
C#.NET: Implementing SVD++ AI Data Mining Algorithm To Produce Recommendations Based On Ratings Prediction
5.00/5 (14 votes)
In this article, we will discuss about the implementation of the SVD++ AI data mining algorithm to produce recommendations based on ratings prediction
Introduction
In this article, we’ll discuss about the SVD++ algorithm, - one of the most powerful and successful AI data mining algorithms of the modern recommender systems that produce recommendations based on the model-based collaborative filtering (CF) approach.
In general, the collaborative filtering is an approach that allows to produce recommendations for an active user based on performing the analysis of rating behavior of the active user and the other users having similar tastes and preferences, as well as the popularity and interest to an item being rated represented as the number of ratings given to the item in the past [4].
The entire process of collaborative filtering can be reduced into the two main procedures of either user-based or item-based collaborative filtering [4].
The item-based approach is based on the estimation of a user’s preference to an item relying solely on what particular ratings were given to the similar items by the same user. In turn, the user-based approach is used to estimate the preference of a user to an item based on the ratings previously given by the other users to the same item. In the other words, these both methods actually map users to the items space by representing users as the sets of rated items [1,3].
To produce recommendations, a collaborative filtering engine basically processes the data on the two different types of objects – the either users or items. Normally, it’s very hard to compare those objects since they’re not logically interrelated. There’re basically two approaches that facilitate to such comparison: the either memory-based or model-based collaborative filtering [1,3,4].
The memory-based approach typically uses the neighborhood algorithms such k-nearest neighbors or k-means clustering to produce recommendations relying on the distance-based similarity between particular users or items. Those algorithms normally perform a search to find the users with preferences similar to an active user and recommend the active user a set of items that has already been recommended to similar users in the past. Similarly, the following algorithms aim to find the similar items and recommend them together with the current item to a specific user [1,4].
Another special case of the collaborative filtering is the model-based approach. This approach basically relies on using the latent factor models and the family of SVD algorithms (particularly SVD++ algorithm) that comprise an alternative approach by transforming both items and users to the same space of latent factors, and, thus, making them perfectly comparable [1,3,4].
As well as the other algorithms, the SVD++ algorithm with implicit feedback produces recommendations based on the ratings prediction, which is typically done by analyzing the both users or items latent factors implicitly inferred from the number of either user’s or item’s effects such as the tendency to give the either “positive” or “negative” effects or an interest and popularity of an item being rated [1,3].
The main goal of the SVD++ algorithm is to explain the existing ratings by finding the latent factors exhibited on the data from matrix of ratings. This typically done by performing a search to find the either user’s or item’s rating patterns based on the data from the ratings prediction data model, which is built and updated during the learning phase of the algorithm. These patterns are used to make predictions for the real data [1,3].
Compared to the memory-based algorithms, there’re the number of benefits using SVD++ algorithm such as the better handling of sparse matrices compared to the memory-based algorithms. This, in turn, has a large impact on the scalability of the following algorithm while processing the huge datasets. Also, it benefits in a better prediction performance compared to such algorithms as k-nearest neighbors, k-means clustering, etc. [1,3]
Finally, the family of SVD algorithm has become very popular in the field of collaborative filtering. The winning entry for the famed Netflix Prize had a number of SVD models including SVD++ blended with Restricted Boltzmann Machines (RBM). By using the SVD++ algorithm they achieved a 10 percent increase in accuracy over Netflix's existing algorithm [3].
In this article, we'll discuss about the SVD++ algorithm based on the example of predicting ratings for the number of articles published in a social media website and advertised to a community of readers.
Background
The Users-To-Items Ratings Prediction Data Model
As we’ve already discussed, a recommendation engine normally uses the collaborative filtering (CF) approach to perform the collection of statistical data on the responses given by particular readers (i.e. users) to the typically huge domain of articles (i.e. items). These statistical data normally consist of the ratings given by users to items as well as the comments that describe each item being rated. These data, including the dependencies between particular users and items they’ve rated, are explicitly stored into the recommendation database [1].
To predict the new ratings for the unrated items by using SVD++ data mining algorithm being discussed, first what we actually need is to retrieve those datasets from the recommendation database and build a matrix of ratings, in which each user corresponds to a specific item being rated. The following matrix of ratings is illustrated by the Fig.1a shown below:

Practically, these datasets retrieved from the recommendation database are typically incomplete since not all users actually provide specific comments or ratings to each article they’ve viewed. Since that, our matrix of ratings we’ve obtained is a sparse matrix containing unknown ratings for the number of items. As it’s shown on Fig.1a. the unknown ratings are denoted as “?” [1,3].
Also, as we might have noticed, the matrix of ratings being discussed is actually suffering from the lack of data that would fully describe each rating given to a specific item by a user. Also, the following matrix doesn’t exhibit any data on the similarity of users and items, the “positive” or “negative” sides of each particular item that normally have a large impact on the correct ratings prediction. The main reason why those data are missing is that the most of those effects mentioned above can be thought or observed, but never could be estimated in the terms of algebra [1,3].
That’s actually why, the SVD++ data mining algorithm, while predicting ratings, basically relies solely on using the existing data provided by the matrix of ratings. By observing the matrix of ratings shown on Fig.1a. we might notice that there’re at least three effects that are exhibited on the data provided by this matrix [1]:
-
The first effect, that has an influence on the ratings prediction, is obviously the “average rating”. It allows us to determine how the entire domain of items has ever been rated since the time the statistical data on particular user and items was collected;
-
The second effect is the set of ratings that were given to the number of items by a single user that represents the tendency of a user to give the either “positive” or “negative” ratings;
-
The third effect is the set of ratings that were given to an item in the past. This effect, in turn, is closely related to the popularity and interest to an item;
Unlike the other effects such as similarity of users and items, these three effects can be formulated as the number of parameters representing them algebraically. The following effects are shown on Fig.1b below:

Those parameters serve as the main building blocks for the ratings prediction data model that we will use along with the SVD++ data mining algorithm, which we will thoroughly discuss in the one of the next sections below [1,3].
In the next sections of this article, we’ll discuss how to estimate the new ratings for the unrated items by using those parameters such as the average rating, baseline predictors and factorization vectors that represent the different effects of either user or item exhibited on the data retrieved from the matrix of ratings [1,3,5].
Baseline Predictors
To predict ratings, the data on the various effects are normally represented as a set of parameters which values describe a user’s rating behavior or popularity of an item influenced by the number of factors that are very specific to the entire domains of users or items. These parameters are typically called “baseline predictors”. According to SVD++ data mining algorithm, to predict ratings, we’ll basically deal with two types of baseline predictors \(b_i^U\) and \(b_j^I\) that represent those rating-specific effects for each user \(i\) and item \(j\) respectively. In the most cases, those baseline predictors are normally used as the parameters of baseline estimate formula [1,3,4,5].
