Introduction
As I mentioned in Part 1[^], I have been working on a web project with many pages done up to look like an encyclopedia. Part of generating that look is the use of references: superscript links within the text that point to a list of footnotes at the bottom of the page, which in turn have links back to where the reader had been. If you have ever used the Wikipedia, you know what I mean. Trying to manually manage references in a developing page would have been nightmare, which is why I started looking for a way to generate them automatically.
References are inserted into Wikipedia using two pseudo-tags: <ref> for the reference itself, and <references /> to place the list of references. The inner HTML of <ref> becomes the text of the reference. An optional name attribute allows an editor to reuse the reference later on, without having to copy it all out again. Reusing a reference also means that the reference's entry in the full list has multiple back-links, one for each time the reference is used. This was exactly what I wanted.
This article covers how to implement this kind of filter. If you are looking for information about Response.Filter, Part 1 has some material that you might find useful.
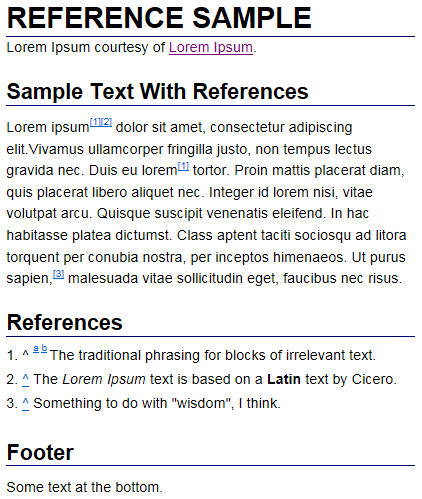
Dealing with the HTML
Because my needs were simple, I implemented a basic subset of the Wikipedia <ref> tag's functionality. In its most basic form, the tag is "anonymous" and useable only once:
<ref>This is an anonymous tag.</ref>
If you look at the image above, references 2 and 3 are both anonymous. If you wanted to repeat the text, you would need to add another tag, which would have its own index number and its own entry in the reference list.
If you want to reuse a reference, use the name attribute. The name needs to be unique and parsable by XML. A named reference would look like this:
<ref name="RefName">This is a named tag.</ref>
In the sample image, reference 1 is named. Notice that its entry in the references list has two back-links, a and b, which will return the viewer to the first or second use of the named reference.
The text inside the first instance of a named reference will be the text for all subsequent uses. This means you can shorten a reused tag to be self-closing:
<ref name="RefName" />
To place the list of references that gets generated by the filter, use the pseudo-tag <references />. If this tag is missing, the filter will skip processing the page and move to the next filter in the chain. Keep in mind that the filter does not support multiple uses of <references />, although with a little bit of work it would be possible.
Also, note that the tags are case-insensitive, so <REF name="rEFnAME" /> is functionally identical to <ref name="RefName" />, and <RefERencES /> will display the list of references just as well as <references />.
One thing to remember is that these are pseudo-tags, meaning that they are NOT part of the X/HTML standard. They will be replaced by the time everything is rendered, and should not cause any problems when validating the finished page, but they will generate warnings if you are using Visual Studio or some other parser during development. If this really bothers you, you can rewrite the filter to use square brackets or some other delimiter; [ref name="RefName" /] will work fine with some adjustment. The advantage to using X/HTML-like tags is that you can use the Framework's XML handler objects and, if anything goes wrong, the browser will automatically hide any pseudo-tags that manage to slip through.
Auxiliary Class ReferenceClass
This helper class holds the information about a single reference.
Private Class ReferenceClass
Private pBackLinks As List(Of String)
Private pInnerXml As String
Public ReadOnly Property BackLinks() As List(Of String)
Get
If pBackLinks Is Nothing Then pBackLinks = New List(Of String)
Return pBackLinks
End Get
End Property
Public ReadOnly Property InnerXml() As String
Get
Return pInnerXml
End Get
End Property
Public Sub New(ByVal InnerXml As String)
pBackLinks = New List(Of String)
pInnerXml = InnerXml
End Sub
End Class
Additional Methods
In addition to the StringContains function used in Part 1, the filter has two other helper methods, one that extracts the value of an attribute, and one that retrieves the inner XML of the element.
Private Function GetAttributeValue(ByVal Elem As XElement, _
ByVal AttributeName As String) As String
For Each a As XAttribute In Elem.Attributes
If String.Compare(a.Name.ToString, AttributeName, ignoreCase:=True) = 0 Then
Return a.Value
End If
Next
Return ""
End Function
Private Function GetInnerXml(ByVal Elem As XElement) As String
Dim Reader As XmlReader = Elem.CreateReader
Reader.MoveToContent()
Return Reader.ReadInnerXml
End Function
The References
After the filter does its work, all of the <ref> tags will look something like this:
<sup id="REF_1"><a href="#reference_Lorem">[1]</a></sup>
The pseudo-tag is replaced with a superscript tag having a unique id. The tag contains a link to the entry in the reference list, which will be wherever you put the <references /> tag. The index number is generated automatically, in the order the references appear in the text; reusing a named reference will reuse the original reference's index. This is the primary advantage to using this kind of filter: you can rearrange the text, move references around, etc., and everything will still be correctly indexed and referenced without any additional work on your part.
