|
It's probably a bandwidth thing, but we're working on long running processes today to stop these sorts of spurious errors.
cheers
Chris Maunder
|
|
|
|
|
I am attempting to get mesh working again.
2.5.4 running on Windows 10, and 2.5.1 Docker image running on Ubuntu 22.04.
I had thought I had read that when connecting to a Docker image, one needed to enter the host's hostname here, not the Docker hostname or ip address.
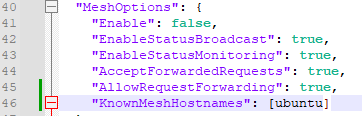
Now it seems that anything I enter in this variable causes the CodeProject AI server service to fail to start.
(I had had this issue previously, and didn't know what was causing it.)
When running the CodeProject.AI.Server.exe, I then receive this error:
'u' is an invalid start of a value
Stopping any orphaned Processes.
No Instance(s) Available.
No Instance(s) Available.
No Instance(s) Available.
No Instance(s) Available.
Error loading C:\Program Files\CodeProject\AI\Server\appsettings.json: 'u' is an invalid start of a value. Path: $ | LineNumber: 46 | BytePositionInLine: 27.
No runtime path provided
Infor ** System: Windows
Infor ** Operating System: Windows (Microsoft Windows 10.0.19045)
Infor ** CPUs: Intel(R) Core(TM) i5-7500 CPU @ 3.40GHz (Intel)
Infor ** 1 CPU x 4 cores. 4 logical processors (x64)
Infor ** GPU (Primary): Intel(R) HD Graphics 630 (1,024 MiB) (Intel Corporation)
Infor ** Driver: 31.0.101.2111
Infor ** System RAM: 16 GiB
Infor ** Platform: Windows
Infor ** BuildConfig: Release
Infor ** Execution Env: Native
Infor ** Runtime Env: Production
Infor ** .NET framework: .NET 7.0.5
Infor ** Default Python: 3.11
Infor ** App DataDir: C:\ProgramData\CodeProject\AI
Infor Video adapter info:
Infor Intel(R) HD Graphics 630:
Infor Driver Version 31.0.101.2111
Infor Video Processor Intel(R) HD Graphics Family
Infor *** STARTING CODEPROJECT.AI SERVER
Unable to start the server: Value cannot be null. (Parameter 'path').
Check that another instance is not running on the same port.
Press Enter to close.
I could have sworn that I had mesh functioning for about a week, with the hostname "Ubuntu" in the brackets for "KnownMeshHostnames".
And, you do not see the "service will not start" issue until you either restart the service, or reboot the machine. (Like back to DOS, early Windows with .ini files.)
I can cause this behavior at will, and resolve it by simply either entering anything, or leaving the variable (parameter) blank will return the CPAI server to normal operation.
This is obviously a typo. What is it expecting? Is it the blank line above "KnownMeshHostnames"?
Or does this not apply anymore?
(Removing that blank line has no effect.)
Firewalls on both machines are configured to allow port 32168 TCP and UDP send and receive.
I can ping the Ubuntu machine from the Windows machine with no problem.
PS The Ubuntu machine shows the Windows machine on the Mesh tab, but the Windows machine does not show the Ubuntu machine.
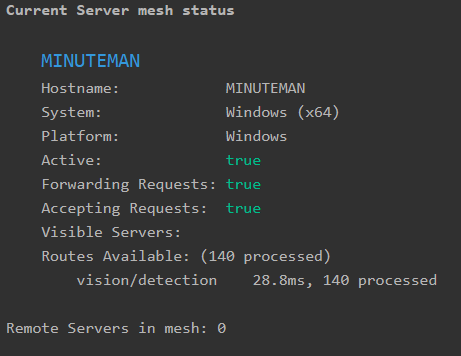

|
|
|
|
|
You need quotes around "ubuntu".
cheers
Chris Maunder
|
|
|
|
|
Damn. Passing an ASCII string. I'm getting away from this I guess.
But this is why I had the "service will not start" error 1067 issue, so I learned that.
Thanks for the proofreading!
|
|
|
|
|
Posting the screenshot of the JSON made it so much easier to help, so thanks.
cheers
Chris Maunder
|
|
|
|
|
Im noticing much quicker processing on my pi5 with coral hat. Was something changed or is this in my mind?
|
|
|
|
|
Depends on what you mean by ‘very fast’. There have been reports of what sounds like running the small model when a larger one is expected. We’re still trying to track down exactly what’s going on there.
