A Brief History of Map Reduction
Map and Reduce functions can be traced all the way back to functional programming languages such as Haskell and its Polymorphic Map function known as fmap. Even before fmap, there was the Haskell map command used primarily for processing against lists. I am sure there are experts out there on the very long history of MapReduce who could provide all sorts of interesting information on that topic and the influences of both Map and Reduce functions in programming. However, the purpose of this article is to discuss effective strategies for performing highly parallel map reductions in the C# programming language. There are many large-scale packages out there for performing map reductions of just about any size. Google’s MapReduce and Apache’s Hadoop platforms are two of the most well known. However, there are many competitors in this space. Here are just a few references. MapReduce concepts are claimed to be around 25 years old by some. Strangely enough, the patent for MapReduce is currently held by Google and was only issued during 2004. Google says that MapReduce was developed for “processing large amounts of raw data, for example, crawled documents or web request logs”.
Understanding Map Reduction
In more complex forms, map reduction jobs are broken into individual, independent units of work and spread across many servers, typically commodity hardware units, in order to transform a very large and complicated processing task into something that is much less complicated and easily managed by many computers connected together in a cluster. In layman’s terms, when the task at hand is too big for one person, then a crew needs to be called in to complete the work. Typically, a map reduction “crew” would consist of one or more multi-processor nodes (computers) and some type of master node or program that manages the effort of dividing up the work between nodes (mapping) and the aggregation of the final results across all the worker nodes (reduction). The master node or program could be considered the map reduction crew’s foreman. In actuality, this explanation is an over-simplification of most large map reduction systems. In these larger systems, many additional indexing, I/O, and other data management layers could be required depending on individual project requirements. However, the benefits of map reduction can also be realized on a single multi-processor computer for smaller projects.
The primary benefits of any map reduction system come from dividing up work across many processors and keeping as much data in memory as possible during processing. Elimination of I/O (reading data from and writing data to disk) represents the greatest opportunity for performance gains in most typical systems. Commodity hardware machines each provide additional processors and memory for data processing when they are used together in a map reduction cluster. When a cluster is deployed however, additional programming complexity is introduced. Input data must be divided up (mapped) across the cluster’s nodes (computers) in an equal manner that still produces accurate results and easily lends itself to the aggregation of the final results (reduction). The mapping of input data to specific cluster nodes is in addition to the mapping of individual units of input data work to individual processors within a single node. Reduction across multiple cluster nodes also requires additional programming complexity. In all map reduction systems, some form of parallel processing must be deployed when multiple processors are used. Since parallel processing is always involved during map reduction, thread safety is a primary concern for any system. Input data must be divided up into individual independent units of work that can be processed by any worker thread at any time during the various stages of both mapping and reduction. Sometimes this requires substantial thought during the design stages since the input data is not necessarily processed in a linear fashion. When processing text data for instance, the last sentence of a document could be processed before the first sentence of a document since multiple worker threads simultaneously work on all parts of the input data.
The following figure illustrates a map reduction process running on a single multi-processor computer. During this process, multiple worker threads are simultaneously mapped to various portions of the input data placing the mapping results into a centralized location for further downstream processing by other reduction worker threads. Since this process occurs on a single machine, mapping is less complex because the input data is only divided between worker threads and processors that all reside on the same computer and typically within the same data store.

When multiple computers are used in a map reduction cluster, additional complexity is introduced into the process. Input data must be divided between each node (computer) within the cluster by a master node or program during processing. In addition, reduction results are typically divided across nodes and indexed in some fashion so mapping results can quickly be routed to the correct reduction node during processing. The need for clustering typically occurs when input data, mapping results, reduction results, or all three are too large to fit into the memory of a single computer. Once any part of the map reduction process requires I/O (reading data from and writing data to disk), a huge performance hit occurs. It is very important to stress that this performance hit is exponential and deadly. If you are still skeptical, please stop reading and take a quick lesson from the famous Admiral Grace Hopper here. Obviously, some form of I/O is required to permanently save results from any program. In a typical map reduction system however, I/O should be minimized or totally removed from all mapping and reduction processing and used only to persist or save the final results to disk when needed.