The reference list is implemented as an unordered list to control the index number that appears, rather than letting the browser decide. In theory, it should not matter, but explicit control gives a bit more flexibility if you want to add new features in the future. It also has the advantage of putting the reference index in the page source, which can make debugging things a bit easier.
<ul class="References">
<li>1. ^ <sup><a href="#REF_1">a</a> <a href="#REF_3">b</a></sup>
<a id="reference_Lorem"></a>The traditional phrasing for blocks of irrelevant text.
</li>
<li>2. <a href="#REF_2">^</a> <a id="reference_REF_2"></a>
The <em>Lorem Ipsum</em> text is based on a <strong>Latin</strong> text by Cicero.
</li>
<li>3. <a href="#REF_4">^</a> <a id="reference_REF_4"></a>Something to do with
"wisdom", I think.</li>
</ul>
The destination anchor -- the empty <a> tag -- has an id derived from the reference's name, either the one given in the name attribute or the one that was automatically generated. With single entry references, like 2 and 3, the back-link is placed on the carat; this will be the case whether the reference is anonymous or is named and used only once. If a named references is reused, the back-links are letters of the alphabet, with each letter linking back to a different use of the reference. Right now, the filter is not designed to have more than 26 back-links, but that can be changed if needed.
Overrides Sub Write
Now we can look at what the filter actually does. The first thing to do is make sure that the <references /> tag is present. If it is not, then why waste cycles creating a list that will not be rendered?
Public Overrides Sub Write(ByVal buffer() As Byte, _
ByVal offset As Integer, ByVal count As Integer)
Dim BufferStr As String = UTF8Encoding.UTF8.GetString(buffer)
HTML.Append(BufferStr)
If EOP.IsMatch(BufferStr) Then
Dim PageContent As String = HTML.ToString
If StringContains(PageContent, "<references") Then
Dim i As Integer = 0
Dim FrontStr As String = ""
Dim Token As StringBuilder = Nothing
Dim name As String = ""
Dim value As String = ""
Dim x As Integer = 0
Dim RefCount As Integer = 0
Dim RefStr As StringBuilder = Nothing
Dim References As New Dictionary(Of String, ReferenceClass) _
(StringComparer.CurrentCultureIgnoreCase)
End If
Output.Write(UTF8Encoding.UTF8.GetBytes(PageContent), offset, _
UTF8Encoding.UTF8.GetByteCount(PageContent))
End If
End Sub
The class constructor made a note of the old Response.Filter, using a System.IO.Stream object named Output. We assume that the page is encoded using UTF8 (if not, substitute the correct encoding method), and accumulate the page into a StringBuilder object named HTML. EOP is a Regex set to do a case-insensitive check for </html>; once it is found, we have the full page and can process it. After that, the buffer is converted back into an array of bytes and passed on to the next filter in the chain via Output. The Dictionary object, which will hold the references, is initialized to use a case-insensitive comparer.
The first thing to do is scan the page for occurrences of <ref, excluding the situation where that is actually <references. After getting the entire tag and making sure it is valid, it gets converted into a XElement and the name (if any) and value are extracted. If there is no name attribute, one is generated; then the reference is added to the dictionary if it's not already there, using its name as the dictionary key. The replacement <sup> link is generated and inserted, and the reference's id is noted so we can create the back-link later. Then we splice everything together and find the next reference, looping until none are found.
i = PageContent.IndexOf("<ref", StringComparison.CurrentCultureIgnoreCase)
Do While i > 0
FrontStr = PageContent.Substring(0, i)
Token = New StringBuilder
Token.Append(PageContent.Substring(i, 4))
i += 3
Do While Not Token.ToString.EndsWith(">")
i += 1
Token.Append(PageContent(i))
Loop
If Not Token.ToString.EndsWith("/>") Then
Do While Not StringContains(Token.ToString, "</ref>")
i += 1
Token.Append(PageContent(i))
Loop
End If
i += 1
If StringContains(Token.ToString, "<references") Then
i = PageContent.IndexOf("<ref", i, StringComparison.CurrentCultureIgnoreCase)
Continue Do
End If
RefCount += 1
Try
Dim Ref As XElement = XElement.Parse(Token.ToString.Trim)
name = GetAttributeValue(Ref, "name").Trim
value = GetInnerXml(Ref)
Catch ex As Exception
End Try
If name = "" Then name = String.Format("REF_{0}", RefCount)
If Not References.Keys.Contains(name) Then
References.Add(name, New ReferenceClass(value))
End If
RefStr = New StringBuilder
For x = 0 To References.Keys.Count - 1
If String.Compare(References.Keys(x), name, ignoreCase:=True) = 0 Then Exit For
Next
RefStr.AppendFormat("<sup id=""REF_{0}"">", RefCount)
RefStr.AppendFormat("<a href=""#reference_{0}"">[{1}]</a>", _
References.Keys(x).Replace(" ", "_"), x + 1)
RefStr.Append("</sup>")
References.Values(x).BackLinks.Add(String.Format("REF_{0}", RefCount))
PageContent= FrontStr + RefStr.ToString + PageContent.Substring(i)
i = PageContent.IndexOf("<ref", StringComparison.CurrentCultureIgnoreCase)
Loop
It may not be obvious from looking at the code, but the variable RefCount keeps an absolute count of the references, which guarantees that a unique name can be generated for each one if necessary. The number used to render the reference is the index of References, held in the variable x.
