
Domain-Driven Design: Tactical Design Patterns. Part 2
5.00/5 (4 votes)
Knowing tactical design patterns within the DDD approach is as important as having a deep understanding of strategic design patterns. In this article, I explain everything you need to know about DDD's tactical modeling process.
In the previous article, I touched upon so-called strategic modeling and strategic design patterns within the DDD approach. I demonstrated how you could specify conceptual borders to solve specific tasks within the domain — bounded contexts.
To implement a specific bounded context, you need to rely on low-level tactical design patterns, which are used to solve specific engineering & development problems. These patterns are: Entity, Value Object, Domain Service, Domain Entity, Module, Aggregate, Factory, Repository. In this article, I am going to look into these patterns.
When the tactical design patterns are used correctly, you can use ubiquitous language in bounded context. The software design model that includes all the patterns needs to demonstrate how rich ubiquitous language is in a given context. If this or that DDD term can’t be described or expressed with the help of ubiquitous language, it shouldn't be used in the model. If the modeling is underway with use of tactical design patterns (without ubiquitous language), it means that so-called light DDD approach is used.
So, let’s have a look at several tactical design patterns in the order they are described in Vaughn Vernon’s “Implementing Domain-Driven Design.”
Entity
If any term in the domain is unique and differs from other objects in the system, we need to use entity to model it. These value objects may differ in form within a given lifecycle, and yet you should always identify and be able to find them using queries. For that end, you can rely on unique identifiers, which need to be created from the very beginning of the development process (when you develop entities).
There are several strategies you can use to create unique identifiers:
#1 Input of unique value by a user
Use this approach if you need your app’s identifiers to be easily readable. Here’s a thing, though: You need to make sure that all identifiers are checked for uniqueness and accuracy within the app itself. Moreover, implementing any changes to identifiers is costly, and users are not usually allowed to manipulate or change them. Therefore, you should rely on methods that guarantee the quality and consistency of every identifier.
#2 Identifier generation by an app
There are some fast and reliable generators that can be used to automatically generate unique identifiers. For instance, in Java we have the java.util.UUID class that allows you to generate universally unique identifiers using four different methods: time-based, DCE security, name-based, randomly generated UUIDs.
Here’s a UUID example:
046b6c7f-0b8a-43b9-b35d-6489e6daee91
(basically, a 36-byte string)
Long identifiers (like shown below) are hard to store due to memory overload. This is why, it makes sense to use one or two segments of this 36-byte UUID string. (Of course, you need to be sure that these segments are well-protected.) The contracted identifier can be protected much better if it is used as a local entity identifier within aggregate. To demonstrate this, let’s have a look at the following identifier:
APM-P-08-14-2016-046B6C7F
APMis a specific context to control the design processPis the project itself08-14-2016is the date when it was created046B6C7Fis the first segment of UUID.
When identifiers like these are found by developers, they can easily figure out where and when they originated.
#3 Identifier generation by permanent storage mechanism
To create this type of identifier, you need to request the database. Thanks to this method, you can always be sure that your identifier is protected and unique. And it will be rather short as well, and you will be able to use it as a part of concatenated identifier.
This strategy has a fundamental disadvantage, though — performance. If you request the database each time you need to receive a specific value, it takes a lot of time. If identifiers are generated by the app, processing happens much faster.
#4 Identifier attribution by other bounded contexts
Sometimes you need to integrate different bounded contexts to obtain an identifier. For example, you can do it using context maps as I demonstrated in the previous article.
To find a specific identifier in another bounded context, you can specify several attributes (email, account number, etc.) that allow identifying the unique identifier of external entity, which you can use as a local identifier. You can also copy a specific additional value from external to local entity.
However, when we usually deal with entities, we need to take not only a domain identifier but also a surrogate identifier into account. The first identifier is subject to specific rules within the domain, while the second one should be used specifically for ORM (as Hibernate). To create a surrogate key, we need to create such entity attributes as long and int. Meanwhile, the unique identifier is generated in the database, and it then can be used as a primary key. After that, this key’s visualization is implemented to the attribute with ORM instruments. A surrogate identifier like this is usually hidden as it isn’t included in the domain itself.
To note! To protect the identifier’s uniqueness within the object’s lifecycle, the identifier and the object itself have to be wired against any type of modification. As a rule, the protection is achieved by hiding identifier’s setters or by developing a specific check-up mechanism to scan the setters and locate any modifications and changes. The PFM system from the previous article demonstrates this principle well enough.
