Introduction
Many weblogs I read are highly technical. That doesn't come as a surprise though, as I am software developer and also write about technical issues often. Some observations, tricks or techniques work better with source code to demonstrate them. In a way, it's similar to the old "picture is worth a thousand words" except that it's code that's worth a thousand words this time :-).
Modern development environments have spoiled me to the point that I cannot productively work in the Notepad for example, and the features I miss the most are intellisense and color coding of the source. This "bad" habit has extended to the Web and it becomes very hard for me to read non-color coded and poorly formatted source code.
I have seen many attempts at dealing with this issue. Most of them are based on regular expressions and color-coding simple things like keywords and strings, maybe comments. But these tools do not understand the structure of the code you're posting and will never be able to properly color-code most if not all of the constructs, nor can they format the code.
Enter the Colorizer.
Parsing is hard
Why don't existing tools provide better formatting and color coding? Because parsing is hard. I thought I knew well most of the C# language constructs before I started working on the Colorizer. Boy, was I wrong! Throughout the course of this project, I have run into several constructs I have never seen before. I have also learned to appreciate more the work of the guys building the C# compiler. If it takes a team of people in Microsoft to properly deal with this issue, how could I have done it alone and in my spare time?
Sir Isaac Newton said “If I have seen farther than others, it is because I was standing on the shoulders of giants”, and in this case, I was standing on the shoulders of Coco-R.
What is Coco-R
It's compiler compiler (I guess that's where coco comes from). You have probably heard of tools like lex and YACC - Coco-R is a modern version of these tools. What's really great about it is that there are ports to several languages including C#. This is very convenient because additional processing you may want to do during parsing can be written in the same language tool itself is written in - C#.
How does it work? Let's start with an example. Suppose you want to write a compiler/parser for Pascal. This language has its own grammar (just like spoken languages, except this grammar is simpler). There is a well known notation for expressing the grammar called (Extended) Backus-Naur Form. Input for Coco-R is called attributed grammar, it is modeled after EBNF notation and looks something like this:
Block = "begin" (. Console.Write("Inside a block!"); .) {Statement} "end" .
VarDeclaration = Ident {',' Ident} ':' Type ';'.
This describes a Block - it's something starting with text "begin", followed by zero or more Statement and then text "end". Statement itself needs to be further defined as well, up to the point when all constructs of the language are described in this manner. Second line describes the structure of variable declaration - it consists of one or many comma separated identifiers, followed by colon, then type of the variables, and finally a semi-colon - you get the idea. You can also see some C# code embedded in between (. and .). After the grammar is written, it is fed to Coco-R, which then produces C# code that is able to parse the language this grammar describes (and only this language, it is "hard-coded" to it). Embedded C# code above is inserted on a proper place, and becomes a part of the parser - for example, in the above case, your code will write "Inside a block!" to the console after the parser finds the text "begin" while parsing the Block construct.
Authors of Coco-R have produced the grammar file for C#, thus it is trivial to produce a parser for it. Since you can embed your own code in the parser, that's exactly what I did - as each construct is recognized, based on the information I keep internally, I add code with formatting and color information (I just wrap code in span elements of named CSS classes so that I can use CSS to customize colors) to an instance of StringBuilder. Some of the information I keep internally:
- nesting depth - if I am inside the block (and at which level) so that I can increase/decrease indentation.
- scope (namespace, class or function) to be able to recognize local variables or fields correctly.
- pragma information, so that I can enable region expanding/collapsing.
Note that when you have a small snippet of code, it is impossible to do 100% correct parsing so on some places I had to guess based on all the info I got. In any case, my code is separated from the rest of Coco-R code and is marked with "My auxiliary methods" in the file CSharp.atg (attributed grammar for C# 1.1, provided by Coco-R, that I modified) so you can examine it in more detail. The pipeline looks like this:
- C# Grammar (with my embedded code) »» Coco-R »» C# Parser/Formatter/Colorizer.
- C# source code (code to post to the Web) »» C# Parser/Formatter/Colorizer »» HTML fragment.
Coco-R produces a parser that consists of three important classes - Scanner, Parser and Errors. They all contain (very few) static methods/fields and are easy to use (this is a Helper class that contains the core parsing routine I will refer to frequently later on):
internal class Helper
{
private static Object _lock = new Object();
public static String CodePath
{
get { return ConfigurationSettings.AppSettings["CodePath"]; }
}
public static String StylePath
{
get { return ConfigurationSettings.AppSettings["StylePath"]; }
}
public static String FromFile(String path)
{
lock (_lock)
{
Scanner.Init(path);
return Colorize();
}
}
private static String Colorize()
{
Parser.Reset();
Parser.Parse();
if(0 == Errors.count)
return Parser.Colorized;
else
return String.Format(@"Parse complete -- {0} error(s) detected",
Errors.count);
}
public static String FromString(String code)
{
lock (_lock)
{
using(MemoryStream ms = new MemoryStream(Encoding.UTF8.GetBytes(code)))
{
Scanner.Init(ms);
return Colorize();
}
}
}
}
You always need to initialize Scanner, either with a path to a file or a Stream. To make things easier, I added two small wrappers: FromFile and FromString; the latter one wraps String into a Stream and initializes with that. Then you reset the parser state with Reset (resets error count to zero and clears the above mentioned StringBuilder). Then you call Parse and check the error count in Errors.count. If it is zero, you'll find the result in the property Colorized that returns the text of the colorized code (basically getting the string value of the above mentioned StringBuilder). The lock block is there so that you do not start parsing one fragment while another one is being parsed - don't forget, ASP.NET will execute your page code on a random thread from a thread pool, and since we want to use this code from an ASP.NET application, we need to make sure parsing is serialized. There were many small details I had to take care of, even slightly changing some of the grammar rules in order to be able to recognize every possible context properly. But the result is a full blown C# parser with formatting and coloring on top. All the colors are customizable via a single CSS file (style.css), excerpt provided here:
pre.code .key /* keyword: this, for, if, while... */
{
color:Blue;
}
pre.code .typ /* type: any FCL type or your type */
{
color:Navy;
}
pre.code .met /* method */
{
color:Maroon;
}
pre.code .var /* local variable, or parameter */
{
color:Gray;
}
pre.code .str /* hard-coded string (not variables of type string!) */
{
color:Olive;
}
pre.code .num /* hard-coded number (not variables of numeric types!) */
{
color:Olive;
}
pre.code .val /* enumeration values */
{
color:Purple;
}
Current limitations and extras
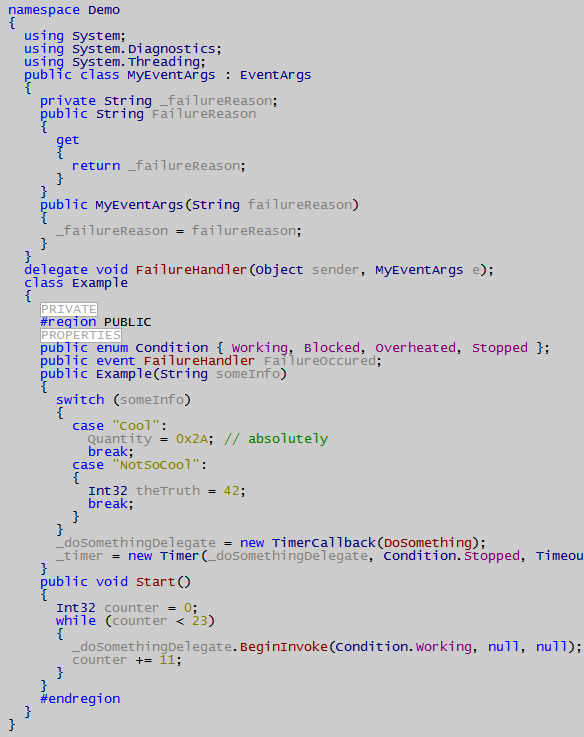
Some symbols are not recognized properly because they are defined later. For example, you use an enum in a method of a class, but the enum is defined after the method. This code is legal, but the parser does not "see" the enum until it reaches it. Solution would be to use two passes, but for simplicity, I opted for one pass only. In the example code provided, you can actually see this problem in action.
Formatting rules are not customizable. There is no way at the moment to specify whether you like your opening curly braces on the same line, whether you put a space between a function call and opening bracket etc. This is very easy to change if you'd like to play with the code provided. Current defaults are to use as little whitespace as possible while preserving readability, to always put curly braces on a new line, and to indent with two spaces.
There is no support for C# 2.0 (generics, iterators, partial classes etc.) at the moment. Coco-R authors have recently produced grammar for C# 2.0 thus making this job a lot easier. Basically, all you'd need to do is use more or less the same code I did for C# 1.1 and integrate it into this grammar. I might do this for one of the later revisions of this code if there's enough interest.
In case you have a relatively large C# code snippet, fear not - I have added support for regions. With just a bit of JavaScript (note that it therefore must be enabled on the client), you can condense/expand regions just like in Visual Studio (script is in code.js file)! Plus, the code works in both Internet Explorer and Mozilla Firefox (6.0 and 1.0 versions tested, respectively).