The “baseline estimate”, by its definition, is the magnitude that typically consists of the overall average rating denoted by \(\mu\) and baseline predictors \(b_i^U\) and \(b_j^I\) of either a user \(i\) or an item \(j\). The very basic representation of the baseline estimate is the sum of those parameters, which can be formulated as follows:
, where \(\mu -\) the overall average rating of all items, \(b_{i}^{U} -\)baseline predictor of user \(i\), \(b_{j}^{I} -\)baseline predictor of item \(j\). The baseline estimate is the basic formula by using which we account the ratings of items being predicted based on different effects of either user or item. The sets of values of baseline predictors for each user or item are represented as the two vectors \(b^{U} \) and \(b^{I} \)respectively.
The sum of baseline predictors is normally interpreted as the standard deviation \(b_{i}^{U} +b_{j}^{I}\) from the overall average rating \(\mu \). The standard deviation is the magnitude the value of which largely depends on the number of either user's or item's effects influenced by the various of factors such as the criticism of a user or popularity of an item, etc. For example, suppose we need to predict the rating for an article \(j\) the popularity of which is higher by \(b_{j}^{I} =+0.78\) than average \(\mu =3.24\), rated by a user \(i\) who tends to rate the other of articles lower by \(b_{i}^{U} =-0.32\) than the average. Let's compute the predicted rating value by using baseline estimate formula (1): \(b_{i,j} =3.24-0.32+0.78=3.7\). Obviously, that, the predicted rating \(b_{i,j} =3.7\), which is higher than the average rating [1,3,4,5].
As it might seem from the very beginning, besides the baseline estimate, there could be also the other approaches for computing the predicted ratings given to items by users. Particularly, you might also think that we can compute the average rating for all items and then subtract that value from each item's rating. But, that's not true [1,3,4,5].
Instead, to efficiently predict the new ratings, we have to minimize the prediction error by obtaining such values of \(\mu \), \(b_{i}^{U} \), \(b_{j}^{I} \) for which baseline estimate \(b_{i,j} \) gives the best approximation on the existing ratings.
Also, there's the number of methods that allow to approximate those values including ordinary least squares (OLS), stochastic gradient descent (SGD), etc., which we'll more closely discuss in one of the next sections of the following article.
As we already know, the baseline estimate formula (1) is the sum that consists of such magnitudes as the average rating \(\mu \) or baseline predictors \(b_{i}^{U} \)and \(b_{j}^{I} \), each one is representing a particular effects specific to a user \(i\) or item \(j\). According to the basic ideas of ratings prediction by using baseline estimate, the total number of parameters representing the different user's and item's effects can be optional \(b_{i,j} =\mu +b_{i}^{U} +b_{j}^{I} +....\) . It means that, we might also want to add more parameters representing specific effects such as similarity of specific users and items to the baseline estimate formula (1) to provide a better predicted ratings approximation. To do this, we need simply add the values of those parameters to the sum of the existing values of the average rating and baseline predictors [1,3,4,5].
Normally, baseline predictor \(b_{i}^{U} \) of user \(i\) as well as baseline predictor \(b_{j}^{I} \) of item \(j\) describe slightly different effects. In the other words, both a user's and an item's baseline predictors values describe the effects that are not logically interrelated. For example, the user's baseline predictor is used to estimate the tendency of a user to give higher or lower ratings, while the value of item's baseline predictor normally represents an effect of what ratings are typically given to a specific item in the past. According to this fact, the SVD++ data mining algorithm that uses baseline estimate might not simply ``converge'', preventing us from obtaining the desired ratings approximation. The ``convergence'' is a phase at which the following algorithm gives the best approximation on the data model previously discussed [1,3,4,5].
Similarly, we've got the same case if the most of users haven't given any ratings and our matrix of ratings we've previously discussed is a sparse matrix. For example, if a specific user has rated just one item out of 5, then it's very hard to estimate the effect of how the following user would rate the rest of items and represent it as a single value of a user's baseline predictor. In turn, the effect of what ratings were previously given to an item doesn't describe the rating behavior of a user that rates the following item, and vice versa [1,3,4,5].
In general, the assumption that a new rating could be represented by the number of existing ratings given by a user for the most commonly rated items is hardly justified. In turn, it's also hard to justify that a new rating given to an item could be estimated solely based on the ratings given to this item by different users in the past. Moreover, the values of baseline predictors \(b_{i}^{U} \) and \(b_{j}^{I} \), that serve as ``biases'' for the domains of users and items with the various of different effects could scarcely be adjusted since the most of those effects can be determined experimentally rather than expressed in the terms of algebra. Most of those effects are not obvious, which actually means that we might reveal and distinguish those effects, but cannot estimate their impact on the ratings prediction. For example, it's very hard to represent the similarity of certain users and items as a value of a certain parameter that we normally use to estimate the ratings being predicted [1,3,4,5].
The SVD++ data mining algorithm, when used to predict the new ratings, actually suffers from such issues as the inability to estimate the new ratings particular ratings were already given to the number of other similar items [1,3,4,5].
In the next section, we'll discuss about how to improve the baseline estimate by using the user's and item's factorization vectors with the baseline estimate formula.
User's and Item's Factorization Vectors
As we've already discussed, the ratings being predicted basically depend on the diversity of various either user's or item's effects such as the individual rating behaviors of each user as well as popularity specific to each item being rated. Normally it's very hard to predict ratings based on those effects since they're represented as single scalar values of parameters such as baseline predictors \(b_{i}^{U}\) and \(b_{j}^{I} \) included in the baseline estimate. The single scalar values of those parameters cannot fully explain the variety of different effects for the typically large number of users or items. Since that, the values of these parameters that serve as ``biases'' cannot be properly adjusted to provide a desired approximation when predicting ratings [1,3,4,5].
That's why, to provide a convergence of the SVD++ mining algorithm as well as the desired approximation of the new ratings, being predicted, we need to add two factorization vectors \(\overline{u_{i} }=\{ u_{0} ,u_{1} ,u_{2} ,...,u_{k-1} ,u_{k} \} |\overline{u_{i} }\in R^{k} \) and \(\overline{v_{j} }=\{ v_{0} ,v_{1} ,v_{2} ,...,v_{k-1} ,v_{k} \} |\overline{v_{j} }\in R^{k} \) as the parameters of the baseline estimate formula (1) discussed above. The Fig.2. illustrates the matrix of ratings in which each user or item is associated with a particular factorization vector \(\overline{u_{i} }\) or \(\overline{v_{j} }):

Since that, the effects specific to a user including the user's rating behavior as well as an item's effects such as the popularity of an item are represented in the form of two \(k-\) dimensional vectors of latent factors. The vector \(\overline{u_{i} }) normally consists of the latent factors that mostly describe the affinity of user \(i\) to different effects such as the tendency to give higher or lower ratings to popular items. At the same time, vector \(\overline{v_{j} }\) contains those latent factors that can be interpreted as a popularity of an item \(j\), belonging to the group of items having similar features and so on. By using factorization vectors, we actually map each user or item to the latent space of factors. The multiple of those vectors for each user or item are typically represented as the two factorization matrices \(\overline{\overline{U}} \) and \(\overline{\overline{V}} \)respectively [1,3,4,5].
By adding the factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) to the baseline estimate formula, we actually perform the decomposition of those parameters which scalar values represent particular effects of either user or item. The components of those factorization vectors are actually the sets of biases by adjusting the values of which we actually define the affinity of a certain user or item to a specific effect. By doing this, we actually identify the users and items with related effects by performing the distance-based approximation of these two vectors of latent factors specific to a particular user and item. Since the most of users and items effects represented by a set of latent factors that cannot be logically explained, the ratings prediction for the new users and items turns to be a non-linear problem [1,3,4,5].