The following figure illustrates a map reduction cluster running on four machines. In this scenario, one master node is used to divide up (map) input data between three data processing nodes for eventual reduction. One common challenge when designing clusters is that not all of the reduction data can reside in memory on one physical machine. In an example map reduction system that processes text data as input and counts unique words, all words beginning with A-I might be stored in node 1, J-R in node 2, and S-Z in node 3. This means that additional routing logic must be used to get each word to the correct node for a final reduction based on each word’s first letter.
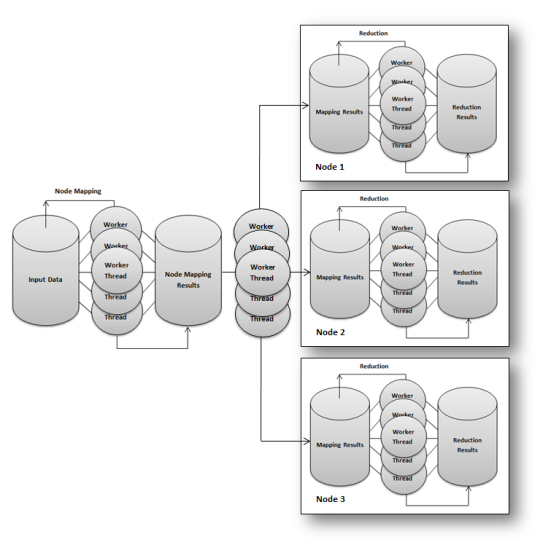
When reduction or mapping results are located on multiple clustered machines, additional programming logic must be added to access and aggregate results from each machine as needed. In addition, units of work must be allocated (mapped) to these machines in a manner that does not impact the final results. During the identification of phrases for instance, one sentence should not be split across multiple nodes since this could causes phrases to be split across nodes and subsequently missed during phrase identification as a result.
Map reduction systems can range in size from one computer to literally thousands of clustered computers in some enterprise level processes. The C# programming language provides a suite of thread-safe objects that can easily and quickly be used to create map reduction style programs. The following sections describe some of these objects and show examples of how to implement robust parallel map reduction processes using them.
Understanding Map Reduction Using C#
The C# programming language provides many features and classes that can be used to successfully perform map reduction processing as described in the sections above. In fact, certain forms of parallel map reduction in C# can be performed by individuals having a minimal knowledge of thread pools or hardware specific thread management practices. Other lower level tools however, require a great knowledge of both. Regardless of the tools chosen, great care must be taken to avoid race conditions when parallel programs are deployed within a map reduction system. This means that the designer must be very familiar with best demonstrated practices for both locking and multi-threaded programming when creating the portions of mapping and reduction programs that will be executed in parallel. For those who need assistance in this area, a detailed article on threading in C# can be located here.
One of the most important things to remember is that just because a particular C# object is considered “thread safe”, the commands used to calculate a value that is passed to the “thread safe” object or the commands passed within a delegate to the “thread safe” object are not necessarily “thread safe” themselves. IF a particular variable’s scope extends outside the critical section of parallel execution, then some form of locking strategy must be deployed during updates to avoid race conditions. One of the easiest ways to test for race conditions or threading errors in a map reduction program is to simply execute the program using the same set of input data multiple times. Typically, the programs results will vary when a race condition or threading error is present. However, the error might not present itself after only a few executions. It is important to exhaustively test the program using many different sets of test data as input, and then execute the program many times against each input data set checking for output data variations each time.
The specific C# classes described later in this document do not represent the only alternatives for performing parallel map reductions in the language. The selected classes merely represent a few of the viable techniques worth consideration. For instance, one available approach that is not covered in this document is PLINQ which is C#’s parallel implementation of LINQ to Objects. Numerous other C# tools are available as well. It is important to mention that the map reduction patterns described above are sometimes referred to / very similar to what is known as producer / consumer pipelines. Many great articles can be located on the internet when producer / consumer pipelines and C# are used together as search terms.