If you have multi-TPU enabled, it’s been reworked to handle concurrency much better, so you should be able to throw a lot more at it, but the inference numbers themselves probably won’t go down all that much. Doubly so if you have two TPUs.
|
|
|
|
|
Depending on what device your on, part of the speed up is the correct loading of the Coral libraries. This wasn't happening in the previous build in some instances.
cheers
Chris Maunder
|
|
|
|
|
Unfortunately the Medium is worse than the old Medium, so maybe it’s not just the bad loading of libraries but comes down to worse/faster detection in newer versions?
|
|
|
|
|
Receive only nothing found on 5.net 1.9.3 and, 5 6.2 1.9.1 - positive for person on 8 1.3.1. Yes for nothing found in settings, yes for reinstall 5.net, no for .pt in 5.net (onnx), yes for .pt in 8. Blue iris 5.8.7.4. No cuda, no video card, yes for cpu graphics. Method of overall install, delete all code project everything, install 2.5.4, restart pc (win 10 pro), multiple BI restarts, multiple configs in camera settings of ipcam-general, ipcam combined and such etc. Was hoping to be able to get animal confirmations. in settings, yes for reinstall 5.net, no for .pt in 5.net (onnx), yes for .pt in 8. Blue iris 5.8.7.4. No cuda, no video card, yes for cpu graphics. Method of overall install, delete all code project everything, install 2.5.4, restart pc (win 10 pro), multiple BI restarts, multiple configs in camera settings of ipcam-general, ipcam combined and such etc. Was hoping to be able to get animal confirmations.
|
|
|
|
|
Not 100% of what you're saying here (pasting the contents of the System Info tab is best) but you did say "Was hoping to be able to get animal confirmations". Have you reviewed Sean's FAQ on custom models: FAQ: Blue Iris and CodeProject.AI Server[^]
cheers
Chris Maunder
|
|
|
|
|
Thank you for your reply, apologies for the confusion, was trying to anticipate questions (obviously a total fail), sorry about that. Yes to Sean's FAQ on custom models which worked originally, but as updates rolled in it stopped working. I figured if I just waited things would get easier, oops on that one.
In BI (blue iris), settings-AI-use custom models (currently ipcam-general), I have the understanding it self populates when restarting BI as a service, I seem to have no control over this input any longer. In BI-camera settings-alert-AI (artificial Intelligence)-Custom models, I have the understanding this needs to match BI use custom models (the currently ipcam-general). So when I do this in OD(object detection) yolov8, it works for people, when I do it in "OD" yolov5 3.1, (changing BI custom models to match) nothing works or nothing found. BI-camera settings-alert-AI "to confirm is person,cat,dog,rabbit,bird", to cancel Nothing found(semicolon0), Mark as vehicle is car,truck,bus,vehicle.
System info admin (me) not a techie old guy (but I try)
System info
Server version: 2.5.4
System: Windows
Operating System: Windows (Microsoft Windows 10.0.19045)
CPUs: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz (Intel)
1 CPU x 4 cores. 8 logical processors (x64)
GPU (Primary): Intel(R) HD Graphics 530 (1,024 MiB) (Intel Corporation)
Driver: 30.0.101.1692
System RAM: 16 GiB
Platform: Windows
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
.NET framework: .NET 7.0.16
Default Python:
Video adapter info:
Intel(R) HD Graphics 530:
Driver Version 30.0.101.1692
Video Processor Intel(R) HD Graphics Family
System GPU info:
GPU 3D Usage 0%
GPU RAM Usage 0
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
|
|
|
|
|
The simple answer to this one is that the YOLOv8 module doesn't (yet) have custom models. You'll need to use a YOLOv5 module for that.
Not a total fail on anticipating questions, but your clarification definitely helped.
cheers
Chris Maunder
|
|
|
|
|
My reading on both this site and ipcamtalk tells me I need yolo5, but I have yet to find a solution that gives me a positive notification (other than nothing found). When I set up "5", and walk around, I get the triggers but AI doesn't find anything, I'm pretty sure I still exist (though there are people who might question that). On 8 I get the person found (so I guess I do exist sometimes). I'm just missing or miss understanding how 5 needs to be set up to get positive results. The Sean thing worked ages ago but I have been unable to get the same results recently. Was hoping 2.5.4 was the answer, all solutions I have read/tried have yet to work. Thanks again for your patience and understanding. On a side note I see I get marked as possible spam, only asking because another site I set up a login for, also has my ip address listed as spam, any insight to either issue would be appreciated. Thank you always, especially for the work you and your friends are doing.