To begin, we should separate specific entities in a given domain. In our case, we have BankingAccount entity, which can be identified with the help of accountNumber. Though this number is unique only for a given bank and can be duplicated many times in other banks. (Of course, you can always rely on IBAN if you live in the EU.) In other words, you need to use not only accountNumber but also a specific UUID segment. This way, our identifier will consist of:
PFM-A-424214343245-046b6c7f
PFM— context nameA— account424214343245— accountNumber046b6c7f— segment of UUID
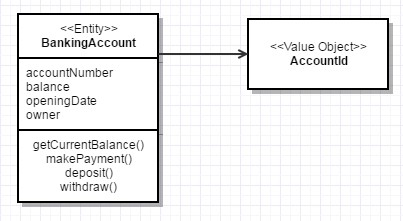
You can set any identifier as a value object as well. So, let’s examine this crucial DDD pattern in detail.
Value Object
If having unique features is not that important for your objects; if these objects are specified thanks to their unique attributes, you should view them as so-called value objects. To figure out if this or that notion/concept should be considered a value, you need to check if it has the following features:
- It measures, evaluates, and describes a domain object
- It can be considered to be a persistent notion/concept
- It models a conceptually non-breakable concept that bundles multiple attributes together
- It can be replaced if the evaluation or description method is altered
- It can be compared with other objects using value’s equality relation
- It transfers side-effect free functions to the bundled/bounded objects.
You should encounter objects like these much more often than it seems. They are easy to develop, test and support. This is exactly why you need to use value objects instead of entities wherever possible.
Rarely, value objects are created specifically to be modified later. To restrict access to specific fields, setters are set to be private, while the object’s constructor — public. The constructor receives all the objects that act as value’s attributes. Basically, value object generation needs to be a protected, atomic operation.
When it comes to value objects, it is important to implement the equality verification operation correctly. To make two value objects equal, all the types and values of the attributes need to be equal as well.
Also, it is important that all the methods of value objects need to be side-effect free functions. As they shouldn’t violate the persistence property, they can return objects but can’t modify their state. Let’s have a look at the example below:
public class Money implements Serializable {
private BigDecimal amount;
private String currency;
public Money (BigDecimal anAmount, String aCurrency) {
this.setAmount(anAmount);
this.setCurrency(aCurrency);
}
…
}
The setters are hidden/private, while value object generation is set as a protected, atomic operation. In this example, {50 000 USD} is a value. Separately, these attributes either describe other things or don’t mean anything at all. But 50 000 and USD have to do with this specific relationship. That said, these attributes create a conceptually integer value that describes a specific sum of money. This type of conceptual unity plays a huge role because there are types of values and values on their own that exist as directed by ubiquitous language within bounded context.
So far, we have looked through entity and value objects. Let’s move on.
Domain Service
When you use ubiquitous language, its nouns are always displayed as objects, while verbs have an influence on the behavior of these objects. However, often there are verbs or any other actions that can’t be attributed to any specific entity or value object. If there is a similar operation in the domain, it will be declared as a domain service, which is quite different from an application service that acts as a client. Services have the following features:
- A service-performed operation relates to the domain, which doesn’t belong to any of the existing entities.
- The operation is carried on with specific objects of the domain’s model.
- The operation doesn’t have a state.
You shouldn’t use services too often, though. If you rely on them frequently, it can result in anemic application domain model. The business logic should be divided between entities and values. Only if you can’t do it within ubiquitous language, you can use domain service. The important thing is that it needs to derive from ubiquitous language.
To demonstrate it, let’s have a look at a money transfer operation from one account to the other. Basically, you don’t know in which object you can store the transfer operation itself. Therefore, you can use a service. Like this:

Domain Entity
Looking into a given domain, you quickly realize that there are some facts that are specifically important to subject matter experts. For example, they can introduce these facts using such phrases as:
- When...
- If this is the case...
- Contact me if...
- In case of...
That is, if something is due to happen following other action, you need to design a specific domain entity.
In the process, you should pay special attention to the fact that domain entity is basically any action that took place in the past. Therefore, its name should reflect that the action was in the past but is now attributed through ubiquitous language within bounded context.
Similar to value objects, domain entities are designed against any modifications; their functions are side-effect free functions. Domain entity is designed as an object the interface of which specifies its function, while its properties — the cause.
Let’s look at the FundsDeposited example below:

occuredOn is a time tag for domain entity. Then, you need to specify important properties that store the information about what’s going on (the process). One of the most important properties is an identifier of entity and aggregate, in which accountId domain entity is generated. Also, subscribers may find specific parameters that transfer aggregate from one state to the other.
In this case, we design a domain entity, which is activated when anyone credits an account. Hence, you can text a message (when the money is on the account), email, or perform any other type of operation.
To publish and process domain entities, you can use observer pattern, or publisher subscriber. If the action is processed within a given bounded context, you can't use multiple infrastructure components and elements that shouldn’t exist in the borders of this or that domain. You can simply add observer pattern to the design.
That is, you can just create a DomainEventPublisher object that will store, register all the subscribers and publish domain entity. The publication for subscribers is managed in sync, within a specific cycle and a specific transaction. Basically, every subscriber can process his or her domain entity separately.