The technique of using factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) to provide a better approximation to the ratings prediction originates from the conventional SVD algorithm, in which those factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) are eigenvectors, that form an orthonormal basis. The approximated distance between each user's and item's vectors basically represents the similarity between user and item explained by those latent factors. This typically done by performing the low-rank matrix of ratings approximation, reducing the dimensionality of the latent space of users and items factors. The dimensionality of such latent space of factors is normally reduced by decomposing the matrix of ratings into the two matrices that consist of either ``left'' or ``right'' singular orthogonal vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\), as well as the diagonal matrix, which contains the eigenvalues \(\delta _{i,j} \) that reside on the diagonal of that matrix. Actually, while reducing the dimensionality, we're interested in only those orthogonal vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\), that exactly correspond to the eigenvalues having maximum values. Each eigenvalue can be represented as the inner product of those vectors: \(\delta _{i,j} =\sum _{i,j\in D}u_{i} v_{j}^{T} ) [6,7,8,9]\).
However, the using of conventional SVD algorithm with ratings matrices having over 55% of sparsity leads to the undefined prediction results since the almost a half of ratings is unknown. Unfortunately, the singular values decomposition cannot be found when a matrix of ratings is incomplete (e.g. doesn't contain all ratings) [1,3,4,5].
To predict ratings we'll normally approximate those factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) , and then compute the inner product of these vectors \(\overline{u_{i} v_{j}^{T} }\) which we will then add to the sum of average rating value and the values of baseline predictors according to the baseline estimate formula listed above [1,3,4,5].
Since that, let's complete the baseline estimate formula by transforming it into the generalized formula which we'll use in the SVD++ data mining algorithm being discussed to compute the predicted ratings values:
, where \(\mu -\) the overall average rating of all items, \(b_{i}^{U} -\)user's baseline predictor, \(b_{j}^{I} -\)item's baseline predictor, \(\overline{u_{i} v_{j}^{T} }-\)the inner product of the two factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\).
As well as the baseline predictors, the inner product of the either user's or item's factorization vectors is a scalar value that serves as the deviation of the average rating magnitude. There's the number of approaches that allow us to find the predicted ratings by using this formula which we'll thoroughly discuss in the next two sections of the following article.
Ordinary Least Squares Method (OLS)
In this section, we'll discuss about how to predict ratings by harnessing the SVD++ data mining algorithm based on the data retrieved from the matrix of existing ratings. Obviously, that, the new ratings values are computed by using the formula (2). For that purpose, everything what we actually need is the values of such parameters as the average rating of the entire domain of items \(\mu \), baseline predictors \(b_{i}^{U} \) and \(b_{j}^{I} \) , and factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\). The main problem that prevents us from the correct ratings prediction is that the values of these parameters are undefined for all unrated items, and the matrix of ratings doesn't contain any explicitly provided data on the either users or items being rated [1,3,4,5].
According to the basic ideas of the SVD++ data mining algorithm being discussed to obtain the values of those parameters and compute the new ratings we simply have ``train'' our ratings prediction data model based on the values of such parameters as the average rating \(\mu \), baseline predictors \(b_{i}^{U} \) and \(b_{j}^{I} \) and factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\). During the learning phase, we normally update the values of the average rating, baseline predictors and factorization vectors for the existing ratings to minimize the prediction error accuracy, until we've found such values of these parameters that will provide the best approximation for the new ratings being predicted [1,3,4,5].
The error accuracy minimization is typically done by using ordinary least squares (OLS) method. The following method is actually used to find the unknown values of the parameters in the linear regression represented as the baseline estimate by minimizing the sum of squares of differences between the observed responses such as the existing ratings given to the items retrieved from the matrix of ratings and those ratings that are computed by using formula (2), sum of the explanatory parameters values of which we're about to approximate. The magnitude of the difference between the existing and estimated ratings is typically the standard error deviation denoted by \(\varepsilon \).
In particular, to find the standard error deviation value \(\varepsilon \) , we have to compute the new value of rating \(\stackrel{\frown}{r}_{i,j} \) for each combination of user and item by using formula (2) and then subtract it from the value of the existing rating \(r_{i,j} \) for the current user and item retrieved from the matrix of ratings:
Then we'll use this value to update the values of those parameters to provide the best approximation for each rating being predicted. To do this, we actually need to minimize the sum of the error squares \(\varepsilon ^{2} \) for the entire domain of ratings:
According to the formula , we need to find such objective linear function, for which the sum of error deviations tends to the minima. In the other words, we must obtain such values of (\(\mu , b_{i}^{U} , b_{j}^{I} ,u_{i} ,v_{j} \)) explanatory parameters for which the sum of error squares is the smallest. The best way to do it is to use the stochastic gradient descent (SGD) discussed in the next section of the following article [1,3,4,5].
Regularization and Overfitting
Let's spend a moment and see what actually happens if we use this formula (3) to train our ratings prediction data model by performing the trivial linear regression? As we've already discussed, we normally are aiming to find such values of the explanatory parameters (\(\mu,b_{i}^{U},b_{j}^{I},u_{i},v_{j}\)) which allow us to find the linear function that would minimize the following sum of squares. According to the SVD++ data mining algorithm, that will be discussed later on, we'll simply adjust (or just ``fit'') the values of these parameters, by performing the gradient descent, iteratively, within a certain number of ``epochs'', until we've finally obtained the desired value of the error deviation since the following sum of squares is the smallest [1,3,4,5].
As we might notice, during each ``epoch'' the absolute values of these parameters will gradually increase until the sum of error squares becomes equal to zero. In this case, we deal with the linear regression of the large number of parameters, which is typically easy to train. The linear regression like that normally provide the best approximation for the minima number of iterations. The process of fitting the explanatory parameters values within a particular number of iterations (i.e. ``epochs'') causes the ratings prediction data model itself to saturate with typically large values and at the same time lose the ``power of prediction'' (e.g. fail to provide the correct results while predicting the new ratings). This is typically called an ``overfitting'' [1,3,4,5].
Normally, to predict the correct ratings we need to provide mechanism that allows to avoid the saturation of the explanatory parameters with typically huge values by simply adding a ``noise'' effect to the objective linear function. The following ``noise'' effect is applied proportionally to the value of the objective function as the values of those explanatory parameters increase. In the other words, the ``noise'' effect is the magnitude of the ascending gradient which is inverse proportional to the value of the descending gradient of the objective function: the higher values of the explanatory parameters, - the more ``noise'' effect we must add to the value of the objective function. The following process is normally called a ``regularization'':
Stochastic Gradient Descent (SGD)
As we've mentioned above, the SVD++ data mining algorithm is mainly based on the stochastic gradient descent (SGD) method that allows us to approximate the parameters values of the baseline estimate to predict the new ratings for the unrated items. This is typically done by iteratively updating the values of such parameters within the number of epochs, until the following algorithm has converged and gives the best approximation of those parameters, which, in turn, provides the correct ratings prediction of the unrated items. The basic idea of performing the stochastic gradient descent is that we are actually adjusting the values of those parameters by moving toward the direction opposite to the direction of the actual gradient. This is also called an ``anti-gradient''. The entire stochastic gradient method could be represented by the following formula:
, where \(w-\)a parameter of the linear objective function \(E(w)\), the value of which is to be adjusted; \(\eta -\)speed of the gradient descent being performed;
The main algebraic sense of this formula is that we actually obtain the gradient of the objective linear function \(\nabla E(w^{(0)})\) and multiply it by the actual speed of the gradient descent and, then, subtract this value from the current value of the parameter \(w^{(0)}\) to get the new adjusted value of the following parameter \(w^{(1)}\).