The Map Reduction Nuts and Bolts
Using the pattern described earlier, several basic C# components can be repeatedly used (and sometimes extended) to create a map reduction system of virtually any size. The following high level C# components and classes will be used as the “nuts and bolts” of this particular system:
- Parallel.For and Parallel.ForEach – These two members of the System.Threading.Tasks namespace can be used to quickly create mapping functions that execute in parallel. The commands executed within these “
For” blocks must be thread safe. Parallel mapping functions can be used to break apart input data into mapping results that are placed in a Blocking Collection for further downstream processing. - Blocking Collections – Blocking Collections are members of the System.Collections.Concurrent namespace and provide a centralized, thread safe location for multiple threads to add and remove objects during processing. These collections can be implemented using concurrent bag (not ordered), stack (LIFO), or queue (FIFO) collections. Thread safe versions of each collection are provided within the System.Collections.Concurrent namespace. Once the Blocking Collection has been wrapped around the appropriate bag, stack, or queue, it will manage timing differences between various producers and consumers using the collection. When the collection is empty, it can block until new items are added or stop processing once all items have been processed and the collection is marked as complete.
- Concurrent Dictionary – The thread safe Concurrent Dictionary will act as a key-value pair repository for the final reduction results in our process. Although a database could be used for this part of the process, the Concurrent Dictionary is an ideal reduction repository candidate for several basic reasons that are explained in detail within the reduction section and examples below. This dictionary is also a member of the System.Collections.Concurrent namespace.
Parallel Mapping Using C#
One of the easiest ways to implement a parallel map function in C# is by using the Parallel class. Specifically Parallel.For or Parallel.ForEach can be used to quickly map (in parallel) independent units of work into a centralized, thread-safe collection (we will get to thread-safe collections in a second) for further downstream processing. In addition, the class can perform parallel mappings with no lower level thread management programming required. The Parallel class is hardware intelligent and scales threads based on the current platform it is executing on. However, it also has the MaxDegreeOfParallelism option for those who want more control over how many threads a particular Parallel class process is using. The primary purpose of the map function is to break apart input data producing one or more key-value pairs that require reduction processing by other downstream worker threads. While mapping worker threads are producing these key-value pairs as output, reduction worker threads are simultaneously consuming (reducing) them. Depending on the size of the map reduction process, other intermediary processes such as a partitioning process might occur between a mapping and its final reduction.
Yield Return Blocks
In a C# example application that counts unique words from large amounts of input text, one or more stages of mapping could be used to produce the final mapping key-value pair data output. In order for both mapping and reduction worker threads to work in tandem, all phases of the mapping process must be executed asynchronously. This can be accomplished by using either background threads, some form of Yield Return processing, or both.
The following code demonstrates the use of Yield Return processing to break up input text into blocks of 250 characters or less using the space character as a word delimiter:

As each 250 character (or less) block of text is identified, the “yield return” command causes the process to “yield” and immediately return the identified text block to the calling process. Under normal circumstances, all identified blocks of text would be returned at one time when the entire process was completed. This would also mean that other downstream worker threads could not begin work on mapping the blocks of text into individual words until all text block identification was complete. The delay would slow down the entire process greatly. A yield return method for producing text blocks is not necessarily required for counting unique words in a map reduction system. However, this code will be used to demonstrate how yield return can be used and subsequently called using Parallel.ForEach to complete the mapping of text to individual words.
Blocking Collections
When all stages of mapping are completed, the final results are added to a mapping results Blocking Collection. Using our C# example application that counts unique words from large amounts of input text, a mapping results Blocking Collection is created called “wordChunks”. This particular Blocking Collection uses a ConcurrentBag as its base collection. Since words are added to and removed from the ConcurrentBag in no particular order, using a “bag” yields performance gains over a “stack” or “queue” which must internally keep track of processing order. The following code shows how the “wordChunks” Blocking Collection is created:
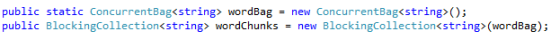
Technically, a mapping function’s output should be a key-value pair. The key-value pair typically contains some form of key and associated numeric value that are both used during the reduction process. In many cases, the key will only be contained one time within the final reduction results. The values for each duplicate key encountered during mapping will be “reduced” by either summation or another mathematical calculation that results in one final reduction number value that is representative of the single key contained in the final key-value pair reduction results. In our example word counting map reduction, a key-value pair is not even required for the mapping stage. The wordChunks bag can contain any number of words (given your current memory constraint). These words can also be duplicates. Since we are only counting the occurrence of words, each word in our bag is considered to have a default frequency of 1. However, the ConcurrentBag could have just as easily been created as a collection of key-value pairs (ConcurrentBag<KeyValuePair<string,int>>), if needed.
