
ElasticSearch Tutorial: Creating an Index and Querying
5.00/5 (1 vote)
ElasticSearch Tutorial: How to create an Index and Querying
The post appeared first on Tests4Geeks.
Elasticsearch is a highly-scalable document storage engine that specializes in search. Elasticsearch comes with reasonable default settings, but it will also easily scale to being able to search hundreds of millions of documents with sub-second latency. As you’ll see in this tutorial, the JSON-based nature of Elasticsearch, along with its simple REST API, make it easy to learn.

Installation
Elasticsearch is written in Java, so it should work on any operating system that can run Java. If you don’t have Java installed on your machine already, click here to download and install it. We’re going to do this tutorial with version 2.3.1 of Elasticsearch.
Elasticsearch is really simple to get up and running – you can have a one-node cluster running in just a few minutes with the following steps:
- Download and unzip Elasticsearch 2.3.1 found here.
- Navigate to the directory you unzipped it to, and run bin/elasticsearch if you are using Linux or OS X or bin/elasticsearch.bat if you are using Windows.
- In your browser, navigate to http://localhost:9200/, you should see a page that looks something like this:

Basic Terms
Document
A document is the basic record you store in Elasticsearch. You can think of it being roughly similar to a row in a traditional database. Documents are structured as JSON objects and must belong to a type.
Type
A type is a set of documents with common fields. You can think of it as being similar to a table in a traditional database, but the definition is somewhat less strict.
Index
An index is a collection of related types of documents. It is somewhat similar in function to a database or schema in the traditional database world.
Shard
The example Elasticsearch index we build today will be really small, but many indexes can get quite large and it isn’t uncommon at all to have Elasticsearch index with multiple terabytes of data in them. Sharding helps you scale this data beyond one machine by breaking your index up into multiple parts and storing it on multiple nodes.
Beyond allowing for more storage, shards also allow for better performance, because data in the same index can be searched by multiple nodes at the same time.
Replica
A replica is simply a copy of a shard. This is useful for protecting against hardware failures – if all of your shards are replicated, then the failure of one node in your cluster will not impact availability. Replicas also improve throughput and latency by making your index’s data available to more nodes in the cluster.
The following diagram demonstrates how sharding and replication work:

Interacting with Our Cluster
As mentioned before, the interface to Elasticsearch is a REST API that you interact with over HTTP by sending certain URLs, and in some cases HTTP bodies composed of JSON objects that you use to give commands to the cluster. Some of these commands are simple GET requests and can be performed in your browser, but many others are POSTs with bodies, so we need a tool to help us make these requests to the cluster.
The are two easy options for accomplishing this: the Sense plug in for Chrome; or using an HTTP client such as cURL or Postman to compose requests yourself. Following are the details for both options.
Sense Plug in
The Sense plug in for Chrome can be found here, and is what we will use in this tutorial to interact with the cluster. It makes it easy for us to compose and send GETs, POSTs, or PUTs to the server to tell it to index data or retrieve results for us.
Once you’ve installed it, you’ll see a UI that looks like this:

The top part (labeled ‘Server’) is the host and port where the server is located. If you used the default settings when starting Elasticsearch, you can leave this as localhost:9200.
The bottom part is broken up into two panes:
The left pane has your commands, which should be formatted with the HTTP action (GET, POST, PUT) and the URL (_search, /books/book/1). In the case of a GET, that will be all you need. In the case of a POST or PUT with a body, you’ll provide the body as JSON on subsequent lines. To run the command, simply click the green arrow next to it. You can have multiple commands in this view and run them separately. Here’s an example of an indexing operation:

The right pane contains the result of your operation, in JSON form.

Here is what an entire request looks like:

Using an HTTP Client
If you’d rather not install the Sense plug in, you can use an HTTP client such as cURL or Postman to compose requests yourself. When you see an action, simply add it to http://localhost:9200 to make the request (for example, if the Sense directions say ‘GET _search’, you’ll make a GET request to http://localhost:9200/_search.
Loading Our First Documents
Let’s load some documents to give ourselves some data to work with. We’re going to create documents representing computer programming books, with the following fields:
title– The title of the bookauthor– The author of the booklanguage– The language the book is primarily aboutpublished– The year the book was publishedsummary– A short summary of the book
Additionally, our books will also have an ID to make it easier to look them up by that reference, but the ID won’t be part of the document we create.
So, let’s create our first book:
POST /books/book/1
{
"title" : "Effective Java",
"author" : "Josh Bloch",
"language" : "Java",
"publishYear" : 2008,
"summary" : "Are you looking for a deeper understanding of the Java programming language
so that you can write code that is clearer, more correct, more robust, and more reusable?
Look no further! Effective Java, Second Edition, brings together seventy-eight indispensable
programmer’s rules of thumb: working, best-practice solutions for the programming challenges
you encounter every day."
}
You’ll notice we never defined an index or type, but it still worked – Elasticsearch will create these on the fly for you! As your documents get more complicated and your use of Elasticsearch grows, you’ll find situations where you want to customize the indexing behavior of Elasticsearch and will want to define a type by supplying a mapping, but we don’t need to do that for this tutorial.
Now, let’s make sure we can get our book back by ID:
GET /books/book/1