Specifically to the SVD++ data mining algorithm we'll need to obtain the gradient of the objective linear function from the formula (3), and, then, add it to the stochastic gradient descent formula (5), which we'll use to approximate the values of those explanatory parameters. Obviously that, to compute the gradient of the objective linear function we'll have to obtain the partial derivatives for each parameter of this function [1,3,4,5].
At this point let's get back to the discussion of the ordinary least squares (OLS) method. As we've already discussed, we must find such linear objective function that would normally allow us to minimize of the sum of error squares from the formulas (3,4):
Now, let's take a closer look to our objective function itself. As you might notice the following function is the function of multiple parameters. Obviously that, those parameters normally represent the average rating \(\mu \), baseline predictors \(b_{i}^{U} \) and \(b_{j}^{I} \), factorization vectors \(u_{i} \) and \(v_{j} \) previously discussed. To obtain such values of these parameters for which the sum of error squares for the entire domain of ratings will be the minima, we actually have to find the extrema (i.e. the smallest value) of the following function \(E(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})=0\). Now, let's spend a moment to see how we can actually find this extrema. According to this method we'll simply compute the gradient of this function, which is normally represented as the set of partial derivatives for each parameter of this function \(\nabla E=(\frac{\partial E}{\partial \mu } ;\frac{\partial E}{\partial b_{i}^{U} } ;\frac{\partial E}{\partial b_{j}^{I} } ;\frac{\partial E}{\partial u_{i} } ;\frac{\partial E}{\partial v_{j} } )\). To do that, we'll just find the partial derivatives for each of these parameters. As we've already noticed from the formula (6), the following objective function consists of the sum of two expressions. The first expression is the sum of error squares, while the second one is the expression that actually adds ``noise'' effect to the following sum of squares. That's why, to simplify the obtaining of the gradient for the entire formula (5), we normally split up the following function into small functions of either \(L(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) or \(W(\lambda ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) as follows:
The gradient of the function \(\nabla E(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) is now represented as the sum of the gradients of the following functions \(L(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) and \(W(\lambda ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\):
To demonstrate how to obtain those partial derivatives, let's find the partial derivative at least for the first trivial parameter \(b_{i}^{U} \) that represents the baseline predictor of a user \(i\):
As we might notice from the formula (6.4) \(L(\mu ,b_{i} ,b_{j} ,u_{i} ,v_{j})\) is a composite function, to find partial derivatives of which we'll be using the chain rule which allows us to decompose the derivative of this function into the product of two derivatives, that we'll be finding separately:
By using the chain rule, we'll express our partial derivative of the following function via the derivative of another parameter \(\varepsilon _{i,j} =r_{i,j} -(\mu +b_{i}^{U} +b_{j}^{I} +u_{i}v_{j}^{T})\), which actually presents the magnitude of the error deviation thoroughly discussed in the one of the previous section of this article. As the result of performing particular algebraic transformations we'll obtain the partial derivative of the function \(L(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) for the parameter )(b_{i}^{U} \):
Similarly, we'll obtain the partial derivative of the function \(W(\lambda ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) for the parameter \(b_{i}^{U} \):
Now, let's sum up those parts of the formula (6.3) to obtain the gradient of the objective linear function \(\nabla E(\mu ,b_{i}^{U} ,b_{j}^{I} ,u_{i} ,v_{j})\) as follows:
Further, we'll use the similar technique to obtain the partial derivatives for the rest of the parameters of the objective linear function \(\nabla E(\mu ,b_{i} ,b_{j} ,u_{i} ,v_{j})\), which we'll discuss below, in the next paragraphs of this section.
Since we've found the gradient of the objective linear function by obtaining the partial derivatives for all parameters of this function, now let's apply those partial derivatives to the stochastic gradient formula (5) for each parameter of the objective function:
Now, let's take a look at what formulas we've actually obtained. Each one of the following formulas (7.1-5) is used to adjust (or ``update'') each of the explanatory parameters of the ratings prediction data model during the SVD++ algorithm's learning phase discussed in the next section of the following article. By using those formulas we'll actually perform the stochastic gradient descent until we've provided the convergence and the desired approximation of the data model we're about to train during the learning phase. The best approximation of the following data model normally ensures that we'll compute (i.e. predict) the correct new ratings for the unrated items [1,3,4,5].
At this point, let's discuss about the algebraic sense of those formulas above. Each one of these formulas is derived from the stochastic gradient descent formula discussed at the top of the following section. According to the main idea of the stochastic gradient descent we normally approximate the value of a certain parameter in the direction opposite to the gradient of a certain objective linear function. That's actually why the value of the gradient is subtracted from the current value of this parameter to perform the following parameter's value update. The main difference between the conventional SGD formula and the set of formulas we've obtained is that, in this particular case, the value of the gradient of our objective linear function is added to the value of each parameter [1,3,4,5].
We normally use the first two formulas to update the values of the baseline predictors (\(b_{i}^{U}, b_{j}^{I} \)) that represent the either users or items effects, which values implicitly obtained while processing the matrix of ratings. We're performing an update until we find such values of the baseline predictors for user \(i\) and item \(j\)that give the correct approximation of the standard deviation from the average rating \(\mu \). Fig 3a illustrates the baseline predictors update process:

The special interest is the two last formulas (7.4) and (7.5) by using which we update the latent factors represented by the factorization vectors (\(\overline{u_{i} }, \overline{v_{j} }\)). Unlike those formulas by using which we update the scalar values of the average rating and baseline predictors, the following formulas are used to update the entire vectors of either user's or item's latent factors. These formulas are actually used to update the value of each latent factor which is the component of a particular factorization vector. When dealt with these formulas, we actually perform the scalar multiplication of each component of these vectors by the scalar value of error \(\varepsilon _{i,j} \) and regularization coefficient \(\lambda \). As the result we obtain the updated factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\). Fig 3b. illustrates the using of formulas (7.4) and (7.5) to update the sets of values of the latent factors represented by the either user's and item's factorization vectors:

By performing the update of factorization vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) we're actually approximating the distance between those vectors which depends on the value of error \(\varepsilon _{i,j} \). The following distance is actually the similarity of a particular user and item according to the specific effects that are represented by those explanatory parameters which values are decomposed into the sets of latent factors [1,3,4,5].
SVD++ Data Mining Algorithm Essentials
In the previous sections of this article, we've thoroughly discussed about the mathematical model of the SVD++ data mining algorithm. Now it's time to discuss about the essentials of the SVD++ algorithm itself.