Parallel.ForEach Processing
The next program demonstrates a Parallel.ForEach mapping function using the Yield Return method created before. This process uses multiple worker threads to identify and clean words from the blocks of input text provided by the Yield Return method. The Parallel.ForEach mapping process begins as soon as the first block of text is identified since Yield Return is being used.

The program above uses Parallel.ForEach to call the text block production program “produceWordBlocks”. This program immediately yield returns blocks of text less than 250 characters in length and delimited by spaces as they are identified. Parallel.ForEach worker threads simultaneously process these text blocks identifying individual words which are also delimited by spaces. The program also removes any whitespace, punctuation, or control characters located within the words. Obviously, this is an example program and many other character filtering or inclusion enhancements could made depending on your particular requirements. In an alternative implementation, the Yield Return method could be removed entirely and its functionality included into a single Parallel.ForEach mapping program. This may or may not produce better performance results depending on your code, the input data, and the requirements of your system.
Once all individual words have been identified from all word blocks, the wordChunks Blocking Collection is notified that no more words will be added to the collection. This notification is very important for any downstream worker threads that are simultaneously reducing / removing words from the collection. If the Blocking Collection becomes empty during processing, collection consumers will continue to “block” or “wait” until either the CompleteAdding() method is called or additional items are added into the collection. The Blocking Collection is able to successfully manage differences in the object production and consumption speeds of various worker threads using this approach. In addition, a Blocking Collection Bounding Capacity can be added to ensure that no more than a maximum number of objects can be added to the collection at any given time.
Parallel Reduction Using C#
The process of parallel reduction is very similar to mapping with regards to the use of Parallel.ForEach to facilitate its process in our example application. Where reduction differs however, is in its use of one or more data storage components that provide very fast access to a particular set of reduction key-value pairs. When all data storage components are combined, the reduction key-value pairs eventually become the final output for map reduction once all input data has been processed. In a system where multiple map reduction computers are used together in a map reduction cluster, multiple data storage components could be used to store a very large number of key-value pairs across several computers. In the example word counting map reduction process, the reduction key-value pairs consist of a unique list of words which act as keys for the reduction key-value pairs. Each word key contains a value that represents the total frequency of occurrences for that particular word within the input text. The final result becomes a mapping of all words contained in the input data to a reduced list of unique words and the frequency that each unique word occurs within the input data.
The Concurrent Dictionary
The C# ConcurrentDictionary is basically a thread safe hash table that is well suited for acting as the data store component within the example application. The ConcurrentDictionary holds key-value pairs in memory until there is either no room left in memory or the dictionary already contains the maximum number of elements. Since the ConcurrentDictionary takes a 32-bit hash of each key, the maximum number of elements is the same as the Int32.MaxValue or 2,147,483,647. Most computers and processes will run out of memory prior to triggering the ConcurrentDictionary’s overflow exception due to exceeding the maximum number of elements. In situations where very large amounts of data are being map reduced, the map reduction data components (in this case Concurrent Dictionaries) can be sharded across several computers within a cluster. However, sharding requires a slightly more complex map reduction process since key partitioning logic must be developed to manage the associated sharding challenges such as what nodes(computers) will contain what keys, node load balancing, node additions, node removals, and node failures.
It is obvious that some readers may be asking why not use a database at this point, and this is a very valid question. The short answer is that most any data management solution could be used. Databases, NoSQL databases, In-memory databases, or some form of key-value datastore could be implemented. The most important thing to consider however, is that most relational databases will rely heavily on I/O to complete the work. Any form of I/O during map reduction processing will also most likely defeat the purpose of map reduction altogether. So whatever data management solution is chosen, just make sure that your data is being stored in memory. Even most relational databases now have some form of in-memory tables and clustering abilities.
