Introduction
Last time, I showed how to use yomm11 to create methods for a matrix class. This article and the next will explain what goes on inside the library. In this installment, I will describe the data structures and algorithms, mostly from a language neutral point of view. The fourth and final article will cover the challenges posed by C++ and how the new C++11 constructs help address some of them.
Example Hierarchy and Methods
In the following discussion, I will use two class hierarchies and two methods - one with a single virtual argument and the other with two. Together, they are part of an imaginary payroll and expense refund and approval system. I don't claim that the example is very realistic, but my goal is to depart from many multi-method papers that show you just one hierarchy and one method with two arguments of the same type (e.g. intersect(shape, shape)).
The class hierarchies are as follows:
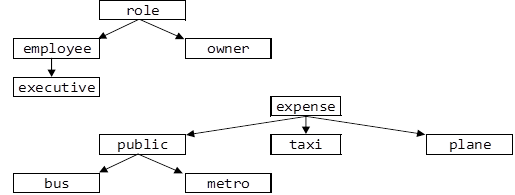
("public" is short for "public transportation")
We also have two methods with the following specializations:
pay(employee) -> salary
pay(executive) -> salary + bonus
approve(role, expense) -> false
approve(employee, public) -> true
approve(executive, taxi) -> true
approve(owner, expense) -> true
The Resolution Table
yomm11 uses a table of function pointers to dispatch method calls efficiently; this is similar to how C++ implements virtual functions, only the table can be multi-dimensional. Each method has its own associated table. Here are the dispatch tables associated to pay and approve:

(empl = employee, exp = expense, exec = executive)
Although the hierarchies are small, and the specializations are few, the dispatch table for approve contains no less than 24 pointers. This is the major problem with the dispatch table approach: the size of the table can grow very quickly. There is no general solution to this problem, but in many cases it can be mitigated. Indeed, we observe that the columns for classes public, bus and metro have exactly the same content. This is normal, because the specialisations of the approve method do not discriminate between them; as far as approve is concerned, the three classes are one and the same.
It is thus possible (for approve) to group all public transportations together and assign a single column to it; expense and plane can also use the same column:
This spares 12 cells in the table. Note that this technique is also applicable in situations with only one virtual argument, and yields excellent results. Imagine that the role hierarchy is expanded to include two subclasses of employee: intern and perm; and two subclasses of executive: junior and senior. The dispatch table for pay would look like this:
The Index Table and the Slot Table
The next problem is, how do we map classes to row and column numbers - or to indexes, as I will call positions in tables from now on?
Obviously, we cannot assign a single, global index to a class; that would result in humungous dispatch tables mostly filled with unused cells. We cannot even assign indexes on a hierarchy basis: if you look at the dispatch tables above, employee occupies row zero in pay's table but row one in approve's. Furthermore, the same class may appear several times in the virtual arguments of a method, and thus be present in several dimensions of the dispatch table - but not necessarily at the same index. It follows that each class contains a vector of indexes - one for each time it appears as a virtual argument in a method. The method, in turn, knows which entries in the index vectors are assigned to each of its virtual arguments. These positions are recorded in a vector of "slots". Each method has one, with one entry per virtual argument.
Here is a recap of the tables involved in our example:
Let's walk through a couple of calls.
pay(role), and role is executive:
- from
pay's slot table: use index[1] - from
executive's index table: use row 1 - call
pay[1]
approve(role, exp), role is owner and exp is plane:
- from
approve's slot table, for first argument (role ): use index[0] - from
approve's slot table, for second argument (expense hierarchy): use index[0] - from
owner's index table, for first argument: use row 3 - from
plane's index table, for second argument: use column 3 - call
approve[3][3]
Note on Abstract Classes
It looks like more space can be regained in approve's dispatch table by removing the first row and the first column, if classes role and expense are abstract. In fact, it depends on the language. In C++, surprising as it may seem, it is possible to observe pure roles and expenses: inside constructors and destructors. yomm11 allows calling methods from these special places and in fact mimics the behavior of virtual function calls in constructors and destructors.
Let's take a (high-level) look at the algorithms now...
Creation of the Index and the Slot Tables
yomm11 partitions the classes involved in methods into "forests". A forest of classes is the set of all the classes that can be reached from one another by traversing inheritance relationships - either from base to derived or from derived to base.