The SVD++ algorithm, according to its nature, is the AI data mining algorithm that normally consists of the two main phases: the ``learning'' phase during which we're actually performing the ``offline'' training of our ratings prediction model, as well as the computational phase, at which we'll actually compute (i.e. predict) the new ratings for the multiple of unrated items in the matrix of ratings [1,3,4,5].
Initialization
The very first step of the SVD++ algorithm is the initialization phase. During this phase we'll assign the initial values to the ratings prediction data model. Let's take time to see what particular values will be assigned to the components of vectors of the either users or items baseline predictors \(\overline{b^{U} }\) and \(\overline{b^{I} }\). Those vectors are typically initialized with zero values \(\overline{b^{U} }=\{ 0\} , \overline{b^{I} }=\{ 0\} \) since we don't initially have any ``implicit'' data on the either users or items effects. Another case is the initialization of the factorization matrices \(\overline{\overline{U}} \) and \(\overline{\overline{V}} \)that consist of multiple vectors \(\overline{u_{i} }\) and \(\overline{v_{j} }\) of the latent factors for each user and item. As we've already discussed, prior to the learning phase, the initial values of the latent factors are typically undefined. To avoid the ``cold start'' problem, according to the SVD++ algorithm, the only what we have to do is to initialize the first components \(u_{0,0} \) and \(v_{0,0} \) of those factorization vectors for the first user \((i=0)\) and item \((j=0)\) respectively with two arbitrary values of 0.1 and 0.05:\(u_{i,j} \leftarrow 0.1\)\(v_{i,j} \leftarrow 0.05|i,j=0\).
After we've initialized the baseline predictors and factorization vectors we also have to compute the average rating for the entire domain of items. We normally compute the average rating only for those items for which the value of rating already exists in the matrix of ratings: \(\mu \leftarrow AVG[r_{i,j} ]|\forall r_{i,j} \ne -1\). Optionally, we can initialize the average rating variable \(\mu \) with the value of the lowest possible rating. To compute the average rating for all items, for which the value of rating already exists we have to iterate through the matrix of ratings and for each rating to perform a check if the rating for this particular item already exists. If so, we add the value of the current existing rating to the value of the variable that is used to store the sum of all existing ratings. Also, we have to increment the loop counter variable used to store the value of actual number of existing ratings. Finally, we have to divide the sum of all existing ratings by the value of their actual count to obtain the value of average rating [1,3,4,5]. The block diagram shown on Fig. 4 illustrates the following algorithm:

Since the ratings prediction model of the SVD++ algorithm has the number of parameters that represent particular features of this model such as the learning speed \(\eta \) and regularization coefficients \(\lambda _{1} \) and \(\lambda _{2} \), we also have to assign the initial values to those parameters prior to the learning phase of the SVD++ algorithm [1,3,4,5].
The Learning Phase
At this point, let's take a closer look at the ``learning'' procedure itself. Similarly to the most of the existing AI data mining and genetic algorithms, before we compute the new ratings for the unrated items, we initially have to train our ratings prediction data model on the typically large amount of training samples (i.e. existing ratings) within a certain number of epochs. According to the basic ideas of the SVD++ algorithm we'll actually update the value of the average rating \(\mu \), baseline predictors (\(b_{i}^{U}, b_{j}^{I} \)) and factorization vectors (\(\overline{u_{i} }, \overline{v_{j} })\) using the formulas (7.1-5) by performing the stochastic gradient descent until the algorithm has converged and, thus, provides the best approximation of the new ratings being predicted [1,3,4,5].
According to the SVD++ algorithm, during the ``learning'' phase we'll iterate through the matrix of ratings and for each existing rating \(r_{i,j} \) given to the item \(j\) by user \(i\) , we'll perform the following steps to actually update the values of those explanatory parameters (\(\mu , b_{i}^{U}, b_{j}^{I}, u_{i}, v_{j}\)) of the baseline estimate in order to minimize the value of the sum of error \(\varepsilon _{i,j}^2\) for the entire domain of items:
- Compute the “so-far” estimated value of rating \(\stackrel{\frown}{r}_{i,j} \) by using formula (2): \(\stackrel{\frown}{r}_{i,j} =\mu +b_{i}^{U} +b_{j}^{I} +\overline{u_{i} v_{j}^{T} }\);
- Find the error value by subtracting the value of the estimated rating \(\stackrel{\frown}{r}_{i,j}\) obtained at the previous step from the value of the existing rating as follows: \(\varepsilon _{i,j} =r_{i,j} -\hat{r}_{i,j} \);
- Compute the square of the error value \(\varepsilon _{i,j}^{2} \) obtained at the previous step and add this value to the sum of error squares;
- Perform an update of the current value of the average rating: \(\mu =\mu +\eta(\varepsilon _{i,j} -\lambda \mu)\)
- Perform an update of the current value of baseline predictor of user \(i\): \(b_{i}^{U} =b_{i}^{U} +\eta (\varepsilon _{i,j} -\lambda b_{i}^{U})\);
- Perform an update of the current value of the baseline predictor of item \(j\): \(b_{j}^{I} =b_{j}^{I} +\eta (\varepsilon _{i,j} -\lambda b_{j}^{I})\);
- Perform an update the value of each latent factor in the factorization vector of user \(i\): \(u_{i} =u_{i} +\eta(\varepsilon _{i,j} v_{j}^{T} -\lambda u_{i})\);
- Perform an update the value of each latent factor in the factorization vector of item \(j\): \(v_{j}^{T} =v_{j}^{T} +\eta (\varepsilon _{i,j} u_{i} -\lambda v_{j}^{T})\);
Normally, we'll iteratively proceed with the ``learning'' procedure during each epoch until the following algorithm has converged. The convergence of the following algorithm is basically determined by computing the root mean square error (RMSE), which is estimated as the square root of the sum of error \(\varepsilon _{i,j}^2 \) obtained at the step 3, divided by the number of training samples \(N_{i} \) we've used: \(RMSE=\frac{1}{N_{t} } \times \sqrt{\sum _{i,j\in D}\varepsilon _{i,j}^{2} } \). Normally, we compute the square of the error value \(\varepsilon _{i,j}^{2} \) for each particular existing rating from the matrix of ratings and, then, add this value to the total value representing the sum of such error squares. Since we've obtained the value of the sum of error squares, we compute the RMSE at the end of each epoch. At this point, we actually test if the following learning process has converged. This is typically done by computing the difference between the current root means square error value RMSE and the value of the root means square error obtained during the previous epoch of the learning phase. To compute this difference, we actually subtract the current value from the previous value of the RMSE: (RMSE-RMSE_NEW) > eps,\(eps > 10e-4\) . After that we're performing a check if the difference of these values is higher than the value of the \(eps) variable the represents the error's precision accuracy. If so, we proceed with the training in the next epoch during which we'll again perform the update of our ratings prediction data model for the entire domain of items. Otherwise, since the following value of difference resides in the neighborhood of the value of \(eps\), which means that the values of the sum of squares obtained during the current and previous epochs (i.e. iterations) are quite similar, we simply terminate the process of the data model training. In the other words, we normally proceed with the process of learning until the approximated value of RMSE is the same for each next learning epoch and no longer varies [1,3,4,5].