Using the parser
Now that we have an easy way to do what we want (format and colorize C# source code), how do we use it with as little hassle as possible? Well, it turns out there are four basic ways to use this code:
- Static parsing of source code, producing HTML files for direct consumption.
- ASP.NET Handler that parses on the fly any *.cs file.
- ASP.NET Web control, pointing to source code file on the disk or wrapping code directly, parsing on the fly.
- ASP.NET Module that parses on the fly specifically marked code segments in the output stream.
Let's examine each of these solutions.
Static parsing
This is the simplest way - I have provided a trivial console application that accepts a path to the C# source file and produces an HTML file with the desired name. Code consists of the core parsing routine (see above) and a bit of command line options handling - a dozen or so lines of code. The resulting HTML contains a reference to the JavaScript code (region handling) and a reference to the CSS style sheet, thus these two files must be kept in the same directory with the resulting HTML files (both files are provided in the source download archive). While being least flexible, this approach offers the best performance - all files are processed before posting to the Web.
ASP.NET Handler
Having a handler is slightly more flexible than pre-processing a C# source file, but it does incur a performance penalty - now your code is parsed each time a user accesses a C# source file. If your visitors browse the site frequently, you might want to employ some caching to amortize for this performance hit. Why would you want to expose C# source code directly? Well, maybe you have a Web view of your source code repository that is public (or just for you) where files change all the time and you don't want to (re)process them whenever they change. Note that by default ASP.NET explicitly prohibits clients to access *.cs files directly in the URL, presumably so that you don't accidentally reveal your web site source code to the visitors. Take a look at the machine.config, it should be in <windows_folder>\Microsoft.NET\Framework\<framework_version>\config\machine.config. Do not modify this file! ASP.NET architecture allows you to set up configuration on a very fine grained level, up to the last subfolder in the hierarchy of folders of your web site. The machine.config supplies reasonable defaults that you can always override. The setting we are about to override is in the following section:
<httpHandlers>
<add verb="*" path="*.config" type="System.Web.HttpForbiddenHandler"/>
<add verb="*" path="*.cs" type="System.Web.HttpForbiddenHandler"/>
<add verb="*" path="*.csproj" type="System.Web.HttpForbiddenHandler"/>
<add verb="*" path="*.vb" type="System.Web.HttpForbiddenHandler"/>
<add verb="*" path="*.vbproj" type="System.Web.HttpForbiddenHandler"/>
</httpHandlers>
As you can see, many of the source code files are associated with HttpForbiddenHandler, which means you won't be able to use them in URLs. We can still allow this in our own web.config file with the following line:
<httpHandlers>
<add verb="GET" path="*.cs"
type="NanoBriq.Colorizer.Web.Handler, NanoBriq.Colorizer.Web"/>
</httpHandlers>
Now, any URL ending with *.cs will be handled by NanoBriq.ColorizerWeb.Handler. Implementing handlers is very simple - you just have to inherit from System.Web.IHttpHandler and implement one method and one property, like this:
namespace NanoBriq.Colorizer.Web
{
public class Handler : IHttpHandler
{
public Boolean IsReusable
{
get { return false; }
}
void ProcessRequest(HttpContext context)
{
String path = context.Server.MapPath(context.Request.FilePath);
context.Response.Write("<html><head><script>");
context.Response.WriteFile(Helper.CodePath);
context.Response.Write("</script><style>");
context.Response.WriteFile(Helper.StylePath);
context.Response.Write("</style></head><body>");
context.Response.Write(Helper.FromFile(path));
context.Response.Write("</body></html>");
}
}
}
It boils down (again) to using core parsing routines from above and not much anything else. We inline JavaScript and CSS in the <head> tag and that's it. From this point on, if you type something like http://localhost/colorizer/demo.cs (assuming your virtual directory is set up as "colorizer" and that it contains file named demo.cs), you will get back nicely formatted and colored C# source code.
ASP.NET Web control
Colorizing whole C# source files is fine and works great, but sometimes you need just a bit more flexibility. Maybe you frequently write articles, have a blog, or even have a CodeProject-like site where others contribute tips and tricks. If so, you have a lot of text with embedded snippets of code that you still want to format and colorize. For all those cases where the Web server is under your control so that you can frequently do build your own *.aspx pages, this solution fits nicely. Here's what you'd do:
<%@ Page language="c#" %>
<%@ Register TagPrefix="nbc"
Namespace="NanoBriq.Colorizer.Web" Assembly="NanoBriq.Colorizer.Web" %>
<html>
<head></head>
<body>
<form id="frm1" runat="server">
<p>Some great programming technique...</p>
<nbc:WebUIControl id="ctlr1" Path="Demo.cs"/>
<p>More of the same...</p>
<nbc:WebUIControl id="ctlr2">// Some inline code
String fileName;
Boolean itIs = Path.IsRooted(fileName);
// ...
