Introduction
Choosing an ORM can be a major decision which locks your application in for years to come; but you may find – a long way down the path - that the implementation is not as scalable as you hoped when your production system begins to ramp up. An ORM should be designed so that it can be easily upgraded to a multi-tier environment, and this is especially necessary now that it is so easy to spin up a few extra VMs. And although the need to avoid boilerplate is always cited as the top reason for using an ORM, you may still find large quantities of it lying around. And that is hard to upgrade if you need to later on.
But it doesn’t need to be like this: the core code for this project is basically ten source files and it is quite feasible for you to take ownership of the code and customise it to the specific needs of your own projects.
Background
What is an Entity, anyway ?
An entity is a class without behaviours, except to save and read itself; its passivity has some similarities to a Data Transfer Object (DTO). Its purpose is to carry data around between the different application layers and/or tiers; but it will always finally end up in a database. Entity behaviours are assumed to be implemented in the Service Layer of a multi-tier application.
What are tiers, and why are they important ?
Tiers are layers which can run on multiple machines, in serial or parallel. Note that not all layers can be run on separate tiers, indeed multi-tier boundaries are usually supported by their own specialised layers at client and server.
Multi-tier implementations on multiple servers are of course potentially much more scalable – but there can be serious potential performance issues; principally, it is negligible effort to pass very complex parameters, such as object graphs, within a tier (it’s just passing a reference) while passing the parameters between tiers requires serialisation and potentially large data transfers. There are also large latencies for passing data between tiers and it is helpful to have a design that can batch up multiple items of data in one “hit”, for efficiency reasons.
Some Key Design Decisions
An ORM can be created from custom XML-based files or can be actual classes with ORM behaviour flagged by custom attributes. Since you will be working daily with entity classes in the rest of your code, let’s go with the latter – it’s easier than managing another conceptual layer. At a later point, bolt-on tools could be generated to generate entity files automatically from the database, or to support code-first entity implementations, but that will not be provided here.
Entities are of course prime candidates for a template implementation, but that can lead to complex syntax – the internals of this ORM uses the dynamic keyword a lot to simplify the code but the external view is of straightforward classes.
I would like to be able to inject different flavours of layer, such as WCF or RabbitMQ remote interfacing or different flavours of serialisation; the DAL layer, especially, requires some “friend” access to entity properties. So for serialisation to work with different serialisation and DAL modules, we can’t rely on custom attributes – so we are forced to use public for serialisable properties and protected internal for properties requiring “friend” access (or implement properties as method calls, such as “GetValue()”). You cannot rely on custom attributes to control serialisation if you are injecting selectable serialisation implementations.
Static constructors are guaranteed to be called once and only once, using a templated Entity base class ensures that the static constructor for each entity is specific to that entity. The type of DAL (local, WCF or RabbitMQ) is injectable and the DALBase base class ensures that common features such as configuration are shared.
Detection and management of “dirty” entities is an important factor for good performance, so that you don’t unnecessarily hit the database. Two options exist, either use custom property setters which also set the dirty flag (which is horrible boilerplate) or automatically use hashing of the complete object to detect dirty entities. The latter case can be justified not only on aesthetic grounds but because users often edit an entity and then change their minds and edit it back again – detecting this scenario even infrequently will prevent unnecessary updates and “pay its way” in performance terms.
A key factor in this implementation is to recognise that cross-process communication can be very expensive – so this ORM enables easy bundling of multiple entity operations – for example, an application may use only specific parts of several complex object graphs and may also require several lists of entities. Think of a web form displaying an employee description: you need to pull and display the person details, perhaps with details of their company and department and line manager, together with dropdowns for (say) job titles, countries, training courses, etc. Getting all this information in one hit (but without dragging in the whole object graph) across multi-tier boundaries is an enormous performance gain and easy to conceptualise.
An implementation of entities is going to require some reflection, so take this performance hit one-time by implementing a static constructor which does all the hard work so that subsequent usage does not require these expensive performance operations. Efficient Getters and Setters mean that the external developer is protected from having to grapple with complex reflection code, if they don’t have the experience.
Make all the interfaces injectable (serialiser, transport mechanism, cache) so that you can easily plug in your own implementations.