Parallel.ForEach Reduction Processing
During reduction processing, Parallel.ForEach is used once again to create multiple worker threads that simultaneously consume mapping results as they are being created and added to the “wordChunks” Blocking Collection. Worker threads reduce all mapping results in the example application by looking up each mapped word within the reduction data store component (one or more ConcurrentDictionaries in this case). If a word already exists in the data store, then the mapping word is reduced by incrementing the existing reduction word’s key-value pair value by 1. Otherwise, the mapping word is reduced by creating a new key-value pair entry in the reduction data store with a starting value of 1. The following code demonstrates how this process works:
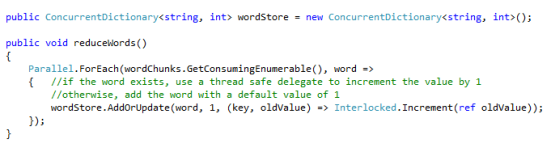
A ConcurrentDictionary was created to hold our final reduction processing results. Furthermore, the AddOrUpdate() method was taken advantage of during Parallel.ForEach processing. It is important to mention once again that delegates provided to a thread safe object are not necessarily thread safe themselves. In this case, the AddOrUpdate method accepts a delegate to provide update commands to execute when a key is a present in the wordStore dictionary. To ensure that the update is performed in a thread safe manner, Interlocked.Increment is used to increment existing values by 1 as an atomic operation each time they are encountered. The Parallel.ForEach process executes against the wordChunks Blocking Collection removing mapping results (words) from the collection until all words have been processed. The Blocking Collection will also cause to the Parallel.ForEach reduction process to “block” or wait for additional words when the collection becomes empty and the CompleteAdding() method has not yet been called by the producer (the mapWords method in our example program). Using the Blocking Collection’s GetConsumingEnumerable() method in the Parallel.ForEach loop is one way to trigger the blocking behavior.
The C# Map Reduction Summary
The previous figure of a map reduction process running on a single multi-processor computer can now be updated to reflect the C# objects and classes discussed in our example application. Using only a few key C# components, parallel map reduction can be performed with minimal effort when compared to creating parallel map reduction processes in other languages. The figure below represents a map reduction process written in C# and running on a single multi-processor computer:
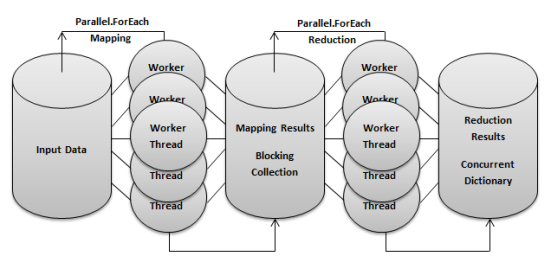
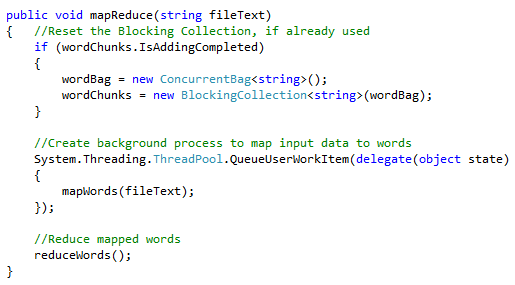
Once all components of the map reduction process have been created, a small mapReduce method is written to bring the entire process altogether. One of the most important parts of the mapReduce method is to create a background process for execution of the mapping function. While the mapping function populates the Blocking Collection with mapping results in the background, the reduction function simultaneously removes / reduces the mapping results into the reduction data store. Since all of this processing occurs in memory, the mapReduce method is extremely fast. The following mapReduce program ties together the entire map reduction process for our example application:
Printing the results of your map reduction is also as simple as printing the contents of your wordStore dictionary:

Conclusion
Map reduction processing provides an innovative approach to the rapid consumption of very large and complex data processing tasks. The C# language is also very well suited for map reduction processing. This type of processing is described by some in the C# community as a more complex form of producer / consumer pipelines. Typically, the largest potential constraint for any map reduction system is I/O. During map reduction processing, I/O should be avoided at all costs and used only for saving final map reduction results, if possible. When the processes described in this document are combined with data store sharding and map reduction partitioning processes, data processing tasks of almost any size can be accommodated. If you actually read this far, I’m impressed. Thank you!
The code examples from this article can be located here.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