Moreover, there're special cases in which the learning phase of the SVD++ algorithm typically degrades as the result of such issues as the overfitting of the data model discussed above. In the other words, we might notice that the value of RMSE during each epoch of the learning phase actually fails to vary and the data model no longer gives the desired approximation of the new ratings being predicted [1,3,4,5].
In this case, the most efficient optimization of the SVD++ algorithm is to slow down the process of learning by decreasing the value of the learning speed parameter \(\eta \). This is typically done by verifying if the difference between the current and previous values of RMSE is exceeding a specific threshold. If so, we just multiply the value of parameter \(\eta \) by the value of specific coefficient which actually slows the process of learning. This, in turn, benefits in the fast convergence of the entire SVD++ algorithm [1,3,4,5]. The entire algorithm of the SVD++ learning phase is illustrated by the Fig. 5.:

Predicting Ratings
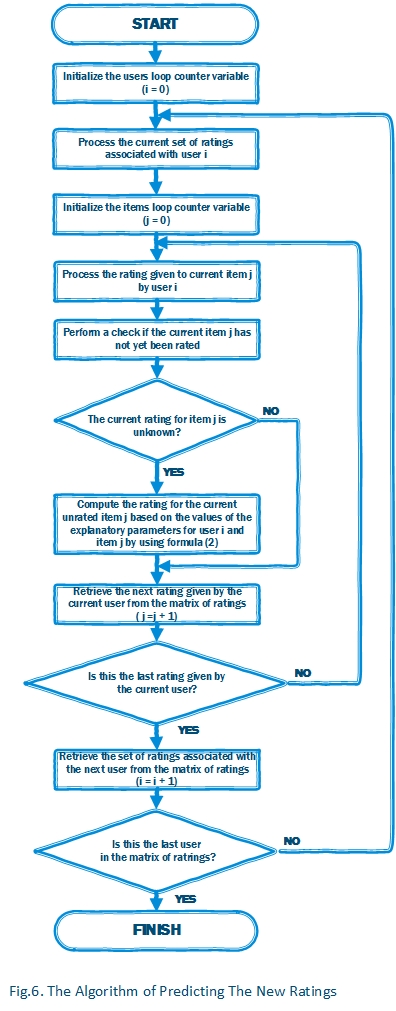
After we've trained our ratings prediction data model, now it's time to compute the values for each unknown rating. To do this, we need to iterate through the matrix of ratings and for each rating to perform a check if the current rating given to item \(j\) by user \(i\) is an unknown rating. If so, we use the formula (2): \(\stackrel{\frown}{r}_{i,j} =\mu +b_{i}^{U} +b_{j}^{I} +\overline{u_{i} v_{j}^{T} }\) to simply compute the value of the unknown rating. In this case, we're actually computing the value of rating of the unrated item using the values of the explanatory parameters for the current user \(i\) and item \(j\) obtained from our ratings prediction model and applied to the following formula. As the result of performing such computations, we'll obtain the value of estimated rating given to item to item \(j\) by user \(i\)[1,3,4,5].
The most efficient optimization of the rating prediction process is that we actually need to ``re-train'' the ratings prediction data model by performing the same learning procedure after each new rating computation. This, in turn, allows to improve the quality of prediction and at the same time avoid the ``cold start'' problem [1,3,4,5].
The algorithm of predicting ratings based on the ratings prediction data model is illustrated by Fig. 6.:
Evaluating SVD++ Algorithm
In this section of this article, we’ll discuss about how to use the SVD++ algorithm to produce recommendations based on the prediction of ratings given to the top 5 articles published in a social media website and has been rated by a community of users. As we’ve already discussed, the input dataset for the SVD++ algorithm is the matrix of articles ratings that looks like as follows:

Each row of the following matrix represents the set of ratings given to the number of articles by a particular user. As we’ve already discussed, each user has their own tastes and preferences exhibited on the data from the following matrix of ratings shown on Fig. 7. In turn, each article has a certain history of ratings given by the number of users in the past.
In this particular case, to demonstrate the articles ratings prediction performed by the code that implements the SVD++ algorithm, we’ve built the matrix that contains the ratings given by the “critical” user 4, as well as the ratings given by user 3, that tends to give only “positive” ratings to the most of the articles (e.g. is being a “generous” reader). Also, the following matrix of ratings contains the data on the other users that typically give the average ratings to the articles, they’ve viewed. Those “average” users are being a special case of interest since, to evaluate the quality of prediction of the algorithm being discussed, we basically aim to train the ratings prediction data model to predict ratings that the “average” users might want to give to the articles they’ve viewed.
We’ve purposely selected top 5 articles and divided it into two categories by the similarity of those articles. In this case, the first category includes the articles about C# programming, while the other category consists of the articles about programming in C++.
Now, let’s spend a moment to see how the “average” user 0 has rated the article “An advanced introduction to C#...” based on the results of ratings prediction obtained during the code execution. Obviously that, the predicted rating of the following article given by user 0 is 4.63 out of 5.00, since the user 0 has already positively rated the number of similar articles, as well as the average of the previous ratings for this particular article is normally 3.75. Obviously that the following article is recommended to the user 0.
Another special case is the rating given by user 2 to the article “A Tutorial on Nested Classes in C#”. As we can see from the matrix of rating shown above, the user 2 gave the similar ratings to the same articles as the user 0, but the average of the previous ratings of this article is 3.66 which is obviously lower than the average rating from the previous example. That’s actually why, the rating predicted for the following article is 3.90 is out of 5, which is lower by 0.73 than the rating predicted in the previous example. The following article is recommended to the user 2.
Using the code
The following fragment of code performs the initialization of the ratings prediction data model:
static void Initialize()
{
// Constructing the matrix of user's latent factors by iteratively
// appending the rows being constructed to the list of rows MF_UserRow
for (int User = 0; User < MatrixUI.Count(); User++)
{
// Declare a list of items MF_UserRow rated by the current user
List<double> MF_UserRow = new List<double>();
// Add the set of elements equal to 0 to the list of items MF_UserRow.
// The number of elements being added is stored in Factors variable
MF_UserRow.AddRange(Enumerable.Repeat(0.00, Factors));
// Append the current row MF_UserRow to the matrix of factors MF_User
MF_User.Insert(User, MF_UserRow);
}
// Constructing the matrix of item's latent factors by iteratively
// appending the rows being constructed to the list of rows MF_ItemRow
for (int Item = 0; Item < MatrixUI.ElementAt(0).Count(); Item++)
{
// Declare a list of items MF_ItemRow rated by the current item
List<double> MF_ItemRow = new List<double>();
// Add the set of elements equal to 0 to the list of items MF_ItemRow
// The number of elements being added is stored in Factors variable
MF_ItemRow.AddRange(Enumerable.Repeat(0.00, Factors));
// Append the current row MF_ItemRow to the matrix of factors MF_Item
MF_Item.Insert(Item, MF_ItemRow);
}
// Intializing the first elements of the matrices of user's
// and item's factors with values 0.1 and 0.05
MF_User[0][0] = 0.1; MF_Item[0][0] = MF_User[0][0] / 2;
// Construct the vector of users baseline predictors by
// appending the set of elements equal to 0.The number of elements being
// appended is equal to the actual number of rows in the matrix of ratings
BS_User.AddRange(Enumerable.Repeat(0.00, MatrixUI.Count()));
// Construct the vector of items baseline predictors by appending
// the set of elements equal to 0. The number of elements appended
// is equal to the actual number of rows in the matrix of ratings
BS_Item.AddRange(Enumerable.Repeat(0.00, MatrixUI.ElementAt(0).Count()));
}
The following function performs the ratings prediction data model training:
static void Learn()
{
// Initializing the iterations loop counter variable
int Iterations = 0;
// Initializing the RMSE and RMSE_New variables to store
// current and previous values of RMSE
double RMSE = 0.00, RMSE_New = 1.00;
// Computing the average rating for the entire domain of rated items
double AvgRating = GetAverageRating(MatrixUI);
// Iterating the process of the ratings prediction model update until
// the value of difference between the current and previous value of RMSE
// is greater than the value of error precision accuracy EPS (e.g. the learning
// process has converged).