The Data Access Layer (DAL) Functionality
Entities are supported by a Data Access Layer, DAL. As well as managing CRUD operations, the DAL here also does the following:
- Manages injectable serialisation
- Manages injectable caching
- Manages injectable DAL, such as WCF or RabbitMQ
- Detects stale data from the database (optimistically) and prevents updates that would overwrite other saved data
- Maintains a “dirty” flag, automatically updating only dirty data
- Supports lazy-loading across tiers
- Supports pre-loading of multiple entities (including pre-loading of objects which are normally lazy-loaded)
- Supports creation and update of multiple entities in an object graph in a single transaction, or multiple transactions
- Supports batching of custom SQL with entity operations
- Delivers “partial-entities”, for security reasons or to support data sharing from a cache
- Supports validation against actual local database, even across tiers, which is safe even for production environments
- Supports read-only fields, such as computed or timestamp fields
- Supports identity fields
- Supports "fire and forget" (“offline” or "oneway") entity operations
- Does not require a primary key of a particular type such as Guid, and may not require a primary key to be defined at all
Other ORMs support list management, but I don’t think that lists are best managed as arrays of objects – that just adds overhead to the task of pulling data from the SQL Server metal and onto a grid. List management is a specialised business, requiring the ability to manage huge quantities of data incrementally while flexibly sorting and filtering, all without overloading caches or transfer buffers. These are very different requirements to ORMs. Check out my article on CodeProject A Lightweight AjaxGrid User Control for MVC.
Non-functional Options
A non-functional feature is one that gives benefits to the development process, rather than specific functionality. These are:
- Client and server code are held in the same DLL, making it easier to synchronise updates between machines
- Client and server can also share Entity definitions in a single shared DLL, ensuring that they also stay in sync
- A single change to
entity.config switches on local or remote DAL tiers, hugely simplifying debugging and system development - Caching can be switched off on a running system and an alternate cache can be set up, this simplifies progressive upgrading to updated entity versions while the old system continues to run
- If you build all the DLLs to one target directory, this massively simplifies the task of managing multiple servers and keeping them in sync (a simple copy of all files in this directory does not impact on each individual server’s configuration)
Requirements and Limitations
- At the moment, all tables must join through a single key field (although not necessarily the primary key)
- The entities are created at compile time. Although you could create or configure entities dynamically, I think this would make them hard to use by other code.
Using the Code
Setting Up
- Download the code
- In the data section you will find a script for a test database, apply to a blank database created from SQL Server Management Studio
- Compile (I used Visual Studio 2013 Express, .NET 4.5.1)
- Edit the entity.config file in the Data directory (probably just the connection string) and copy to c:\config\entity.config – or whatever your compile constant is set to
- Run the unit tests in the
EntityTest project - Sample servers are provided as console applications (although you would normally run these as Windows Services)
- Configure
entity.config to server=”wcf” or server=”rabbit” (a one-liner) and then rerun the unit tests with the appropriate server running - Code your own entities and include the DLL in your project
- Check out the unit tests for examples of how to use the ORM
- Check out the
TestSqlTypes entity for mapping from SQL to C# types
A walkthrough of the projects
- ORM is the ORM implementation
TestEntities are the sample entities ORMTest is the unit testsRabbitMQEntityServer is a simple server for remote tiersWCFEntityServer is a simple server for remote tiers
A walkthrough of key source files
- Entity.cs principally manages the
static constructor logic to extract field and join information through reflection. With this data, it generates basic SQL statements, which will be used in the data layer. It also supports “dirty” management and provides simple wrappers for CRUD operations - EntityAttributes.cs defines the attributes for the
Entity, Field and Join classes, to which are added extra information extracted by reflection - OrmCommands.cs defines the instantiation of commands (such as CRUD), enabling them to be serialised to remote tiers. For convenience of local implementations, each command has a virtual function
ToSql() – which builds the SQL – and a virtual function FromSql() – which reads the results from the SQL commands. Both virtual functions walk the object graph in the same way so that SQL commands are matched to creation or editing of objects from the SQL responses - DalBase.cs manages reading the configuration file and loading the specified serialiser and DAL
- DalLocal.cs is an implementation for local ORMs
- DalWCF.cs provides a client and server implementation for a remote ORM, using WCF
- DalRabbit.cs provides a client and server implementation for a remote ORM, using RabbitMQ
- DataLayer.cs generates SQL to perform CRUD operations, plus cascaded reads and database validation
- Serializer.cs has implementations of JSON and binary serialisers
- SubEntity.cs supports entities which only display a subset of a parent entity
- The Data folder contains a script to build the database and a sample entity.config file (copy to c:\config folder, or similar)
Some Practical Aspects
Multi-process, multi-tier systems are hard to configure, hard to deploy and hard to debug – so I have created an environment which is simple to manage and use from the very start. The standard configurable data is maintained in a separate configuration file which is outside the binary directory, so installation can be a simple copy of executables and other config files, and not overwriting each machine’s specific configuration.