It is important to stress that domain entity is a concept that exists within domain, not as a separate bounded context. So, you can transfer domain entities asynchronously into external bounded contexts, which is done thanks to built-in message communication system.
There are many components to transfer messages that are related to middleware class (for example, RabbitMQ, NServiceBus). You can also transfer messages with REST where autonomous systems refer to the publication system, demanding non-processed notifications.
RESTful approach to the publication system of domain entity is opposed to the publication process, which is done with the help of a typical message communication structure. “Publisher” doesn’t support several types of registered “subscribers” because the interested parties don’t receive any messages whatsoever. Instead, this approach relies on REST clients to demand requests with URI.
It is crucial to understand that you need to achieve some type of coherence between the things that message infrastructure publishes and the actual state of domain. You need to guarantee that domain entity is truly transferred and that this domain entity depicts the true state of the model where it is published.
There are different methods to guarantee that this type of coherence is properly achieved. As a rule, you can rely on repository within bounded context. This repository is mainly used by the domain’s design patterns and utilizes external components that publish unpublished domain entities using the message transfer mechanism. However, this approach presupposes that clients need to deduplicate incoming messages to guarantee in case of message resend the clients can process it correctly.
In both cases, when subscribers use middleware to transfer messages, or when they rely on REST, you need to track all the processed message IDs and store all the info on changes and modifications in domain’s local state.
Module
Modules that are stored within the model are so-called manifested containers for a specific interrelated group of objects in the domain. Their goal is to weaken the connections between the classes within multiple modules. From a DDD perspective, modules are non-formal or generic modes. Their name selection is a function of ubiquitous language.
You need to design loosely bound modules because it simplifies the support and refactoring of design patterns and concepts. If bounding is necessary, you should focus more on acyclic dependencies between peer modules. (Peer modules are modules that are located on the same functional layer and have similar value in the project.) Modules shouldn’t be designed as a model’s static concepts because they need to be modified depending on the objects they organize.
There are certain rules of module name selection. Module names are used to depict the organization's hierarchical structure. The names’ hierarchy usually starts from the organization's name that is responsible for module development. Like this:
com.bankingsystems
The next module name segment identifies bounded context. The name of this segment should follow after the name of bounded context. Like this:
com.bankingsystems.pfm
Then, you have a modifier that identifies the module of a given domain:
com.bankingsystems.pfm.domain
You can place all the modules into the domain section:
com.bankingsystems.pfm.domain.account <<Entity>>BankingAccount <<ValueObject>>AccountId
Design patterns that are stored outside of this model are named according to architecture. Within the context of a well-known multi-layered architecture, the naming would be the following:
- com.bankingsystems.resources
- com.bankingsystems.resources.view (user interface layer (view storage))
- com.bankingsystems.application.account (application layer (submodule of application services))
Modules are used to aggregate bounded objects within the domain and are separated from unbound or loosely bound objects. Bounded contexts often do wrap several modules because they bundle/bound all the concepts into a single model if there are no clear borders between multiple contexts.
Aggregate
Aggregate is the most complex tactical design pattern in the domain-driven design.
Aggregate is a cluster of entities and values. Basically, these objects are viewed together as a unified whole from a data modification perspective. Every aggregate has a specific root and border; and, within this specific border all the possible invariants should be satisfied.
All requests to aggregate should be performed through its root. Root is a specific type of entity that has its own global, unique identifier. All inner objects of aggregate only have a so-called local identity but can refer to each other without limitations. External objects can store only a link to a specific root, not to inner objects.
Invariant is a business rule that always preserves its consistency. This consistency is often called an atomic transactional coherence. However, there is a so-called overall coherence as well. In the case of invariants, transactional coherence is used. A transactional coherence border can also be named aggregate. This border stores all the invariant rules regardless of the performed operations. If you want to specify aggregates in bounded context, you need to analyze the actual invariants of the model in order to figure out which objects to bundle into aggregate.
When you need to design aggregates, pay attention that small-cluster aggregates are better than large-cluster aggregates in terms of performance and scalability. To upload a large aggregate, you need to have more memory. Meanwhile, smaller aggregates not only work much faster but also improve transaction performance. It is more desirable to use value objects, not entities within aggregate. Value objects are much easier to support and test (as I mentioned above).
Every aggregate can store links as roots of other aggregates. However, it doesn’t place this aggregate into the coherence borders of the first aggregate. A link doesn’t establish a comprehensive aggregate.
Within the context of transaction in bounded context, only a single aggregate should be modified. It is preferable to create links using global identifiers of aggregate root. You shouldn't store direct links as objects or locators. By this, you decrease object memory, allowing them to upload and scale faster.