For each forest, yomm11 sorts the classes in a vector in such a way that a class always precedes its derived classes (if any). Each class then gets an integer identifier - its position in the vector. Once that is done, a bit mask is assigned to each class, with bit i corresponding to class i. For each class bit mask, the bits corresponding to the class and its (direct or indirect) derived classes are set to one. The algorithm for assigning positions Pi inside classes Pi to virtual method arguments proceeds as follow:
- let V be a vector of bit masks, initially empty
- for each class Ci in the sorted vector:
- let Mi be the mask associated to class Ci
- for each method, for each virtual argument of this class:
- search V for a mask Vj such that Vj & Mi = 0
- if there is one:
- otherwise:
- Pi = size of V
- append Mi to V
- append Pi to the method's slot table
Creation of the Dispatch Table
Amiel, Gruber and Simon describe a method for constructing "compressed" dispatch tables in their paper Fast Algorithms for Compressed Multi-Method Dispatch Tables Generation. They point out that the naive approach of building a straight dispatch table like the very first one I presented, then compressing it to eliminate redundant rows is both costly and likely to fail in some situations - the compressed table might well fit in memory while the initial, uncompressed table might not.
While the article was inspirational in developing my algorithm, I think that it makes use of a complex conceptual apparatus based on the close examination of the inheritance graphs. To be honest, at one point, I could not quite follow their algorithm on the basis of the example they give; I don't know if it is a problem with me or with the article. In any case, I had to come up with my own method, which I believe is equivalent and simpler to understand.
First let me introduce a few notations and definitions.
Let A and B be two classes:
- A = B means that A and B are the same class.
- A < B means that A is a subclass of B.
- A <= B means either A = B or A < B
- Applicable specialization:
- A specialization S(A1,...,An) is applicable for argument i to a class B iff Ai <= B. The specialization is applicable to a n-uplet of classes { B1,...,Bn } if it is applicable for all its arguments.
- More specific specialization:
- A specialization S1(A1,...,An) is more specific than a specialization S2(B1,...,Bn) iff:
- There is at least one argument i for which Ai < Bi
- There is no argument i for which Bi < Ai
- Most specific specialization:
- Given a collection of specialisations of the same method; the most specific specialization is the specialization that is more specific than all the others. It may not exist.
Given:
- A method M(B1,...,Bn)
- A collection of specialisations Si(D1,...,Dn) of this method, where Ci <= Hi.
The dispatch table is filled in two phases:
- First let us consider the arguments taken separately. For each argument i:
- Make the se Hi of the classes Hij such that Hij <= Bi. In other words, Hi is the hierarchy rooted in Bi.
- For each class in Hi, make the set A(Hi) of the applicable specialisations for argument i.
- Make the partition Pi according to the equivalence relationship: A(X) = A(Y). In other words, group the classes that have the same sets of applicable specialisations for argument i. Each group Gij becomes a row in dimension i of the dispatch table and its index j is written in the index table of each class belonging to the group.
- Make the cross product of partitions Pi. Elements Xk of this product consist in sets of Gij groups of classes, and correspond to cells in the dispatch table.
For each element Xk of the cross product:
- For each group Gij: make the set A of the specialisations applicable to the classes in Gij.
- Make the intersection Sk of the sets Aij - it is a set of specialisations.
- Find the most specific specialization S1 in Sk. If it exists, write it to the dispatch table. Find the most specific specialization S2 in the set Sk - S1. If it exists, it is the specialization returned by
next in S1.
Conclusion
In this article, I described the data structures and algorithms that underpin yomm11, but much of the material covered here is applicable to any implementation of multi-methods based on tables of pointers.
C++ adds challenges of its own. In the final article of this series, I will describe and address them. I will also show how new C++11 features like variadic templates make it possible to support a nice, unconstrained syntax.
I am a software engineer with over 25 years of experience. My main points of interest are: C++, Perl, object-relational mapping, multi-methods. I am the original author of Tangram, an orthogonal object-relational mapper for Perl.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







 Maybe during this Christmas holiday.
Maybe during this Christmas holiday. I once wrote a C++ preprocessor for things like this (in Python), until I discovered your library. I'm also completely sold on the importance of open multimethods in C++, but it doesn't seem like we can expect it soon
I once wrote a C++ preprocessor for things like this (in Python), until I discovered your library. I'm also completely sold on the importance of open multimethods in C++, but it doesn't seem like we can expect it soon