Introduction
html2struct is intended as an aid when data-mining from external HTML sources.
It makes it easy to extract data from HTML files based on tag-structure with attributes without being reliant on other content that may change and cause the extraction to fail.
It parses HTML code into a simple tree-like structure of objects and provides a little tool-set to extract data from it. It is a light-weight parser that does not rely on resource hungry external stuff like browsers or DOM objects. It just creates a simple tree made of htmlTag objects.
It does NOT generate HTML, run scripts or fetch any external references.
It makes no attempts to enforce HTML document standards and does not care about conforming to them like having to have <HTML> or <BODY> tags. This makes it easy to parse any segments of HTML code into a structure which as far as I know differs this solution from other HTML/XML parsers I've seen so far.
In theory, it should parse other Markup Languages as well, like XHTML, XML, SGML and other variants. Currently, this is mostly untested territory, but I've tried it on a few RSS sources where it parses XML just fine and in time, I hope to make this parser capable of handling all Markup Languages similar to HTML.
Background
I have been developing a search engine that specializes in mini-ads/classifieds, collects them from different sources and allows people to search them. I like to call it a kind of localized mini-Google and today, I index up to 2.000 advertisements from 20 different sources each day. This project requires a lot of data-mining from different HTML pages represented in distinct ways to extract a uniform data material which people can then search.
I'm a big fan of regular expressions and had been using them to isolate the data from those HTML sources until now, but after struggling with it for months while fine-tuning ridiculously complex expressions, I came to the conclusion that it was too hard to define a "correct" expression for ever changing data sources.
I have repeatedly found my search engine to mine data incorrectly after someone makes a minor changes to their HTML code and these changes can be notoriously hard to debug. These changes would include adding or removing HTML Tags, adding/removing/swapping the order of attributes in an element, even adding a single space somewhere could easily cause a problem. As much as I tried to anticipate those changes, I found it impossible and the expressions seized to match repeatedly.
This problem called for a different approach. I wanted to be able to parse HTML code regardless of its casing, order of elements/attributes, white-spaces or compliance to specific HTML standards.
After a bit of searching, I decided to make my own parser since all the existing solutions I found seemed to include a full-blown browser or a DOM object generator to do the parsing and tended to reject the HTML code as a whole if it did not comply to some particular standards or had errors in it.
Finally, I decided to share this in the open source community. This is the first time I do this in an official manner which I have been wanting to do for a long time. I hope you'll find this class useful and certainly hope I'm not reinventing the wheel.
Definition
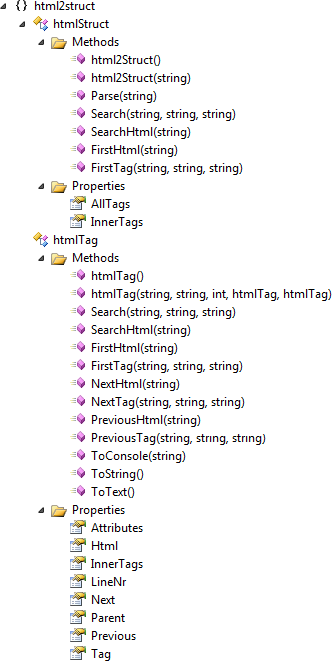
This library consists of 2 classes, the main class called htmlStruct and htmlTag which represents the tags within the structure. As the Class View demonstrates, the structure is quite simple.
A Word on Attributes
The htmlStruct class has only 2 attributes:
AllTags - holds all parsed elements in a HTML documentInnerTags - represents the tree-structure and tends to hold top-level elements such as <HTML> and <HEADER>. It is the list intended for navigating down the HTML tree.
htmlTag is the class intended to be extracted from and has a few attributes for navigation and data extraction.
Tag holds the name of the current tag of course.Attributes provides a Dictionary type access to attributes, such as 'src' and 'href', defined with the current tag.Html holds the HTML source used to create the tag. In case of <TEXT>, it holds the text.LineNr has the line position in the HTML source where the tag was parsed for debugging purposes.InnerTags holds the tags that were found within the opening/closing of the current tag, which then can have their inner tags, etc.Next, Previous and Parent are intended for navigation from a current tag that has been isolated with a search function.
A Word on Functions
As a rule of thumb, functions in the htmlStruct class operate on AllTags and search the whole document, functions in htmlTag operate recursively on InnerTags and do not search outside the scope of the current tag.
Parse() - Takes a HTML document as string, populates the attributes and generates the tree structure.Search() - Returns a list of tags that match all given search expressions based on tag name, attribute or value.SearchHtml() - Returns list of tags that match a regular expression from their Html attribute.FirstTag() - Returns the first tag that matches all search criterias based on tag name, attribute or value.FirstHtml() - Returns the first tag that matches a regular expression from its Html attribute.NextTag() - Returns the next subsequent tag that matches all given search expressions regardless of whether it is an inner tag or not.NextHtml() - Returns the next subsequent tag that matches a regular expression from its Html attribute regardless of whether it is an inner tag or not.PreviousTag() - Returns the previous antecedent tag that matches all given search expressions regardless of whether it is an inner tag or not.PreviousHtml() - Returns the previous antecedent tag that matches HTML expression regardless of whether it is an inner tag or not.ToText() - Extracts text from current tag and its inner tags. If it runs into <BR> or <P> tags, they get treated as newlines.
A Word on Search Criterias
All Search(), FirstTag() and PreviousTag() functions accept the same search parameters, name of tag, attribute and value. Also they take a case-insensitive regular expression as search string. They will then do a search returning tags where all given expressions are true. If name of tag is given, it will return tags with names that match. If attribute is given, it return tags with attribute names that match. If value is given, it will return tags with any attributes having values that match. If both attribute and value is given, it will return tags with attribute names that match having a value that match (hmm, getting kinky...).