Figured it out, for what ever reason what stopped working months ago is now working again. Mainly "whats in BI settings" is not what needs to go into "camera settings". The original is valid again. Had to be something obvious, always is.
Just need to wait for it to tell me my BBQ is a toilet or a cat is a dog, rock is a deer? Some of the comedy from ipcamtalk. Thanks for everything.
|
|
|
|
|
I'm reaching out to share a perplexing issue I've encountered with the integration CPAI with my BI setup, hoping to find if anyone else has experienced something similar or could offer any insights. The problem first manifested around 01:45 am on 14/02/2024, and despite troubleshooting efforts, it recurred this morning, indicating a persistent underlying issue.
Initially, the system logs from 14th February showed an error related to CUDA, specifically mentioning "an illegal memory access was encountered". This issue caused a loop of errors until a system reboot was performed at 9:06 am.
Here is the exact log entry for reference:
2024-02-14 01:39:57: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-14 01:39:57: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-14 01:39:57: Response received (#reqid 85bde494-89d3-429d-a21b-c10b9430c5a8 for command custom)
2024-02-14 01:39:57: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 669, in forward
with dt[0]:
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 158, in __enter__
self.start = self.time()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
I upgraded yesterday from CPAI v2.5.1 to v2.5.4, hoping the update would resolve the issue which took place on the 14th. However, this morning, the same CUDA error reappeared, this time indicating "an illegal instruction was encountered". The error persisted until a reboot was done just after 9 am. Below is the log excerpt from today's occurrence:
2024-02-18 04:52:40: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-18 04:52:40: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid ad29496b-5caf-4d8b-b02f-7fcc6c7ab605) ['No objects found'] took 22ms
2024-02-18 04:52:40: Client request 'custom' in queue 'objectdetection_queue' (#reqid 7e1b52dd-b880-4c35-b7c6-0f076127faab)
2024-02-18 04:52:40: Request 'custom' dequeued from 'objectdetection_queue' (#reqid 7e1b52dd-b880-4c35-b7c6-0f076127faab)
2024-02-18 04:52:40: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-18 04:52:40: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-18 04:52:40: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid 7e1b52dd-b880-4c35-b7c6-0f076127faab)
2024-02-18 04:52:40: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 715, in forward
max_det=self.max_det) # NMS
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 920, in non_max_suppression
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 717, in forward
scale_boxes(shape1, y[i][:, :4], shape0[i])
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 162, in __exit__
self.dt = self.time() - self.start # delta-time
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal instruction was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
The repeating nature of this error is particularly concerning as it undermines the reliability of object detection capabilities, which are crucial for the functionality I rely on. It's disconcerting to see the system fail in such a manner, especially considering the otherwise commendable performance improvements in the AI aspects of the software.
Has anyone else encountered similar issues, particularly with CUDA errors causing system instability? Any advice on troubleshooting or resolving this would be immensely appreciated. I've also posted this on the Blue Iris forum to cast a wider net for potential solutions.
Thank you in advance for your time and assistance.
modified 18-Feb-24 15:36pm.
|
|
|
|
|
If you post the contents of what's in the System Info tab we can narrow things down a bit
cheers
Chris Maunder
|
|
|
|
|
Apologies for the oversight. I ought to have included the information which the troubleshooting guide advises to provide before reporting any bugs.