Now that we understand how to create and view a document, let’s create a few more to give us some interesting stuff to search on:
POST /books/book/2
{
"title" : "JavaScript: The Good Parts",
"author" : "Douglas Crockford",
"language" : "JavaScript",
"publishYear" : 2008,
"summary" : "Most programming languages contain good and bad parts, but JavaScript has more than
its share of the bad, having been developed and released in a hurry before it could be refined.
This authoritative book scrapes away these bad features to reveal a subset of JavaScript that's
more reliable, readable, and maintainable than the language as a whole—a subset you can use
to create truly extensible and efficient code."
}
POST /books/book/3
{
"title" : "Programming in Scala: A Comprehensive Step-by-Step Guide, 2nd Edition",
"author" : "Martin Odersky",
"language" : "Scala",
"publishYear" : 2011,
"summary" : "Scala is an object-oriented programming language for the Java Virtual Machine.
In addition to being object-oriented, Scala is also a functional language, and combines
the best approaches to OO and functional programming."
}
POST /books/book/4
{
"title" : "Hadoop: The Definitive Guide, 4th Edition",
"author" : "Tom White",
"language" : "Java",
"publishYear" : 2015,
"summary" : "Get ready to unlock the power of your data. With the fourth edition of this
comprehensive guide, you’ll learn how to build and maintain reliable, scalable,
distributed systems with Apache Hadoop. This book is ideal for programmers looking
to analyze datasets of any size, and for administrators who want to set up
and run Hadoop clusters."
}
POST /books/book/5
{
"title" : "Learn You a Haskell for Great Good!: A Beginner's Guide",
"author" : "Miran Lipovaca",
"language" : "Haskell",
"publishYear" : 2011,
"summary" : "It's all in the name: Learn You a Haskell for Great Good! is a hilarious,
illustrated guide to this complex functional language. Packed with the author's original artwork,"
pop culture references, and most importantly, useful example code, this book teaches functional
fundamentals in a way you never thought possible."
}
Querying with the JSON DSL
Now we should have five documents in our index. We already saw one way to query for data in our index, by ID, so let’s look at another one: getting all of the documents in our index.
GET /books/book/_search
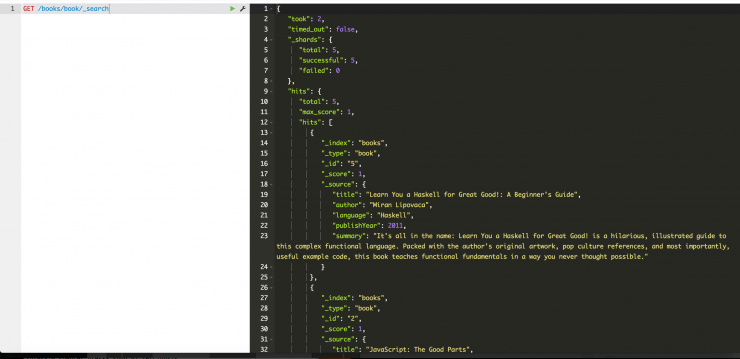
As you can see, there are a number of JSON elements in the result. The interesting ones are described below:
- “
took” – This is how long (in ms) the search took. - “
timed_out” – You can tell Elasticsearch to stop querying and return results after a certain amount of time. We won’t cover how to do that in this tutorial, but this field says whether or not that timeout was reached. - “
hits” is our list of results. - “
_index” tells us what index the result came from. It is possible to search across multiple indexes. - “
_type” tells us what type the result came from. It is possible to search across multiple types. - “
_id” is the identifier for our document. In our case, we supplied them when creating our document, but it is also possible to let Elasticsearch assign them. - “
score” is telling us how well the document matched our query. - “
source” is the document itself.
Now that we know how to interpret our results, let’s try some more advanced queries.
Let’s find all books that are about Java. We’ll use a query string query to search all fields for ‘java’:
POST /books/book/_search
{
"query" :
{
"query_string":
{
"query": "java"
}
}
}

This searches all fields for any reference to Java. You’ll note that it matches three books: One with a reference to Java only in the language field, one that matches in the summary, language, and title fields, and another that only matches it in the summary.
We can also query on non-string fields (or perform exact matches on string fields) with a filter. Let’s combine a filter with a match_all query to find all books published in 2011 or later:
POST /books/book/_search
{
"query" :
{
"filtered":
{
"query" :
{
"match_all": {}
},
"filter":
{
"range":
{
"publishYear":
{
"from": 2011
}
}
}
}
}
}

Now, let’s combine the two to find all Java books written in 2014 or earlier:
POST /books/book/_search
{
"query" :
{
"filtered":
{
"query" :
{
"query_string":
{
"query": "java"
}
},
"filter":
{
"range":
{
"publishYear":
{
"to": 2014
}
}
}
}
}
}

Conclusion
You’ve learned how to index documents and query them with Elasticsearch with very little effort. This is just a small sample of the power of Elasticsearch, but it also shows you some of the power it has. Elasticsearch documentation is available to help you as you pursue more advanced usages of it.
Spencer Uresk is a software architect who works with Java, Spark, Hadoop, and Elasticsearch. He blogs at www.spenceruresk.com.