If a user’s request has to do with several aggregates, rely on the overall coherence principle. You can achieve overall coherence by publishing domain events. Basically, when aggregate is modified, it publishes an event that causes other aggregates to complete the action and maintain the system’s coherence.
To demonstrate that principle, look at the credit report below:

Every credit report needs to include a credit user’s ID data. Use customerId to save and store external linkage by identifier. Customer is an independent aggregate that preserves all the info about the credit user (name, address, contacts). Let’s say that the credit rating estimation rule is used as invariant and is modified based on specific data stored in the credit history. It is not important how this credit rating is calculated or estimated; what matters is how transactional coherence within aggregate is achieved. For example, when the credit history is somehow modified, the credit score should change too. This should be an atomic operation. If you use a database, it makes sense to create an independent transaction. As soon as any changes in the object's data within aggregate are made, invariants should be activated and applied.
Inquiry is a specific credit score request from third-party organizations. Aggregate root is an entity and has a global identity. If you should link to this aggregate, you will be able to use only an identifier root. In case you delete a credit report’s aggregate, all values are deleted.
Factory
Factory design pattern is rather popular and is more widely used than other design patterns.
Some aggregates and entities can be rather complex, and complex objects can create themselves using constructor. The situation can be even worse: when you pass a complex object creation process to the client-side. Basically, it means that the client should know a project’s inner structure and dependencies. This disturbs encapsulation and bounds the clients to a specific realization, and you will have to modify the client part when introducing any changes to the object as well.
To make a long story short, it is a much better choice to create complex aggregates or other objects separately. This is when you should rely on factories. Factories are program elements that are responsible for the creation of other objects.
As a rule, factories are designed as factory method in aggregate root. Factory methods are efficient because they can express ubiquitous language (which the constructor can’t do).
When you create factory method in aggregate root, you need to follow all the rules of invariant aggregate and create it as a unified whole. This method must be one and undivided. All factory method creation data (value objects) should be passed within a single communications' operation. All the details are hidden.
Value objects and entities are created differently. As values are unmodifiable, all the attributes should be passed right after the creation. Meanwhile, you can add only specific attributes to entities (the ones that are important for this specific aggregate and its invariants).
Repository
Repository is a memory segment that is used to safely store all the necessary elements. This is what a domain-specific repository actually is. Repositories are used to store aggregates. When aggregate is placed into a specific repository and then get extracted from it, you get a unified object. If aggregate is modified, all the modifications will be saved. If aggregate is deleted, you will no longer be able to extract it.
Every aggregate that needs to be stored for a given time period should have its own repository.
Often, repositories are designed to guarantee that all previously generated aggregates can be easily found in it. Therefore, there are two types of repositories:
- Repositories that imitate collections;
- Repositories that store data permanently.
Repositories that imitate collections are good at imitating collections, modeling at least a part of its interface. Its interface doesn’t show the permanent storage mechanism in any way possible and is used as a standard DDD pattern.
You can view this repository as HashSet<ObjectId, Object>. In this collection, you can’t insert similar elements twice. When the object is received and modified, all the changes are saved and applied right away.
Though the clients shouldn’t deal with the permanent storage mechanism, you need to constantly pay attention to how this mechanism operates and how it stores all the changes in objects. To do this, you can:
- Rely on implicity copy-on-read method (The permanent storage mechanism copies stored objects every time the database is requested and then compares the closed copy with the client one whenever a transaction is underway)
- Use implicity copy-on-save method (The mechanism manages uploaded objects using proxy objects).
Such mechanism as Hibernate allows you to create any type of repository, which is specifically designed to imitate the collection.
Under the high-performance conditions, it is costly to store all the objects in the memory. It overloads the memory and its system too much. But in case of repository that utilizes the permanent storage mechanism, you shouldn’t focus too much on how and when the objects are modified; you should just save all the changes with the save() method. Like this:

To implement and use repository, rely on multiple methods and objects of the permanent storage mechanism. It is important that repository is created on the infrastructure level but the interface is declared in the domain.
In this case, you need to use the first repository type (the one that I used to imitate collections). It can be used with save() and put(). Only the collection methods.
Access to the database and other mechanisms get encapsulated in repository. The client-side will be rather simple and won’t depend on methods used to create the repository itself.
Conclusion
Here we have it. We have looked through all DDD patterns. All of them can be used to develop specific bounded contexts. To begin with, you can start by specifying entities and value objects. Then, you can break them into separate aggregates to adjust and coordinate all the data and maintain business rules within aggregate borders. After that, you need to follow through with the creation of factories and aggregate repositories. To adjust all the data within the system, you can rely on events. They can be created in the unified system, not simply in bounded context.
I could also talk a bit about the application, its layers, tiers, and architecture. However, I decided not to do it to make a shorter version of the article. I hope, it will help you understand DDD more!
Please, let me know what you think about DDD and its tactical design patterns in the comment section below!