// For each neuron in this layer, go through the list
// of connections from the prior layer, and
// update the differential for the corresponding weight
ii = 0;
foreach (NNNeuron nit in m_Neurons)
{
foreach (NNConnection cit in nit.m_Connections)
{
try
{
kk = (uint)cit.NeuronIndex;
if (kk == 0xffffffff)
{
output = 1.0;
// this is the bias connection; implied neuron output of "1"
}
else
{
output = m_pPrevLayer.m_Neurons[(int)kk].output;
}
// ASSERT( (*cit).WeightIndex < d2Err_wrt_dWn.size() );
// since after changing d2Err_wrt_dWn to a C-style array,
// the size() function this won't work
d2Err_wrt_dWn[cit.WeightIndex] = d2Err_wrt_dYn[ii] * output * output;
}
catch (Exception ex)
{
}
}
ii++;
}
// calculate d2Err_wrt_Xnm1 = ( Wn )^2 * d2Err_wrt_dYn
// (where d2Err_wrt_dYn is a second derivative not a first).
// d2Err_wrt_Xnm1 is needed as the input value of
// d2Err_wrt_Xn for backpropagation of second derivatives
// for the next (i.e., previous spatially) layer
// For each neuron in this layer
ii = 0;
foreach (NNNeuron nit in m_Neurons)
{
foreach (NNConnection cit in nit.m_Connections)
{
try
{
kk = cit.NeuronIndex;
if (kk != 0xffffffff)
{
// we exclude ULONG_MAX, which signifies the phantom bias neuron with
// constant output of "1", since we cannot train the bias neuron
nIndex = (int)kk;
dTemp = m_Weights[(int)cit.WeightIndex].value;
d2Err_wrt_dXnm1[nIndex] += d2Err_wrt_dYn[ii] * dTemp * dTemp;
}
}
catch (Exception ex)
{
return;
}
}
ii++; // ii tracks the neuron iterator
}
double oldValue, newValue;
// finally, update the diagonal Hessians
// for the weights of this layer neuron using dErr_wrt_dW.
// By design, this function (and its iteration
// over many (approx 500 patterns) is called while a
// single thread has locked the neural network,
// so there is no possibility that another
// thread might change the value of the Hessian.
// Nevertheless, since it's easy to do, we
// use an atomic compare-and-exchange operation,
// which means that another thread might be in
// the process of backpropagation of second derivatives
// and the Hessians might have shifted slightly
for (jj = 0; jj < m_Weights.Count; ++jj)
{
oldValue = m_Weights[jj].diagHessian;
newValue = oldValue + d2Err_wrt_dWn[jj];
m_Weights[jj].diagHessian = newValue;
}
}
//////////////////////////////////////////////////////////////////
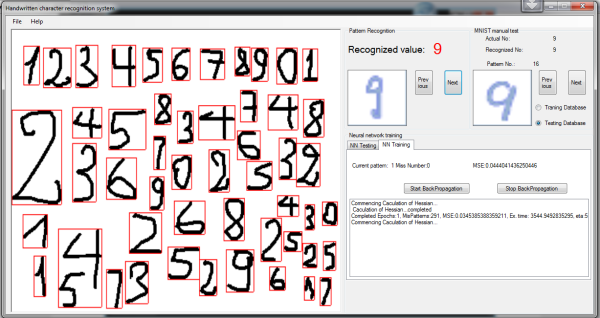
Training and Experiments
Although there is an incompatibility between MFC/C++ and C#, my program is similar to the original. Using the MNIST database, the network performed 291 mis-recognitions out of 60,000 patterns of the training set. It means the error rate is only 0.485%. However, it performed 136 mis-recognitions out of 10,000 patterns of the testing set, and the error rate is 1.36 %. The result was not as good as the benchmark, but it was enough for me to do experiments with my own handwritten character set. Firstly, the input picture was divided into character groups from top to bottom, after that, characters in each group would be detected from left to right and resized to 29x29 pixels before recognized by the neural network. The program satisfied my requirements in general, my own hand written digits could be recognized in good order. Detection functions have been added to AForge.Net’s Image processing library for future works. However, because it has only been programmed at my free times only, so I am sure that it has huge bugs that need to be fixed. Back propagation time is an example. It usually takes around 3800 seconds per epoch with a distorted training set, but only 2400 seconds vice versa. (My computer is an Intel Pentium dual core E6500.) It is rather slow when compared to Mike’s program etc. I also do hope to have a better handwritten character database or cooperate with someone to continue my experiments and developing my algorithms for a real application.


Bibliography
- Neural Network for Recognition of Handwritten Digits by Mike O'Neill
- List of publications by Dr. Yann LeCun
- Section of Dr. LeCun's website on "Learning and Visual Perception"
- Modified NIST ("MNIST") database (11,594 KB total)
- Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, "Gradient-Based Learning Applied to Document Recognition", Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998. [46 pages].
- Y. LeCun, L. Bottou, G. Orr, and K. Muller, "Efficient BackProp", in Neural Networks: Tricks of the trade, (G. Orr and Muller K., eds.), 1998. [44 pages]
- Patrice Y. Simard, Dave Steinkraus, John Platt, "Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis," International Conference on Document Analysis and Recognition (ICDAR), IEEE Computer Society, Los Alamitos, pp. 958-962, 2003.
- Fabien Lauer, Ching Y. Suen and Gerard Bloch, "A Trainable Feature Extractor for Handwritten Digit Recognition", Elsevier Science, February 2006
- Some additional projects on CodeProject.com that have been used in my program: