Part II: Merriam-Webster's Dictionary: Converting HTML to RTF
Introduction
Merriam-Webster's dictionary is free to use on the internet. Anyone can go to their website. Type in a word. Get a definition. And I'm fairly certain that writing a few lines of code to retrieve every file in their database and copy them onto your harddrive might skirt the boundaries of probity but as long as you don't sell it for profit after inserting abusive definitions of the word Trump ... you're ok.
The reasons why someone might want to do this are simple, and there are many but really .. just because. Why not, right? Call it a challenge, binary calisthenics or just fun. It's better than Sudoku.
What's cool about it is that once you've made one web-scraper, making the next one will be a lot easier. And you may eventually find a good reason to use one even if you can't think of a reason right now. Having a copy of Merriam-Webster's dictionary on my computer is way-cool because now it's incorporated into my word-processor. Yes, I know, MS-Word does that. I could go out and buy a factory-made basket that will last longer, and look way better than anything I could make by hand, but what the hell, there's a marsh a short walk from here and it costs me nothing but a few hours of sun-filled leisure to make my own out of reeds I picked myself.
In any case, here's how I scraped Merriam-Webster's dictionary...
Background
The Wiki page on Merriam-Webster will tell you that George & Charles Merriam founded their company in 1828 and then bought out Noah Webster's estate in 1843 to incorporate their now world-famous reference-book publishing empire. They've been editing and publishing dictionaries for nearly 200 years and I must have owned a half dozen copies of their products since high-school, including the one on my shelf beside me.
Using the Code
The source code included with this article will not download the MW database on its own and I'll tell you why ...
First, I'll explain a bit about what it does. I give it the first URL in Merriam-Webster's collection of words it has listed on its web-site, which is 'cause. It inserts this Url into a queue (List<string>) of Urls it needs to download. Then it takes the first Url off that list and adds it to a different list of Urls it has already downloaded (empty at the moment) and then downloads the file from Merriam-Webster's website. It then parses the HTML and finds the links to Dictionary Entries near 'cause. Once it finds these, it checks them against the list of Urls it has already downloaded and enters those it hasn't yet downloaded into the list first mentioned above and then, before it moves on to the next Url, it saves this file onto my harddrive.
The idea is very simple. Get a file, find the links it hasn't tried already and save the HTML file on the HD.
But... there's a problem. There usually is. There are words that appear as different Urls but are just the same file. So when you meet with the file for the letter A, its 'entries near A' links all point to itself, arresting this easy-peasy scraping algorithm. So, I had to include the alphabetically ordered content of my Thesaurus as words/file-names for the scraper to try. Since all the files in the Merriam-Webster's dictionary are spelled the same as the word they define, you can simply type in the address of whatever word you want to download, e.g., www.merriam-webster.com/dictionary/whatever. So, whenever my algorithm's list-of-Urls-left-to-try is empty, it goes to the Thesaurus, pulls off the first word on the list and asks itself if it has already tried that one before downloading it and seeing if it can reboot itself back to life retrieving new Urls and adding them to its growing list.
string strURL_source = ParseHTML_MerriamWester_GetNextUntriedWordFrom_URLsList();
if (strURL_source.Length == 0)
{
strURL_source = ParseHTML_MerriamWester_GetNextUntriedWordFrom_Thesaurus();
}
You can see in the code above the lines where it decides to pull an Url off the list of Urls its collected or try the Thesaurus route. You'll need to get your own Thesaurus to do this yourself. But I plan to publish the results of this project through two more articles that demonstrate:
- how these files were re-written from 255,000 HTML files (that look like crap off-line) into Rich Text File documents that look even better than their source files (more trouble than you might imagine)
- how to incorporate this off-line dictionary into a word-processor that can help you rite moore eleghandlee (it needed a search engine).
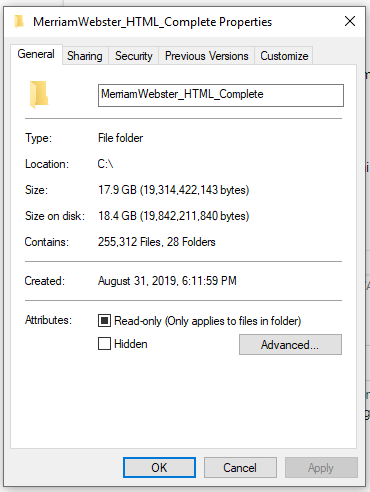
The screen-capture below shows you the directory that contains the loot I nabbed from Merriam-Webster's website.