while (Math.Abs(RMSE - RMSE_New) > EPS)
{
// Assign the previously obtained value of RMSE to the RMSE variable
// Assign the variable RMSE_New equal to 0
RMSE = RMSE_New; RMSE_New = 0;
// Iterate through the matrix of ratings and for each existing rating compute
// the error value and perform the stochastic gradient descent to update
// the main parameters of the ratings prediction model for the current user and item
for (int User = 0; User < MatrixUI.Count(); User++)
{
for (int Item = 0; Item < MatrixUI.ElementAt(0).Count(); Item++)
// Perform a check if the current rating in the matrix of ratings is unknown.
// If not, perform the following steps to adjust the values of baseline
// predictors and factorization vectors
if (MatrixUI[User].ElementAt(Item) > 0)
{
// Compute the value of estimated rating using formula (2)
double Rating = AvgRating + BS_User[User] +
BS_Item[Item] + GetProduct(MF_User[User], MF_Item[Item]);
// Compute the error value as the difference
// between the existing and estimated ratings
double Error = MatrixUI[User].ElementAt(Item) - Rating;
// Output the current rating given by the current user to the current item
Console.Write("{0:0.00}|{1:0.00} ", MatrixUI[User][Item], Rating);
// Add the value of error square to the current value of RMSE
RMSE_New = RMSE_New + Math.Pow(Error, 2);
// Update the value of average rating for the entire domain of ratings
// by performing stochastic gradient descent using formulas (7.1-5)
AvgRating = AvgRating + TS * (Error - L1 * AvgRating);
// Update the value of baseline predictor of the current user
// by performing stochastic gradient descent using formulas (7.1-5)
BS_User[User] = BS_User[User] + TS * (Error - L1 * BS_User[User]);
// Update the value of baseline predictor of the current item
// by performing stochastic gradient descent using formulas (7.1-5)
BS_Item[Item] = BS_Item[Item] + TS * (Error - L1 * BS_Item[Item]);
// Update each component of the factorization vector for
// the current user and item
for (int Factor = 0; Factor < Factors; Factor++)
{
// Adjust the value of the current component of the user's
// factorization vector by performing stochastic gradient
// descent using formulas (7.1-5)
MF_User[User][Factor] += TS * (Error * MF_Item[Item][Factor] +
L2 * MF_User[User][Factor]);
// Adjust the value of the current component of the item's
// factorization vector by performing stochastic gradient
// descent using formulas (7.1-5)
MF_Item[Item][Factor] += TS * (Error * MF_User[User][Factor] +
L2 * MF_Item[Item][Factor]);
}
}
// Output the value of unknown rating in the matrix of ratings
else Console.Write("{0:0.00}|0.00 ", MatrixUI[User][Item]);
Console.WriteLine("\n");
}
// Compute the current value of RMSE (root means square error)
RMSE_New = Math.Sqrt(RMSE_New / (MatrixUI.Count() * MatrixUI.ElementAt(0).Count()));
Console.WriteLine("Iteration: {0}\t RMSE={1}\n\n", Iterations, RMSE_New);
// Performing a check if the difference between the values
// of current and previous values of RMSE exceeds the given threshold
if (RMSE_New > RMSE - Threshold)
{
// If so, reduce the values of training speed and threshold
// by multiplying each value by the value of specific coefficients
TS *= 0.66; Threshold *= 0.5;
}
Iterations++; // Increment the iterations loop counter variable
}
}
The following fragment of code perform the predicted ratings computation:
public static void Predict()
{
// Computing the average rating for the entire domain of rated items
double AvgRating = GetAverageRating(MatrixUI);
Console.WriteLine("We've predicted the following ratings:\n");
// Iterating through the MatrixUI matrix of ratings
for (int User = 0; User < MatrixUI.Count(); User++)
for (int Item = 0; Item < MatrixUI.ElementAt(0).Count(); Item++)
// For each rating given to the current item by the current user
// we're performing a check if the current item is unknown
if (MatrixUI[User].ElementAt(Item) == 0)
{
// If so, compute the rating for the current
// unrated item used baseline estimate formula (2)
MatrixUI[User][Item] = AvgRating + BS_User[User] +
BS_Item[Item] + GetProduct(MF_User[User], MF_Item[Item]);
// Output the original rating estimated for the current item
// and the rounded value of the following rating
Console.WriteLine("User {0} has rated Item {1} as {2:0.00}|{3:0.00}", User,
Item, MatrixUI[User][Item], Math.Round(MatrixUI[User][Item]));
}
Console.WriteLine();
}
The following routine perform the two vectors inner product computation:
public static double GetProduct(List<double> VF_User, List<double> VF_Item)
{
// Initialize the variable that is used to
// store the inner product of two factorization vectors
double Product = 0.00;
// Iterating through the two factorization vectors
for (int Index = 0; Index < Factors; Index++)
// Compute the value of product of the two components
// of those vectors having the same value of index and
// add this value to the value of the variable Product
Product += VF_User[Index] * VF_Item[Index];
return Product;
}
The following fragment of code computes the average rating for the entire domain of items:
public static double GetAverageRating(List<list<double>> Matrix)
{
// Initialize the variables Sum and Count to store the values of
// sum of existing ratings in matrix of ratings and the count of
// existing ratings respectively
double Sum = 0; int Count = 0;
// Iterating through the matrix of ratings
for (int User = 0; User < Matrix.Count(); User++)
for (int Item = 0; Item < Matrix[User].Count(); Item++)
// For each rating performing a check if the current rating is unknown
if (Matrix[User][Item] > 0)
{
// If not, add the value of the current rating to the
// value of variable Sum
Sum = Sum + Matrix[User][Item];
// Increment the loop counter variable of existing ratings by 1
Count = Count + 1;
}
// Compute and return the value of average
// rating for the entire domain of existing ratings
return Sum / Count;
}
This code snippet is used to load matrix of ratings from a file:
public static void LoadItemsFromFile(string Filename, List<list<double>> Matrix)