Defining the Entities
The Sample Database
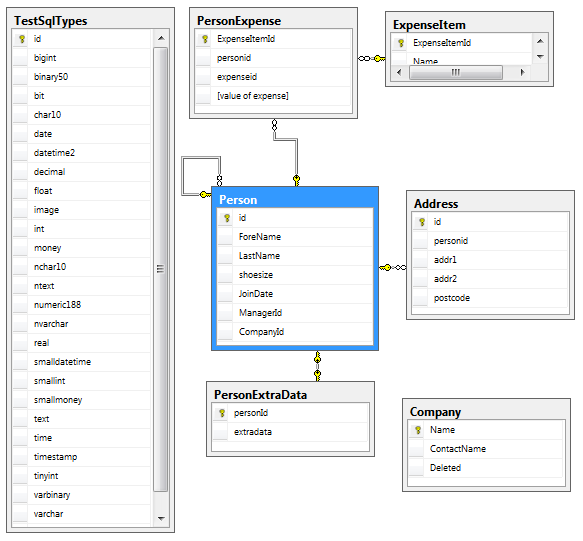
[Serializable]
[Entity("Person")]
public class Person : Entity<person>
{
public Person()
{
address2 = new LazyEntity<list<address>>
(this,"Addresses2");
}
[SqlField("id", IsPK:true, IsIdentity:true)]
public int Id { get; set; }
[SqlField("forename")]
public string ForeName { get; set; }
[SqlField("lastname","varchar(50)")]
public string LastName { get; set; }
[SqlField("shoesize")]
public int ShoeSize { get; set; }
[SqlJoin(TableJoinType.myKey,"PersonExtraData",
"id","PersonExtraData","personid")]
public PersonExtraData Extra { get; set; }
[SqlJoin(TableJoinType.myKey,"Addresses", "id",
"Address", "personid" )]
public List<address> address { get; set; }
[SqlJoin(TableJoinType.fKey,"Person", "ManagerId",
"Person", "Id")]
public Person Manager { get; set; }
[SqlJoin(TableJoinType.myKey,"Expense", "id",
"PersonExpense", "personid" )]
public List<PersonExpenseFromPerson>
PersonExpenses { get; set; }
[SqlJoin(TableJoinType.myKey,"Addresses2",
"id", "Address", "personid")]
public LazyEntity<list<address>> address2
{ get; set; }
}
Each Entity must:
- Have a
[Serializable] attribute - Have an
[Entity] attribute, with at least a parameter of the name of the SQL table - The class must derive from
Entity<T> - Field properties must have the
[SqlField] attribute, with at least a parameter of the SQL field name Join properties must have the [SqlJoin] attribute, with parameters specifying the type of join and the matching key fields and tablesLazyEntity fields require a constructor in the class constructor (at least, until C# 6.0)
Using the Entities
Firstly, conventional CRUD operation interfaces...
person = new Person();
person.ShoeSize = 7;
person.Create();
person.ShoeSize = 9;
person.Update();
var p = person.Read();
var p2 = person.ReadCascade();
var list = p.List();
p.Delete();
Each of the CRUD calls above results in a round-trip to the entity server and to the database server, but instead you can also batch up multiple commands as below:
var results = person.SendCommand(new List<EntityOperation>()
{
new EntityRead(person, new List<OrmJoin< ()
{ new OrmJoin ("Addresses"), new OrmJoin
("Manager") }),
new EntityList(jobTypes),
new EntityList(companyTypes,
new List<KeyValuePair<string,
dynamic>> ()
{ new KeyValuePair<string, dynamic> ("id", 55),
new KeyValuePair<string, dynamic> ("country","uk") }}
});
person = results[0];
var jobtypes = results[1];
var companyTypes = results [2];
.. do some work ...
results = person.SendCommand
(new ListList<EntityOperation>()
{
new EntityUpdate(person),
new EntityUpdate(company),
new EntityUpdate(address)
});
The point is here that it is the code using the entity, rather than the ORM, which decides which objects to load and which joins to expand. This can lead to big improvements in efficiency, since the object graph required is best known to that calling code rather than the ORM. However, the code can also choose to call ReadCascade, in which case the complete object graph is returned.
With most operations, you can specifically define custom selectors, but if none are defined and a primary key field is defined for the entity, then it is used by default.
When creating or updating, the entire working object graph is available for inspection by the ORM code and so it can choose how to persist the dirty parts of the object graph. When deleting, the ORM automatically performs a cascading delete of joined entities that would prevent the delete taking place.
