Introduction
Artificial intelligence and neural networks are bringing image processing to a whole new level. Processes that used to take days or weeks can now be performed in a matter of hours. But some ambitious people, including Apriorit developers, are going even further and looking for ways to use neural networks that were originally created for image processing to solve video processing and video classification tasks.
In this article, we talk about using Inception V3 for image classification, adding new data classes to the pretrained neural network, retraining it, and then using the modified model for classifying video streams.
Contents
Using Inception V3 for Image and Video Classification
A convolutional neural network (CNN) is an artificial neural network architecture targeted at pattern recognition. CNNs gained wide attention within the development community back in 2012, when a CNN helped Alex Krizhevsky, the creator of AlexNet, win the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by reaching a top-5 error rate of 15.3 percent.
A few years later, Google built its own CNN called GoogleNet, otherwise known as Inception V1, which became the winner of the 2014 ILSVRC with a top-5 error rate of 6.67 percent. The model was then improved and modified several times. As of today, there are four versions of the Inception neural network. In this article, we focus on the use of Inception V3, a CNN model for image recognition pretrained on the ImageNet dataset.
Inception V3 is widely used for image classification with a pretrained deep neural network. In this article, we discuss the use of this CNN for solving video classification tasks, using a recording of an association football broadcast as an example.
To make this task a bit easier, we first need to learn how to add new recognition classes to the Inception V3 network and train it specifically for these classes.
Adding New Data Classes to a Pretrained Inception V3 Model
Transfer learning from Inception V3 allows retraining the existing neural network in order to use it for solving custom image classification tasks. To add new classes of data to the pretrained Inception V3 model, we can use the tensorflow-image-classifier repository. This repository contains a set of scripts to download the default version of the Inception V3 model and retrain it for classifying a new set of images using Python 3, Tensorflow, and Keras.
Since adding new data classes to the current neural network doesn’t take much time, you can run all of the development processes either in Google CoLab or on your own machine. If you choose the latter, it’s preferable to start with configuring the python-virtualenv tool.
Let’s move to the process of retraining Inception V3 for classifying new data. In our example below, we train our model to recognize the face of football player Lionel Messi in multiple images. In order to retrain the neural network, we need a dataset with classified images. In our case, we use this dataset containing 1,500 images with faces of three popular football players: Lionel Messi, Andrés Iniesta, and Neymar.
First, we need to create a training_dataset folder with all of the images separated into three subfolders according to the names of the athletes: Messi, Iniesta, and Neymar. As a result, we have the following file structure in a cloned tensorflow-image-classifier repository:
/
--- /training_dataset
| |
| --- /Messi
| | fcbleomessi2.jpg
| | fcbleomessi5.jpg
| | …
| |
| --- /Iniesta
| andresiniesta62.jpg
| andresiniesta63.jpg
| …
| |
| --- /Neymar
| fcbneymar3.jpg
| fcbneymar5.jpg
| …
Then we exclude two images (as test data) from each subfolder containing the athletes’ photos and move them to the tensorflow-image-classifier folder so they won’t be used for training. Now everything is set up for the retraining of our Inception V3 model.
Now we go to the tensorflow-image-classifier folder and launch the ./train.sh script. To help you better understand how it works, here’s a detailed scheme of the Inception model:
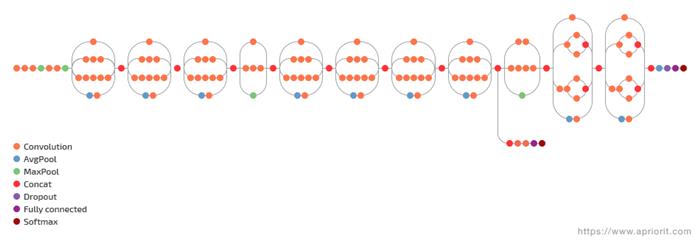
Figure 1. The architecture of the Inception neural network
The ./train.sh script loads the already trained Inception V3 model, deletes the upper layer, and then trains a new layer on the data classes that we added with images of the football players’ faces. The whole process of retraining the model consists of two stages:
- At the first stage, the script analyzes all of the images on the disk and calculates the bottleneck values for each of them. “Bottleneck” is an unofficial term used for the layer that comes right before the final output layer which, in fact, performs the classification. As a result of this stage, we get a compact form of image description that helps the classification run much faster. In the context of the Inception model, we talk about the weights for a specific layer.