(insert picture of me with cheesy grin here).
Points of Interest
The following lines of code put my limited knowledge of HTML to use. Essentially, it detects the presence of the HTML-marker the web-designers at Merriam-Webster used to tell your browser that it's going to list the links to words that are near the one you're currently looking at. Then, it pulls all the links to those words out of the HTML document and adds those it hasn't seen before to the list of new Urls it will use to download the next file.
{
string strURLSNearby_start = "<div id=\"near-entries-anchor\" class=";
int intURLSNearby_Start = strHTML.IndexOf(strURLSNearby_start);
if (intURLSNearby_Start > 0)
strSource_URLsNearby = GetNext(strHTML, "<div ", "</div>", intURLSNearby_Start);
}
{
string strMWNextURLList_Start = "<h2>Dictionary Entries near <em>";
string strMWNextURL_Start = "<a class=\"b-link";
int intCut_URL_List_Start = strSource_URLsNearby.IndexOf(strMWNextURLList_Start);
if (intCut_URL_List_Start >= 0)
{
int intCut_URL_Next_Start
= strSource_URLsNearby.IndexOf(strMWNextURL_Start, intCut_URL_List_Start);
string[] strSeparator = { strMWNextURL_Start };
string[] strUrlsNearby
= strSource_URLsNearby.Split(strSeparator,
StringSplitOptions.RemoveEmptyEntries);
IEnumerable<string> URLs = lstURLs.Distinct();
lstURLs = (List<string>)URLs.ToList<string>();
for (int intCounter = 0; intCounter < strUrlsNearby.Length; intCounter++)
{
string strUrlNearby = strSeparator[0] + strUrlsNearby[intCounter];
string strURL_New = RemoveMarkUpLanguage(GetNext(strUrlNearby, "<a ", "</a>"));
if (strURL_New.Length > 0 && !lstURLs.Contains(strURL_New))
if (strURL_New.IndexOfAny(chrInvalidCharacter) < 0)
lstURLs.Add(strURL_New);
}
}
}
where their website looks like this:

The HTML looks like this:
So, what you have to do is grab the content of <div id you see at the top there, then parse through that text picking out the relevant information in each <a class= link that gives you the Urls you need to keep going along. To make this easy, it uses the functions GetNext() and RemoveMarkUpLanguage(). To sooth my eyes while I worked with these Urls, I changed the unicode to readable text but then had to re-unicode them before using the Urls to download the files.
I included the HTML-ator tool that I made to help me pierce through the deep mysteries of HTML scrape-dom. Mind you, I never wrote any instruction manual for it so you'll have to play with it to see what it does. Essentially, it's good to search for markers, jump to a specific character index and grab the contents of text enclosed between HTML markers, like <p> </p>.
Here's a screen shot of it below. This article's HTML was cut'n'pasted into the left textbox. Then, with the cursor to the left of the <p> paragraph marker you're interested in, click the p in the box below. The keep radio-button tells it to send the paragraph marker with its content to the right textbox. This tool makes use of an easy-to-use Sweep-and-Prune algorithm to draw all those buttons in the classMultiButtonPic that I made just for the occasion. Each word in the text beneath the red circle is a clickable button that reacts when the cursor passes over it. The pic is drawn once then gets refreshed with necessary highlights for mouse-cursor events.
I'm sure there's more to tell, but it's all fairly simple. The hard part was getting these files to look good in Rich Text Boxes. Those things are particular and take a bit of care to get them to do what you want. You may even be the proud owner of an "I hate rich textbox' t-shirt. But don't worry, I've got just the thing to help you out. Look in again soon to hear about that.
Part II: Merriam-Webster's Dictionary : Converting HTML to RTF
Christ Kennedy grew up in the suburbs of Montreal and is a bilingual Quebecois with a bachelor’s degree in computer engineering from McGill University. He is unemployable and currently living in Moncton, N.B. writing his next novel.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 But you should clearly mention that anyone using your code does need it also!
But you should clearly mention that anyone using your code does need it also!