Here are the details from the system info tab:
Server version: 2.5.4
System: Windows
Operating System: Windows (Microsoft Windows 11 version 10.0.22631)
CPUs: Intel(R) Core(TM) i9-10850K CPU @ 3.60GHz (Intel)
1 CPU x 10 cores. 20 logical processors (x64)
GPU (Primary): NVIDIA GeForce GTX 1650 (4 GiB) (NVIDIA)
Driver: 522.30, CUDA: 11.8 (up to: 11.8), Compute: 7.5, cuDNN: 8.9
System RAM: 32 GiB
Platform: Windows
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
.NET framework: .NET 7.0.10
Default Python:
Video adapter info:
NVIDIA GeForce GTX 1650:
Driver Version 31.0.15.2230
Video Processor NVIDIA GeForce GTX 1650
Intel(R) UHD Graphics 630:
Driver Version 31.0.101.2115
Video Processor Intel(R) UHD Graphics Family
System GPU info:
GPU 3D Usage 5%
GPU RAM Usage 2.5 GiB
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
|
|
|
|
|

Log excerpt below:
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 705, in forward
y = self.model(x, augment=augment) # forward
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 515, in forward
y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 209, in forward
return self._forward_once(x, profile, visualize) # single-scale inference, train
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 121, in _forward_once
x = m(x) # run
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\Lib\site-packages\yolov5\models\yolo.py", line 59, in forward
x[i] = self.m[i](x[i]) # conv
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\conv.py", line 460, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: cuDNN error: CUDNN_STATUS_MAPPING_ERROR
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 705, in forward
y = self.model(x, augment=augment) # forward
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 162, in __exit__
self.dt = self.time() - self.start # delta-time
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Client request 'custom' in queue 'objectdetection_queue' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Request 'custom' dequeued from 'objectdetection_queue' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:28: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid b96054ed-380b-4c47-8920-07431cbb2086)
2024-02-20 13:21:28: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 669, in forward
with dt[0]:
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 158, in __enter__
self.start = self.time()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Client request 'custom' in queue 'objectdetection_queue' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Request 'custom' dequeued from 'objectdetection_queue' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): Retrieved objectdetection_queue command 'custom' in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): Detecting using ipcam-combined in Object Detection (YOLOv5 6.2)
2024-02-20 13:21:29: Response rec'd from Object Detection (YOLOv5 6.2) command 'custom' (#reqid bbea7af9-3909-467c-bd44-88b1d9553b32)
2024-02-20 13:21:29: Object Detection (YOLOv5 6.2): [RuntimeError] : Traceback (most recent call last):
File "C:\Program Files\CodeProject\AI\modules\ObjectDetectionYOLOv5-6.2\detect.py", line 141, in do_detection
det = detector(img, size=640)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\nn\modules\module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\models\common.py", line 669, in forward
with dt[0]:
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 158, in __enter__
self.start = self.time()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\yolov5\utils\general.py", line 167, in time
torch.cuda.synchronize()
File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python37\venv\lib\site-packages\torch\cuda\__init__.py", line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
in Object Detection (YOLOv5 6.2)
Instead of rebooting the entire system, I simply restarted the Yolo 5.6.2 service, and it began working again. Nevertheless, the reliability of the service is concerning, and I'm unsure of how to proceed. I even acquired a GTX 1650 specifically in improve inference, yet I find myself at a loss for solutions. Thus, I am posting here in the hope of discovering what might be causing this frustrating problem. Although it operates, it can unexpectedly stop working, as I've noted as this is pretty concerning.
|
|
|
|
|
In my above response, I outlined the recurring issue and shared log excerpts that pinpointed the onset of errors to 13:21:28 on the 20th of February, 2024. These errors persisted for several hours until they were detected and addressed by restarting the YOLOv5 6.2 service, which temporarily resolved the problem. Despite this workaround, concerns regarding the service's reliability remain.
I have since realised a crucial detail was omitted from my initial system configuration description. Specifically, I did not mention that I was utilising the integrated GPU (iGPU) alongside the dedicated Nvidia GTX 1650 GPU. My intention was to optimise the system's performance for inference tasks, allocating the iGPU for display purposes and dedicating the GTX 1650 exclusively to computational AI processing. This dual-GPU setup, I presumed, would offer the best of both worlds: efficient display management and powerful, dedicated AI processing capabilities.
However, the persistent issue and the specific nature of the error messages suggest that this configuration might be contributing to the problem. The error logs indicating "an illegal memory access was encountered" and "CUDNN_STATUS_MAPPING_ERROR" hint at potential complications arising from this dual-GPU setup.
In light of this, I have taken steps to modify my system's configuration. I entered the BIOS settings and disabled iGPU support, making the GTX 1650 the sole graphics card in use. It is my hope that this change might eliminate the aforementioned errors and enhance the system's stability and performance.
I am sharing this update to provide a complete picture of my system's setup and the measures I've taken to address the issue. While it is possible that using both the iGPU and the Nvidia GTX 1650 in tandem might have been overly ambitious or complicated the system's configuration, identifying the exact cause of the problem has proven challenging.
I am eager to hear your thoughts or suggestions on this matter. Could the dual-GPU setup have been a contributing factor to the issues experienced? Any insights or recommendations on how to proceed would be greatly appreciated as I strive to achieve the optimal setup for reliable and efficient inference performance.
Thank you for your attention and assistance.
|
|
|
|
|
That's good thinking but I don't think that will make any difference. The YOLO6.2 code uses PyTorch which will use either 'cpu' or 'cuda' as the device on your setup, meaning plain old CPU or your CUDA enabled GPU. It won't even spare a sideways glance at your iGPU.
