Introduction
Distributed caching systems are becoming more widespread and used, many developers use these systems in order to make better use of server resources, in particular memory.
Integrating a distributed cache system in an application is generally very simple: just add the client library to your application and use it every time you want to retrieve a data from the cache.
The typical use is to try to read the data from the cache and if the data is not present, read from a data source and then put it in cache.
This implies that the application must maintain access to both the cache and the data-source.
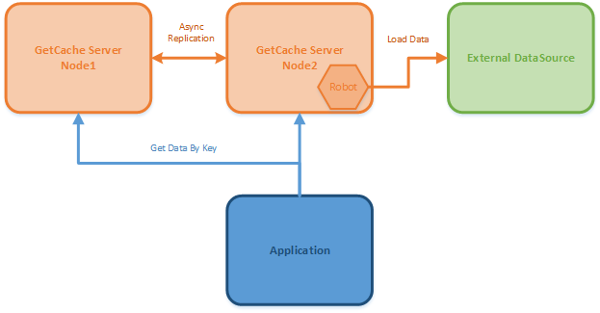
But what would happen if an application does not want to have access to data-source? Or is it possible that the caching system is able to load in autonomy the data and put them in the cache?
GetCache addresses this situation.
GetCache provides APIs that allow users to realize the components that autonomously and periodically retrieve data and placing them in the cache.
These are the GetCache Robot API and the user components developed with these API are named Robots.
Robots classes can access any data-source, like database, web services, REST API or external resources like files. Robots can aggregate data and put in the storage of GetCache. Clients should only read the data that is automatically and periodically refreshed by Robots.
Background
GetCache is a key/value store developed with .NET 4.5 and is very simple to use and manage. GetCache operates a distributed in-memory cache that supports data sharding on multiple nodes and data replication. Nodes can be added and removed to the cluster without causing service interruptions.
GetCache stores any type of data, objects can be serialized using JSON or XML, row object like images or videos can be stored as byte arrays. GetCache supports also automatic data expiration.
Creating a Robot
In this tip, we create a Robot that takes care of periodically downloading content from RSS sources and stores it in the cache.
As we shall see, the robot can aggregate multiple RSS sources together and store them in storage.
The first step to develop your own robots is to download the GetCache.Robot API library.
The library is available on Nuget, alternatively the library can be downloaded from GetCache site www.getcache.net.
Then we can proceed to define our own Robot class.
[Robot("RssLoader")]
public class RssLoader
{
public RssLoader() { }
[LoadData("technology", Persistence=StoringMethod.SINGLE, RefreshTime=60)]
public Object LoadTecnologyRssContent()
{
List<rsscontent> rssList = GetRssResource
("http://rss.nytimes.com/services/xml/rss/nyt/Technology.xml");
return SerializationHelper.SerializeDataJson(rssList);
}
[LoadData("jobMarket", Persistence = StoringMethod.REPLICATED, RefreshTime = 120)]
public Object LoadJobRssContent()
{
List<rsscontent> rssList = GetRssResource
("http://www.nytimes.com/services/xml/rss/nyt/JobMarket.xml");
rssList.AddRange(GetRssResource
("http://feeds.washingtonpost.com/rss/jobs/career-advice"));
return SerializationHelper.SerializeDataJson(rssList);
}
private List<rsscontent> GetRssResource(String url)
{
var reader = XmlReader.Create(url);
var feed = SyndicationFeed.Load(reader);
List<rsscontent> list = new List<rsscontent>();
foreach (SyndicationItem si in feed.Items)
{
RssContent rss = new RssContent()
{
Id = si.Id,
LastUpdatedTime = si.LastUpdatedTime,
PublishDate = si.PublishDate,
Summary = si.Summary.Text,
Title = si.Title.Text,
};
list.Add(rss);
}
return list;
}
}
The attribute Robot specifies that the class RssLoader is a robot component and it's named "RssLoader".
The attribute LoadData must be applied to all methods that are responsible for loading the data.
- The first parameter indicates the key that is used to store data in the cache.
- The second parameter indicates which storage method is to be used by the server
GetCache:
StoringMethod.SINGLE indicates that the server will save only one copy of the data in the cluster, in this case, the sharding algorithm is used to determine which node in the cluster maintains data StoringMethod.REPLICATED indicates that the server will save the data in all nodes of the cluster, in this case, the server uses an asynchronous replication mechanism that copies the data to all nodes
- The third parameter indicates the period of time with which the data are reloaded into the cache. The
RefreshTime is expressed in seconds.
The attribute can only be applied to methods that do not have parameters in the signature and must return an object.
The object returned by the method can be a string or an array of bytes. In this example, we use the helper class SerializationHelper provided by the Robot API to serialize the object to JSON format.
Deploying the Robot
After compiling, we can produce a module to be installed on the server. A module is a set of DLL that contains the compiled classes necessary to the robots. All the DLL must be included in a directory that has the name of the module. A module can contain more than one robot and a robot can have more than one load data method.
There are many possible ways to install the robot on a server GetCache:
- Create the directory "
MyRobot" under the "deploy" directory of the server, copy the robot DLL Robot.RssLoader.dll under "MyRobot" and restart the server. - Create the directory "
MyRobot" under the "deploy" directory of the server, copy the robot DLL and use the server console command "deploy" to install the robot without restarting the server. - Create the directory "
MyRobot" locally, copy the robot DLL locally and use the GetCache Remote Console application to install the robot (i.e. use the "upload-module" command).
Test the Robot
When the robot is installed on the server, it begins to retrieve the data and populate the cache. Periodically, the data is refreshed.
Then you can query the cache to get the list of loaded RSS feed. We can use the server console to read feeds:
>get technology
technology => [{"Id":"http:\/\/dealbook.nytimes.com\/2013\/09\/17\
/china-internet-giant-buys-stake-in-search-engine\/",...
>get jobMarket
jobMarket => [{"Id":"http:\/\/www.nytimes.com\/2010\/07\/18\
/business\/18corner.html","LastUpdatedTime":...
Conclusions
Of course, the robots cannot be used to load any information in the cache, and you cannot remove access to databases by applications but there are many ways to use robots in loading data that do not change or that change little over time, such as the list of the states, the list of provinces, list of postal codes, but also data that changes little during the day as the list of customers, the list of users, or statistical data, etc.
All these types of data can be preloaded in the GetCache storage to be always available to client applications.
History
- First revision
GetCache_Robots_1_0
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