</nbc:WebUIControl>
<p>Closing thoughts...</p>
</form>
</body>
</html>
There are two ways you can use this control - by pointing to a file on the disk with the SourcePath property (control with ID ctrl1), or by putting some C# code inline (control with ID ctrl2). Don't forget to register the colorizer control with ASP.NET with the Register directive - from that point on, you can use it in much the same way you use ASP.NET controls. It is not too hard to implement a simple Web control.
namespace NanoBriq.Colorizer.Web
{
public class WebUIControl : Control
{
private String _path;
public String SourcePath
{
set { _path = value; }
}
protected override void OnInit(EventArgs e)
{
String code, style;
using (TextReader tr = new StreamReader(Helper.CodePath))
code = tr.ReadToEnd();
Page.RegisterClientScriptBlock("CodeClientBlock",
"<script>" + code + "</script>");
using (TextReader tr = new StreamReader(Helper.StylePath))
style = tr.ReadToEnd();
Page.RegisterClientScriptBlock("StyleClientBlock",
"<style>" + style + "</style>");
}
protected override void Render(HtmlTextWriter writer)
{
String toOpen = _path;
if(null != _path && "" != _path)
{
if(!Path.IsPathRooted(_path))
toOpen = Context.Server.MapPath(_path);
writer.Write(Helper.FromFile(toOpen));
}
else if(1 == Controls.Count && Controls[0] is LiteralControl)
{
toOpen = HttpUtility.HtmlDecode(((LiteralControl)Controls[0]).Text);
writer.Write(Helper.FromString(toOpen));
}
}
}
}
As a minimum, you should implement Render, but in this case, we need to do a bit more in the initialization method OnInit. The problem is that we need to embed both CSS and JavaScript, but do not want to do it multiple times in case there is more than one custom control on a single page. Thus in OnInit, we call Page.RegisterClientScriptBlock that will make sure that if called multiple times with the same key (first parameter), the page does not end up with multiple copies of the value (second parameter). Core functionality of the Web control is (again) not much more than the core parsing routine with a check if SourcePath property is set or if the control contains the embedded source.
ASP.NET Module
Finally, if you want the most flexible solution, then you'd go this route. The problem with the last approach is that you can't always make sure that your code snippets are embedded in your control (or referenced from it). For example, you have a blog that you edit via internal control that allows you to use WYSIWYG mode or HTML mode, but neither assumes you'll add code to your aspx pages - it's all just content. The best thing you can do here is to mark your code snippets with a special tag, for example <pre class= "csharp_source">...</pre>. Notice that this is very similar to what you'd do when posting articles to this very site - article submission rules state that if you want your snippets colorized, then you should wrap them in <pre lang= "XX"></pre> blocks. Idea is that all output will be processed, these special tags found, and code parsed/formatted/colorized on the fly. It's extremely powerful, but incurs the greatest performance penalty since now all your outgoing content is checked for the presence of these special tags. We can to a certain extent amortize the cost of this by only checking certain content types, but in the most common scenario, practically all of the pages will be of HTML content type anyway, so have this in mind. Do not mix and match this solution with the previously listed ones! You could end up trying to parse the same code twice (if the <pre> tag uses the same class attribute) which could lead to all kinds of weird results. Here's what Module implementation looks like:
namespace NanoBriq.Colorizer.Web
{
public class Module : IHttpModule
{
public void Init(HttpApplication context)
{
context.BeginRequest +=
new EventHandler(OnBeginRequest);
}
private void OnBeginRequest(Object sender, EventArgs args)
{
HttpApplication context = sender as HttpApplication;
context.Response.Filter = new Filter(context.Response.Filter);
}
public void Dispose()
{
}
}
}
This is a classic approach to output filtering - ASP.NET has built-in support for that. First, you need to subscribe to the BeginRequest event that will fire each time a new request comes in - great place for that is the handler's Init method. Then you build your custom Stream derived class and put it into Response.Fiter property making sure you save the previous value first (I keep it in the _inner member of my Filter class). Now all output will go through your code where you can either just pass it through or modify it. Stream is an abstract class that has quite a few methods and fields, but most of them can be implemented as simple forwards to _inner Stream. The interesting stuff happens in the Write method:
internal class Filter : Stream
{
private Stream _inner;
private StringBuilder _toParse = new StringBuilder(1024);
private Int32 _colorized = 0;
internal Filter(Stream inner)
{
_inner = inner;
}
