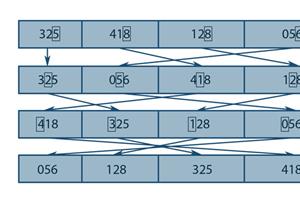
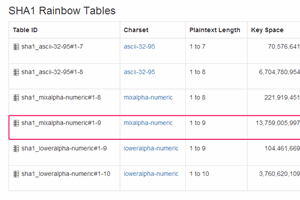
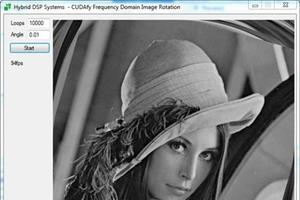
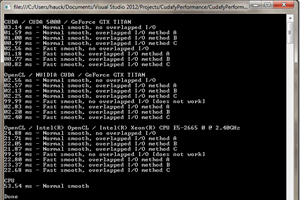
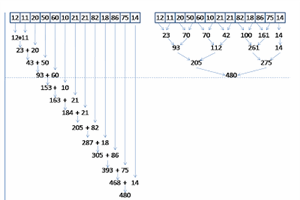
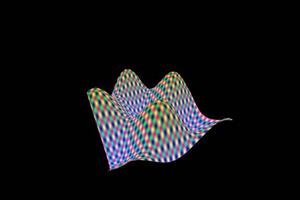
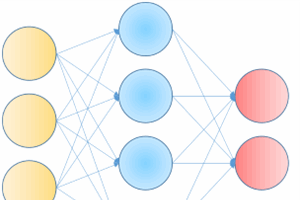
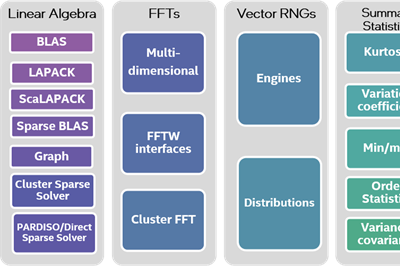
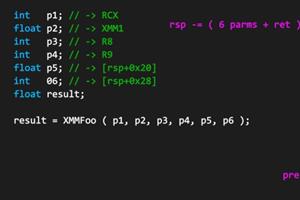
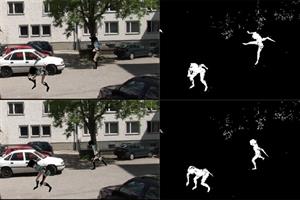
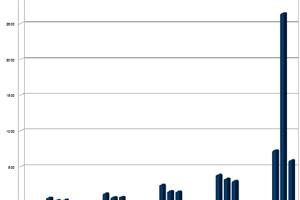
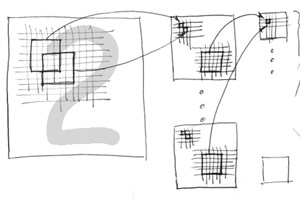
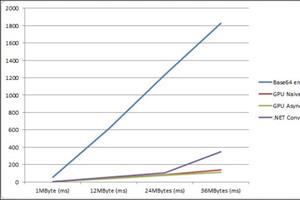
22 May 2013 by John Michael Hauck
It has never been easier for C# desktop developers to write code that takes advantage of the amazing computing performance of modern graphics cards. In this post I will share some techniques for solving a simple (but still interesting) image analysis problem. Source Code https://www.assembla.com/co