Points of Interest
How the SQL is built up
Here is some typical SQL to update a column:
UPDATE person SET lastname=’Mandela’ WHERE personId=454; return @@ROWCOUNT;
Now prevent SQL injection by using SQL parameters:
UPDATE person SET lastname=@lastname WHERE personId=@id; return @@ROWCOUNT;
Support best practices for naming:
UPDATE dbo.[person] SET [lastname]=@lastname WHERE [personId]=@id; return @@ROWCOUNT;
If supported by the database schema, protect against stale update by checking a timestamp field:
UPDATE dbo.[person] SET [lastname]=@lastname WHERE [personId]=@id AND [timestamp] = @timestamp;
if @@ROWCOUNT = 1 select @timestamp FROM dbo.[person] where [personId] = @id;
Now support multiple SQL statements, which requires prefixing each parameter with a “command number” so that the same parameter name can be used multiple times:
UPDATE dbo.[person] SET [lastname]=@0lastname WHERE [personId]=@0id;
UPDATE dbo.[person] SET [lastname]=@1lastname WHERE [personId]=@1id;
For creation of a one-to-many object graph with IDENTITY fields, we need to both keep the identity value for use by other entities in the object graph and also to return each identity to the caller. SQL variables are used for this:
INSERT INTO dbo.[person] ([lastname]) VALUES (@lastname0);
DECLARE @Identity0 = Cast(@@Identity as int);
SELECT @Identity0 AS Identity;
INSERT INTO dbo.[address] [(street],[town],[personid]) VALUES (@street1,@town1, @Identity0);
DECLARE @Identity1 = Cast(@@Identity as int);
SELECT @Identity1 AS Identity;
INSERT INTO dbo.[address] [(street],[town],[personid]) VALUES (@street2,@town2, @Identity0);
DECLARE @Identity2 = Cast(@@Identity as int);
SELECT @Identity2 AS Identity;
For DELETE, all one-to-one, one-to-many and many-to-many joins must also be deleted first and so deletes must also be done in the right order. You could also perform orphan deletes for many-to-one, but there are probably better ways of doing that as part of a housekeeping process and I do not attempt this in my implementation. Note how temp tables are used instead of SQL variables, so that multiple cascaded DELETEs can be performed:
SELECT [id] INTO #tmpJ1 FROM dbo.[Person] WHERE id=@0id;
DELETE FROM PersonExtraData WHERE personid IN (SELECT id FROM #tmpJ1);
DELETE FROM Address WHERE personid IN (SELECT id FROM #tmpJ1);
DELETE FROM PersonExpense WHERE personid IN (SELECT id FROM #tmpJ1);
DELETE FROM Address WHERE personid IN (SELECT id FROM #tmpJ1);
DELETE FROM Person WHERE id IN (SELECT id FROM #tmpJ1);
SELECT @@ROWCOUNT;
DROP TABLE #tmpJ1;
Each SQL command is itself built up from basic text blocks to perform create, read, update, delete for all fields and joins – these are created one-time for efficiency in each entity static constructor using reflection.
Building the Joins
Joins can be defined as a combination of how many items will be returned (discovered by reflection as to whether a single object or List is expected) and an attribute parameter defining whether the join key is in the parent entity (myKey) or in the child entity (fKey).
When performing cascaded reads over joins, temporary tables retain each level of the nested hierarchy so that lower levels can use them in the same SQL block. Note that many-to-many joins have been implemented with an intermediate table which is an entity in its own right and which can also contain its own fields. But if you want to join from B->A as well as A->B then you will need a logical entity for each direction (in the sample database PersonExpenseFromExpenseItem and PersonExpenseFromPerson). This gives maximum flexibility but does not prevent further optimisation for a many-to-many join without the intermediate "link table" entity.