{
// Intializing the file stream object and open the file
using (System.IO.FileStream fsFile = new System.IO.FileStream(Filename,
System.IO.FileMode.Open, System.IO.FileAccess.Read, System.IO.FileShare.Read))
{
// Initializing the stream reader object
using (System.IO.StreamReader fsStream = new System.IO.StreamReader(
fsFile, System.Text.Encoding.UTF8, true, 128))
{
string textBuf = "\0";
// Retrieving each line from the file until we reach the end-of-file
while ((textBuf = fsStream.ReadLine()) != null)
{
List<double> Row = new List<double>();
if (!String.IsNullOrEmpty(textBuf))
{
string sPattern = " ";
// Iterating through the array of tokens and
// append each token to the array Row
foreach (var rating in Regex.Split(textBuf, sPattern))
Row.Add(double.Parse(rating));
}
// Append the current row to the matrix of ratings
Matrix.Add(Row);
}
}
}
}
Output
The code being discussed in this article produces the following output based on the matrix of ratings loaded from the RATINGS.TXT file. Firstly, the following code outputs the original matrix with unknown ratings denoted as (???). After that, the following code performs the training of the ratings prediction data model. During the learning phase it outputs the matrix of the existing and approximated ratings, in which both existing and approximated rating values are delimited by "|" character. Each block of the output is produced for each iteration (i.e. "epoch") of the learning phase. At the bottom of each block, the code listed above normally prints the number of iteration (i.e. "epoch") and the value of RMSE (root mean square error) for the current iteration as it's shown on Fig. 8:

Matrix of ratings given to items by users
??? 3,00 4,00 5,00 2,00
3,00 5,00 2,00 2,00 5,00
5,00 3,00 ??? 4,00 3,00
5,00 5,00 5,00 ??? 5,00
2,00 3,00 ??? 2,00 2,00
0,00|0.00 3,00|3,57 4,00|3,54 5,00|3,57 2,00|3,64
3,00|3,56 5,00|3,52 2,00|3,62 2,00|3,56 5,00|3,41
5,00|3,53 3,00|3,64 0,00|0.00 4,00|3,58 3,00|3,61
5,00|3,58 5,00|3,64 5,00|3,67 0,00|0.00 5,00|3,75
2,00|3,75 3,00|3,65 0,00|0.00 2,00|3,58 2,00|3,51
Iteration: 0 RMSE=1,16542197178961
0,00|0.00 3,00|3,57 4,00|3,54 5,00|3,51 2,00|3,57
3,00|3,55 5,00|3,53 2,00|3,58 2,00|3,51 5,00|3,42
5,00|3,57 3,00|3,65 0,00|0.00 4,00|3,55 3,00|3,58
5,00|3,72 5,00|3,76 5,00|3,76 0,00|0.00 5,00|3,78
2,00|3,55 3,00|3,50 0,00|0.00 2,00|3,41 2,00|3,37
Iteration: 1 RMSE=1,1079120145992
*************************************************
0,00|0.00 3,00|2,80 4,00|4,16 5,00|4,78 2,00|2,15
3,00|2,85 5,00|5,02 2,00|2,17 2,00|1,99 5,00|4,95
5,00|4,43 3,00|3,36 0,00|0.00 4,00|4,38 3,00|2,82
5,00|5,29 5,00|5,21 5,00|4,72 0,00|0.00 5,00|4,81
2,00|2,29 3,00|2,62 0,00|0.00 2,00|1,89 2,00|2,29
Iteration: 464 RMSE=0,235306704248189
0,00|0.00 3,00|2,80 4,00|4,16 5,00|4,78 2,00|2,15
3,00|2,85 5,00|5,02 2,00|2,16 2,00|1,99 5,00|4,95
5,00|4,43 3,00|3,36 0,00|0.00 4,00|4,38 3,00|2,82
5,00|5,29 5,00|5,21 5,00|4,72 0,00|0.00 5,00|4,81
2,00|2,29 3,00|2,62 0,00|0.00 2,00|1,89 2,00|2,29
Iteration: 465 RMSE=0,235296693918684
0,00|0.00 3,00|2,80 4,00|4,16 5,00|4,78 2,00|2,15
3,00|2,85 5,00|5,02 2,00|2,16 2,00|1,99 5,00|4,95
5,00|4,43 3,00|3,36 0,00|0.00 4,00|4,38 3,00|2,82
5,00|5,29 5,00|5,21 5,00|4,72 0,00|0.00 5,00|4,81
2,00|2,29 3,00|2,62 0,00|0.00 2,00|1,89 2,00|2,29
Iteration: 466 RMSE=0,235286707713274
We've predicted the following ratings:
User 0 has rated Item 0 as 4,63|5,00
User 2 has rated Item 2 as 3,90|4,00
User 3 has rated Item 3 as 4,98|5,00
User 4 has rated Item 2 as 1,69|2,00
The target matrix of ratings:
5,00 3,00 4,00 5,00 2,00
3,00 5,00 2,00 2,00 5,00
5,00 3,00 4,00 4,00 3,00
5,00 5,00 5,00 5,00 5,00
2,00 3,00 2,00 2,00 2,00
At the bottom of the output listed above the following code prints out the ratings that were predicted for particular users and items during the computation phase. Also it prints the matrix of ratings in which all missing rating were replaced with the values of ratings being predicted.
References
- Yehuda Koren. Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model. AT&T Labs – Research. © 2008;
- Rajeev Kumar, B. K. Verma, Shyam Sunder Rastogi. Social Popularity based SVD++ Recommender Systems. International Journal of Computer Applications (0975 – 8887). Volume 87 – No.14, February 2014;
- Stephen Gower. Netflix Prize and SVD. © April 18th 2014;
- Collaborative Filtering. From Wikipedia, the free encyclopedia https://en.wikipedia.org/wiki/Collaborative_filtering;
- Michael D. Ekstrand, John T. Riedl, Joseph A. Konstan. Collaborative Filtering Recommender Systems. Foundations and Trends® in Human–Computer Interaction Vol. 4, No. 2 (2010) 81–173. © 2011;
- Tianqi Chen, Zhao Zheng, Qiuxia Lu, Weinan Zhang, Yong Yu. Feature-Based Matrix Factorization. Apex Data & Knowledge Management Lab Shanghai Jiao Tong University. © 2011;
- Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. Incremental Singular Value Decomposition Algorithms for Highly Scalable Recommender Systems. GroupLens Research Group / Army HPC Research Center Department of Computer Science and Engineering University of Minnesota. © 2014;
- Serdar Sali. Using SVD to Predict Movie Ratings. Department of Computer Science, Jack Baskin School of Engineering at UC Santa Cruz, California, USA. © 2008;
- Alan Kaylor Cline, Inderjit S. Dhillon. Computation of the Singular Value Decomposition. The University of Texas at Austin. © 2006;
Points of Interest
The SVD++ AI data mining algorithm was the winning entry for the famous Netflix Prize. The using of SVD++ algorithm to predict movies ratings made it possible to improve the quality of prediction by ten percents compared to the most of the memory-based algorithms such as k-nearest neighbors and k-means clustering. Probably someone of enthusiasts will be able to improve the SVD++ algorithm to drastically increase the quality of prediction by more than ten percents compared to the algorithm discussed in this article.
History
- February 1, 2017 - The first revision of article was published