Introduction
We introduce a queue based architecture for executing concurrent tasks in a real time enterprise system with high scale. The architecture provides a framework wherein tasks are executed in a structured fashion, which reduces unpredictability and enables engineers to easily and quickly reproduce and debug customer escalations.
Background
High scale systems with high concurrency level usually deals with two major challenges: scalability & supportability.
- Scalability: Consider a system with a single database server and one or more application servers who need to support hundreds of clients. The server receives many requests simultaneously from each client, which requires from the server to process and respond to each request quickly, along with handling multiple internal jobs. This large amount of simultaneous tasks handling may cause a sever load on the server. In addition, each client request and internal job performs database calls, access shared data, which may lead to collisions and deadlocks.
- Supportability: In a non-deterministic and distributed system as described above, it is very hard to reproduce and analyse internal failures. In such systems the logs are created on different components and produces gigabytes of logs, which mean investigating a failure through the logs, will cause a long analysis time. Moreover, it is almost impossible to reproduce a failure since usually there is no determined sequence of operations that one can do in order to reproduce the failure.
Architecture Description
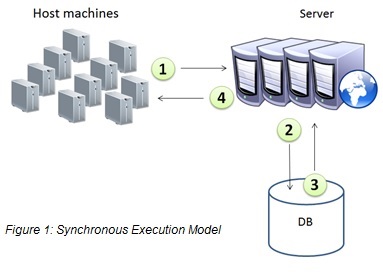
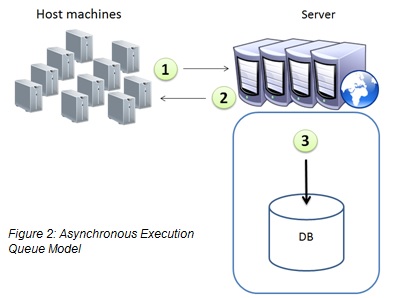
The architecture is a cluster-aware queue that aggregates tasks and handles them asynchronously (figure 2), as opposed to handling them synchronously (figure 1).
The queue is represented as a table in the database, and it has a worker responsible for consuming it. Each call from a host will result in a new task written to the queue in the database.
This framework centralizes the tasks into a single manager component, which provides structure and order in tasks execution.
Scalability: The worker thread captures the current snapshot of the queue and performs smart handling of tasks:
- Sort - tasks in queue should be sorted in order to optimize performance.
- Remove duplicate tasks - handles snapshots that can contain duplication since some tasks are driven by others.
- Consolidation – remove tasks that are consolidated by other tasks.
The algorithm is generic and done by predefined rules given in a fixed format.
The heavier the load is, the bigger the snapshot “smart handling” will handle. This is due to the fact that the worker thread will get less CPU time during heavy load, and in the meanwhile more tasks will be gathered.
A larger snapshot provides more material for the framework to handle, which will result in more efficient output. Moreover, since tasks are handled in a single worker thread, it reduces the load on the database,
breaking the correlation between number of calls from hosts and number of concurrent database calls. Such correlation is a bad practice since a system with such a high rate of concurrent database calls is not scalable.
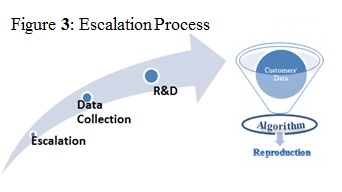
Supportability: R&D spend a lot of effort dealing with customer escalation. This framework makes it is easier to reproduce,
analyze and debug problems, which can significantly reduce the R&D time investment in escalations.
A task, for example, represents a command that should be executed. Tasks in the system are represented along with their order of arrival, the time they were handled and the amount of tasks handled on each snapshot. Once a customer has an issue,
it is possible to collect this data by exporting the tasks table from the database, with the information accumulated for the specific problematic scenario and import it on site for further R&D investigation.
Once the data is imported, a reproduction tool can be executed and reproduce the problematic scenario in development mode.
Queue based architecture can solve the supportability, scalability and concurrency issues in systems as described above.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