BEGIN TRANSACTION;
SELECT [id] ,[forename] ,[lastname] ,[shoesize] ,dbo.[Person].[managerid] _
INTO #tmpJ1 FROM dbo.[Person] WHERE id=@0id;
SELECT * FROM #tmpJ1;
SELECT dbo.[PersonExtraData].[personid] ,dbo.[PersonExtraData].[extradata] _
FROM dbo.[PersonExtraData] JOIN #tmpJ1 AS myjoin ON myjoin.[id]=[personextradata].[personid];
SELECT dbo.[Address].[id] ,dbo.[Address].[personid] ,dbo.[Address].[addr1] ,_
dbo.[Address].[addr2] ,dbo.[Address].[postcode] FROM dbo.[Address] _
JOIN #tmpJ1 AS myjoin ON myjoin.[id]=[address].[personid];
SELECT dbo.[Person].[id] ,dbo.[Person].[forename] ,dbo.[Person].[lastname] ,_
dbo.[Person].[shoesize] ,dbo.[Person].[managerid] INTO #tmpJ2 FROM dbo.[Person] _
JOIN #tmpJ1 AS myjoin ON myjoin.[managerid]=[person].[id];
SELECT * FROM #tmpJ2;
SELECT dbo.[PersonExtraData].[personid] ,dbo.[PersonExtraData].[extradata] _
FROM dbo.[PersonExtraData] JOIN #tmpJ2 AS myjoin ON myjoin.[id]=[personextradata].[personid];
SELECT dbo.[Address].[id] ,dbo.[Address].[personid] ,dbo.[Address].[addr1] ,_
dbo.[Address].[addr2] ,dbo.[Address].[postcode] FROM dbo.[Address] _
JOIN #tmpJ2 AS myjoin ON myjoin.[id]=[address].[personid];
SELECT dbo.[PersonExpense].[expenseitemid] ,dbo.[PersonExpense].[personid] ,_
dbo.[PersonExpense].[value of expense] ,dbo.[PersonExpense].[expenseid] _
INTO #tmpJ3 FROM dbo.[PersonExpense] JOIN #tmpJ2 AS myjoin ON myjoin.[id]=[personexpense].[personid];
SELECT * FROM #tmpJ3;
SELECT dbo.[ExpenseItem].[expenseitemid] ,dbo.[ExpenseItem].[name] _
FROM dbo.[ExpenseItem] JOIN #tmpJ3 AS myjoin ON myjoin.[expenseid]=[expenseitem].[expenseitemid];
DROP TABLE #tmpJ3;
DROP TABLE #tmpJ2;
SELECT dbo.[PersonExpense].[expenseitemid] ,dbo.[PersonExpense].[personid] ,_
dbo.[PersonExpense].[value of expense] ,dbo.[PersonExpense].[expenseid] _
INTO #tmpJ4 FROM dbo.[PersonExpense] JOIN #tmpJ1 AS myjoin ON myjoin.[id]=[personexpense].[personid];
SELECT * FROM #tmpJ4;
SELECT dbo.[ExpenseItem].[expenseitemid] ,dbo.[ExpenseItem].[name] _
FROM dbo.[ExpenseItem] JOIN #tmpJ4 AS myjoin ON myjoin.[expenseid]=[expenseitem].[expenseitemid];
DROP TABLE #tmpJ4;
DROP TABLE #tmpJ1;
COMMIT TRANSACTION ;
Stylistic Issues
The templated Entity type is the core of this implementation because it enables an unique static constructor to be called for each entity in the common Entity base class, keeping the Entity class clean. However since templated casts are cumbersome, extensive use is made of the dynamic keyword. For the same reason, static methods have been moved into the DAL and accessed by wrappers through an instantiated object (would you rather call person.List() or Entity<Person>.List()?). In fact, a common usage is to use an existing entity object and perform an entity operation on it, for example Create or Update. By default, the primary key is used as a selector in these cases.
A drawback of dynamic objects is that late-binding can allow errors to slip through, so it is essential to work with extensive unit tests and make certain that code coverage is high. Once the ORM itself is tested, usage of entity classes is easy and straightforward.
Because any public properties in the Base class will be serialised, I have used protected internal to expose Entity properties to the DAL layer, and public method calls to expose data which can be generated at each tier - rather than for such data to be serialised and copied around unnecessarily.
A for-each statement is very simple, even the most junior developer can read these in their sleep, but it can lead to code bloat with a great deal opening and closing braces. In general, I use for-each for simple loops and LINQ where a one-liner can replace complex code.
For example, the LINQ aggregate statement can be rewarding, but aggravating: if you can accept CSV-like output with a leading comma such as “,a,b,c” then you can simply cast the output like:
var x = list.Aggregate(string.Empty, (result, field) => result + "," + field.name));
but if you want output like “a,b,c”, you must first select the strings:
var x = list.Select(field => field.Name).Aggregate((result, fieldname) => result + "," + fieldname));
This is a bit non-obvious syntax to me.
Some interesting SQL issues I bumped into while researching this article
Like most of my readers, I suspect, I am a developer rather than a DBA. If so, there are a few things that might be worth you looking into:
Where Next?
This article is already quite long, so I have decided to reserve some further developments for the ORM for a "part 2". Principally, discussions of Service Layers and Caching, which in turn requires management of clean and dirty parts of the object graph. I would also like to put in simplified management of deletion of list items from a join - currently you would need to manually maintain a list of DELETE operations for each list item you delete. Meanwhile, if you find any errors send me a unit test!
History
- 18th June, 2014: First version
Check me out at LinkedIn: http://uk.linkedin.com/pub/simon-gulliver/20/303/251


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