private String AddScriptStyle(Match match)
{
String code, style;
StringBuilder whole = new StringBuilder();
whole.Append("<head>").Append(match.Groups["head"].Value);
using (TextReader tr = new StreamReader(Helper.CodePath))
code = tr.ReadToEnd();
whole.Append("<script>").Append(code).Append("</script>");
using (TextReader tr = new StreamReader(Helper.StylePath))
style = tr.ReadToEnd();
whole.Append("<style>").Append(style).Append("</style></head>");
return whole.ToString();
}
private String ColorizeCodeSegment(Match match)
{
_colorized++;
return
Helper.FromString(HttpUtility.HtmlDecode(match.Groups["toParse"].Value));
}
public override void Write(byte[] buffer, int offset, int count)
{
String piece = Encoding.UTF8.GetString(buffer, offset, count);
_toParse.Append(piece);
if(!Regex.IsMatch(piece, "</html>", RegexOptions.IgnoreCase))
return;
String result = Regex.Replace(_toParse.ToString(),
@"<pre\s+class\s*=\s*['""]csharp_source[""']\s*" +
@">(?<toParse>[\w\s\W\S]*?)</pre>",
new MatchEvaluator(ColorizeCodeSegment), RegexOptions.IgnoreCase);
if(_colorized > 0)
result = Regex.Replace(result,
@"<head>(?<head>[\w\s\W\S]*?)</head>",
new MatchEvaluator(AddScriptStyle), RegexOptions.IgnoreCase);
Byte[] all = Encoding.UTF8.GetBytes(result);
_inner.Write(all, 0, all.GetLength(0));
}
}
Instead of implementing a complex state machine tracking if we are at the beginning, inside or outside of our custom <pre> block, I decided to simply wait for the </html> closing tag, and buffer all the output up to that point. In order to match a custom <pre> tag and get its inner text in one shot, I used a somewhat complex regular expression that in English reads "match all <pre class="csharp_source"> (with some spaces between class and = and with apostrophe instead of quote potentially) then match (and store into named group 'toParse') anything until you match </pre>". There can be multiple blocks of this kind per page - we need to replace each one of them with formatted and colorized code. Regex support in .NET is great and it allows us to do everything in a single line with Regex.Replace! For each matched block, our evaluator will be called through MatchEvaluator delegate and what it returns will replace the matched block - perfect for our needs! Thanks to the named group "toParse", extracting code to parse is trivial and the rest is the usual core parsing routine, for the fourth time :-) We also need to add script and CSS content in the <head> element (just append it to the content already there). In order to make our module active, we need to add the following to web.config - do it only for the folder where you want this processing to take place!
<httpModules>
<add name="ColorizerModule"
type="NanoBriq.Colorizer.Web.Module, NanoBriq.Colorizer.Web"/>
</httpModules>
One last thing - I have assumed that all your files and pages are UTF-8 encoded. If that is not the case, either use Response.ContentEncoding or make sure your files are saved so that you can detect encoding properly.
What's in the package
The source code download contains everything you need to build and use the colorizer. Due to complex build requirements - we need to build Coco-R first, then parser sources from the attributed grammar, then the core parsing code, and finally Web components - I have used NAnt for building. The version used was 0.85 RC3, there shouldn't be any significant differences between this and the final version, but keep that in mind. I have also provided a test folder with some .aspx files that exercise the code. All you need to do is to create a virtual directory and point to this test folder and to configure the paths (in web.config) to the JavaScript region code and the CSS style sheet for colors. That's it! I hope you enjoy using this code as much as I enjoyed writing it.
History
- March 13, 2005: Version 1.0.
- July 8, 2005: Version 1.01. Thanks to Hanspeter Mössenböck (author of Coco/R) for providing a workaround to properly detect C-style comments.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 It might not be obvious, though. You need NAnt to build all the DLLs, any latest version should do fine. The definition of build is in the .build file. This file is XML thus human readable. Even without any knowledge of NAnt you should be able to roughly read it - take a look at build.colorizer.core target and you'll find out how core DLL is built. Once NAnt executable is in you path, just execute it in the colorizer source folder and all the targets will be built.
It might not be obvious, though. You need NAnt to build all the DLLs, any latest version should do fine. The definition of build is in the .build file. This file is XML thus human readable. Even without any knowledge of NAnt you should be able to roughly read it - take a look at build.colorizer.core target and you'll find out how core DLL is built. Once NAnt executable is in you path, just execute it in the colorizer source folder and all the targets will be built.