A Word on <TEXT>/<COMMENT>/<SCRIPT>
To keep things simple, I decided to represent text and comments as tags too, but they actually appear between tags in HTML. This allow you to easily search for <TEXT> or <COMMENTS> tags using the search functions. Also, when the parser runs into scripts, it just creates the <SCRIPT> tag and puts the code in the HTML attribute.
Note that I do not bother with creating closing tags as objects since they are not necessary to represent the structure per se.
Using the Class
Operating the Main Class
When using this solution, you will find that extracting data from HTML becomes ridiculously simple.
using System.Collections.Generic;
using html2struct;
htmlStruct tree = new htmlStruct(strHTML);
tree.Parse(strHTML)
Quick Examples of How I Find Myself Using the Classes
I like to define a temporary tag (t) which I then use when extracting data. This prevents "Object reference not set to an instance of an object." errors, allows for sequential searches, and also helps with debugging.
string sTitle = tree.FirstTag("<H3>", "", "").ToText();
List<htmlTag> list = tree.Search("<TEXT>|<COMMENT>", "", "");
List<htmlTag> list = tree.Search("", "href|src", "");
string sImage = (t = tree.FirstTag("<IMG>", "src",
"")) != null ? t.Attributes["src"] : "";
string sEmail = (t = tree.FirstTag("<A>", "href",
"mailto:")) != null ? t.Attributes["href"] : "";
string sPrice = (t = tree.FirstHtml("^Price$")) != null ? t.Next.ToText() : "";
htmlTag tag = (t = tree.FirstTag("<BODY>", "", "")) != null &&
(t = t.FirstHtml("<div class=\"details\">")) != null ? t : null;
List<htmlTag> list = (t = tree.FirstTag("<DIV>", "class", "some-listing")) != null ?
t.Search("<DIV>",
"class", "entry( grey)?") : null;
Also, most pages have a <DIV> block that holds all the data I'm interested in. In that case, I isolate that tag first and then search within it.
htmlTag ad = tree.FirstTag("div", "class", "Details");
if (ad != null)
{
htmlTag t;
string sTitle = (t = ad.FirstTag("<H3>", "", "")) != null ? t.ToText() : "";
}
Conclusion
Regular expressions, as powerful as they are, are not ideal for data mining. They tend to get big and extremely complex, very quickly. Slightest variation in code, such as adding a single space can easily cause it to stop matching and can be notoriously hard to debug.
I gave up on relying on regular expressions for my search engine and decided to make this library in order to combine the awsome pattern matching abilities of regular expressions with functionality, which then can be directed in text.
After a bit of messing around with html2struct, I find it quite tolerant to changing HTML code. I find it easy to re-use existing code on new HTML sources with just minor changes to search parameters instead of having to rewrite a massive regular expression.
html2struct does not care about changing order of tags or attributes, adding or removing of HTML elements as long as you don't rely on them directly. It does not even care about structural changes, and they can move entire segments of a page, as long as they don't change the tags/attributes you explicitly search for.
html2struct handles data-mining much better than regular expressions alone. In fact, they do not even compare to this approach and I kinda regret not doing this before...
Known Issues
It's a good idea to keep in mind that when dealing with HTML code, we are basically dealing with pure unchecked user input. There is no saying what kind of crap people may insert into the code, wittingly or unwittingly. I have debugged this solution as far as to be able to use it without problems, but there are undoubtedly numerous issues that are going to surface now since I decided to share it.
- Nested comments and scripts don't get handled correctly. E.g. "
<!-- rem <!-- more rem --> -->" will cause the parser to skip the last "-->" from the comment and insert it as <TEXT> tag afterwards. Here, I run into issues with regular expressions dealing with nested/recursive patterns. - Unnamed tags such as "
<<em>desperately</em> important>" cause the parser to ignore the opening tag, continue as normal, but finish off with a <TEXT> tag with "important>" as HTML. - Currently
Next and Previous point at tags in the order they were discovered during parsing. As a consequence, Next of a parent element points at its first InnerTag instead of pointing to the next tag that came after it on the same level. Previous also points at the last tag regardless of whether it is a child element of a parent tag that came before the current tag on the same level. For example, if I'm looking for a text following some tag t but t has 2 child tags, I would have to refer to the text as t.Next.Next.Next instead of just t.Next. Guess we can call this depth-first navigation instead of breadth-first navigation. I have not quite decided whether I should change this, so I'll wait for some social pressure.
History
- 2-7 April, 2018: Have been finalizing article and fixing minor issues. Apologies to the editors for all the minor fixes.
- 4 April, 2018: Ran into a
<![DATA[...]]> element which was not recognized while testing various sources. Fixed that and republished library as version 5. - 30 October, 2018: Fixed a few bugs, reviewed the article and published as version 6.
- Fixed a bug where attributes without quotes were not handled correctly.
- Changed how opening/closing tags are handled, instead of assuming opening tags to be parents of subsequent tags, which could cause single tags to be treated a child tags, I now use closing tags to assume previous tags are child tags.
- Found a minor bug when removing unrecognized stuff from the HTML text. If there was no
< in the source, it did not remove the text and got stuck in an endless loop. - Added
SearchHtml(), NextTag(), NextHtml(), PreviousTag() and PreviousHtml() to the search functions.
Note: Had to rename the attributes Next from NextTag and Previous from PreviousTag in order to prevent ambiguity. - Found errors in how
datastructure was generated around nested elements causing malformed tree structure. Added Status attribute to htmlTag in order to follow which previous Tags had been closed when parsing.
- 29 October, 2018: Found a few spelling errors and added a whole sentence


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