I noticed your card has 4GB RAM. I'm just wondering if that is the issue here: running out of headroom.
Can you try using a smaller model size, or if you actually would like to use the iGPU, you could switch to the .NET Object detection module which uses DirectML
cheers
Chris Maunder
|
|
|
|
|
Dear Chris,
Thank you for your insights. I understand your point about PyTorch leveraging either 'cpu' or 'cuda' for computations, which essentially rules out the use of the IGPU for display output only. I initially opted for the Nvidia 1650 because I was aware that using the iGPU for AI tasks could significantly burden the CPU, which is not ideal.
Regarding the 4GB RAM on the Nvidia card, it's a common specification across similar models, and it appears to be the card of choice for many within the CodeProject AI community. Most setups I've researched seem to employ a medium model, which led me to believe that this configuration should be sufficient. The idea that CPAI might exhaust memory to the point of failure is somewhat surprising to me. Surely, there must be a threshold of efficiency and performance that allows for effective operation without constant failures due to memory limitations?
For the time being, I have disabled onboard GPU support in the BIOS and am exclusively using the Nvidia 1650. I plan to monitor how this configuration performs over the next few days. This should hopefully provide some clarity on whether the 4GB RAM is indeed the bottleneck or if there might be other underlying issues at play.
I am keen to hear your thoughts on whether CPAI inherently demands more memory than what the Nvidia 1650 can provide, or if there are adjustments and optimizations that could mitigate these memory consumption issues.
Best regards,
|
|
|
|
|
I have a NVIDIA 1030 and it's pretty basic but still does OK. The trick is definitely to balance accuracy and model size, so I'd definitely recommend trying a smaller model size (the dashboard allows you to do this via the gear icons on each module). Also try to minimise the number of modules you have that are using the GPU.
cheers
Chris Maunder
|
|
|
|
|
Upon waking, I found the system had failed again, prompting me to now switch to a smaller model as you have suggested.
My current setup includes only the Object Detection (YOLOv5 .NET), Object Detection (YOLOv5 3.1), and Face Processing modules, with the .NET and Face modules disabled. Is disabling these sufficient, or should they be uninstalled?
Another critical question is whether the number of cameras using CPAI affects performance. I'm using three cameras with CPAI, considering whether to limit the system to just the most crucial camera if necessary, though ideally, there shouldn't be a restriction on the number of cameras I would have presumed but I thought I'd ask.
Thanks again
|
|
|
|
|
I'm reaching out again to share an update and seek further assistance with the persistent issues I've been experiencing with the CPAI setup.
Following your suggestion, I've adjusted my setup to utilise a smaller model size (small not tiny), hoping this would alleviate the CUDA errors and improve system stability. Unfortunately, the issue persists, with CPAI crashing recurrently within a 10-12 hour timeframe. This pattern has become evident through manual logging, as CPAI does not retain log files adequately. Since November 2023, I've been actively seeking solutions on the Blue Iris forum to reduce false flags, which led me to integrate CPAI into my system. However, the stability issues have become a significant concern.
I've found it necessary to circumvent this problem is to restart the CPAI service at least twice daily to maintain operation outside the 10-12 hour crash window, a workaround that is far from ideal.
Conversations with a moderator on the Blue Iris Forum revealed that their system, running a medium-sized model, has remained stable since 31 January, who runs the same GPU 1650 4GB Ram, utilising the same drivers etc. starkly contrasting with my experience where the system fails to last more than 10 hours.
Given these circumstances, I'm at a loss for how to proceed. The recurrent failures despite model size adjustments, and the apparent anomaly in system behaviour compared to others in the community, suggest there may be an underlying issue not yet identified.
In our previous discussions, you mentioned the possibility of switching to the .NET Object detection module which uses DirectML as an alternative. However, won't this switch mess up inference times ?
Could you please advise if there's anything more I can do to diagnose and resolve these stability issues? Is there a possibility that the driver versions I'm using could be contributing to the problem, or is there any additional information I can provide that might offer further insights? The lines of code provided in the error messages, particularly those related to CUDA errors and illegal memory access, have not offered a clear path to resolution.
This situation is particularly frustrating, given the time and effort invested in finding a viable solution. The necessity of frequent service restarts is untenable, and I'm eager to find a more permanent fix to ensure reliable system operation.
Any assistance or insights you can offer would be greatly appreciated. Thank you for your time!
Kind regards
ZK
|
|
|
|
|
Just an update . Version 2.5.6 installed and no more errors with CUDA.. Very odd but great nonetheless!
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