Now, all of the <ref> tags have been replaced with a linked superscript. The next thing to do is to generate the reference list. This is done by looping through the dictionary and adding one list item for every entry. All references will have at least one back-link; if it has more than one, then the links are applied to letters rather than the carat. Note that the list is given a class of References: this will make it easy to style the list to your liking.
RefStr = New StringBuilder
RefStr.AppendLine("<ul class=""References"">")
x = 0
For Each kvp As KeyValuePair(Of String, ReferenceClass) In References
RefStr.Append("<li>")
RefStr.AppendFormat("{0}. ", x + 1)
If kvp.Value.BackLinks.Count = 1 Then
RefStr.AppendFormat("<a href=""#{0}"">^</a> ", kvp.Value.BackLinks(0))
ElseIf kvp.Value.BackLinks.Count > 0 Then
RefStr.Append("^ <sup>")
For i = 0 To kvp.Value.BackLinks.Count - 1
RefStr.AppendFormat("<a href=""#{0}"">{1}</a> ", kvp.Value.BackLinks(i), _
Chr(97 + i))
Next
RefStr.Append("</sup> ")
End If
RefStr.AppendFormat("<a id=""reference_{1}""></a>{0}", kvp.Value.InnerXml, _
References.Keys(x).Replace(" ", "_"))
RefStr.AppendLine("</li>")
x += 1
Next
RefStr.AppendLine("</ul>")
Finally, we replace the <references /> tag with the reference list.
i = PageContent.IndexOf("<references", StringComparison.CurrentCultureIgnoreCase)
If i > -1 Then
FrontStr = PageContent.Substring(0, i)
Token = New StringBuilder
Token.Append(PageContent.Substring(i, 11))
i += 10
Do While Not Token.ToString.EndsWith(">")
i += 1
Token.Append(PageContent(i))
Loop
If Not Token.ToString.EndsWith("/>") Then
Do While Not StringContains(Token.ToString, "</ref>")
i += 1
Token.Append(PageContent(i))
Loop
End If
i += 1
PageContent = FrontStr + RefStr.ToString + PageContent.Substring(i)
End If
The last step is to write PageContent back out, and we're done.
A Matter of Style
The <sup> tag is a pain. In its default styling, the tag adds padding to the line height, causing lines to appear uneven, with some having more space between them than others. To even things out, I had to add to make a few changes.
The most important change was to <sup>. I styled the tag to have a relative position 0.5em above the baseline top. The tag is typically rendered as small (which seems to be 0.8em); I left that alone.
sup {
vertical-align:top;
position:relative;
top:-0.5em;
}
To prevent the superscripts from overlapping the line above, I had to increase the line height.
p {
line-height:1.5em;
}
The other bit of styling I used was for the reference list. I removed the list style type and all of the padding and margins on the list itself, and padded the list items to make them easier to navigate.
ul.References {
list-style-type:none;
margin:0;
padding:0;
}
ul.References li {
padding-bottom:0.5em;
}
Moving On
If you are knowledgeable with Wikipedia references, there are a number of ways this filter can be expanded. One would be to add a group attribute to <ref> and <references />, which would let you get several different reference lists, such as footnotes and a bibliography. You could also implement Wikipedia-style {{cite}} templates, which would mean your coders would not have to worry about how things are to be styled, or the differences between citing a newspaper article and a book. If you do anything interesting in this regard, I would like to hear about it; or better yet, write an article so others can learn from your work. And as always, if you found this article useful, please vote it up.
History
- Version 1 2011-03-22 Initial release
- Version 2 2011-03-29 Rewrote the filter to handle the situation where the page content does not come in all at once
Gregory Gadow recently graduated from Central Washington University with a B.S. that combined economics and statistical analysis, and currently works for the Washington Department of Fish & Wildlife as an IT developer. He has been writing code for 30 years in more than a dozen programming languages, including Visual Basic, VB.Net, C++, C#, ASP, HTML, XML, SQL, and R.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 -- and say that the likelihood of chunking is very slight. A
-- and say that the likelihood of chunking is very slight. A ![Rose | [Rose]](https://codeproject.global.ssl.fastly.net/script/Forums/Images/rose.gif)