- At the second stage, we move to the actual training of the upper layer of the network. Here, you can see a series of training steps, each of which shows the level of training accuracy and cross entropy. Training accuracy shows the percentage of training images that were classified correctly. Cross entropy is a loss function that demonstrates the success of the training process. Cross entropy also serves as a marker of an undertrained or overtrained model.
The result of running the ./train.sh script looks something like this:
...
2019-02-26 19:39:54.605909: Step 490: Train accuracy = 86.0%
2019-02-26 19:39:54.605959: Step 490: Cross entropy = 0.474662
2019-02-26 19:39:54.660586: Step 490: Validation accuracy = 80.0% (N=100)
2019-02-26 19:39:55.161398: Step 499: Train accuracy = 90.0%
2019-02-26 19:39:55.161448: Step 499: Cross entropy = 0.480936
2019-02-26 19:39:55.217443: Step 499: Validation accuracy = 79.0% (N=100)
Final test accuracy = 78.1% (N=151)
The final test accuracy of our classification model is 78.1 percent. This result is good considering the number of images in the dataset. The level of training accuracy can be increased if we increase the number of images used for training the model.
Now we need to check this model on the images we excluded from the training dataset earlier. In order to do this, we use a script from the classify.py repository.

python classify.py fcbneymar64.jpg
neymar (score = 0.68375)
iniesta (score = 0.17061)
messi (score = 0.14564)
python classify.py fcbleomessi30.jpg
messi (score = 0.63149)
iniesta (score = 0.30507)
neymar (score = 0.06344)
As we can see, our retrained CNN can accurately recognize the faces of our athletes. Now it’s time to shift our focus to using Inception V3 for classifying video streams.
Classifying Video Streams With Inception V3
After learning how to classify separate images, it’s time to classify a video stream. As you know, a video stream is basically a set of images in a specific format, compressed with a video codec. So the process of recognizing objects in a video stream comes down to breaking the stream into separate images and applying an object recognition algorithm to them. In our case, we’ll perform image recognition using Inception V3.
For instance, we can try to separate a commercial from the video stream of a football game.
ffmpeg -i input.mp4 -vcodec copy -acodec copy -ss 00:03:00 -t 00:01:20 mixed.mp4
First, we need to create a training dataset. We’ll use the FFmpeg utility for Linux to cut the video into pieces.
- input.mp4 is the original video recording with the football game.
ss 00:03:00 is the time of the beginning of our mini video.t 00:01:20 is the time interval that we’ll extract starting from the beginning of our mini video.- mixed.mp4 is the name of the video we’ll get in the end.
With the help of this utility, we extract three short video clips. The first video clip was cut from the beginning of the game and contains an advertisement. The second clip is a five-minute recording of the game only. And, finally, the third video includes the final minutes of the first period and the beginning of the commercials.
What we need to do next is break down the first two videos into a series of images for further retraining of our Inception V3 model. We can also use the FFmpeg utility to cut the video frame by frame:
ffmpeg -i Football.mp4 -filter:v fps=5/1 football_%0d.jpeg
- First, we create the following file structure in the repository:
Now we’re ready to retrain Inception V3 from the tensorflow-image-classifier repository. In this case, we need to add two new classes of images, football and commercial, to the default model. The mechanism for retraining the network is the same as for the athletes’ faces in our previous example. Football.mp4 is the five-minute video clip of the game. fps=5/1 is the frame rate (in our case, we’ll extract five images from every second of the video).- football_%0d.jpeg is the name of the images we’ll get in the end, where
%0d will be replaced with the number of the frame.
/
--- /training_dataset
| |
| --- /football
| | football_1.jpeg
| | football_2.jpeg
| | …
| |
| --- /commercial
| commercial_1.jpeg
| commercial_2.jpeg
| …
We place the frames from the game and the commercials shown before the match (our mini clip #1) into the football and commercial folders, respectively.
Then we launch the ./train.sh script to retrain the network with the new two classes and get the following result:
./train.sh
...
2019-02-27 20:04:06.615386: Step 499: Train accuracy = 99.0%
2019-02-27 20:04:06.615436: Step 499: Cross entropy = 0.042714
2019-02-27 20:04:06.686268: Step 499: Validation accuracy = 99.0% (N=100)
Final test accuracy = 98.0% (N=293)
As you can see, we got a great final test accuracy: 98 percent. Such a high accuracy level is quite predictable, as we used a dataset with more images than in the previous example and had only two classes for image recognition. However, these numbers don’t reflect the whole picture.
Now let’s try to apply the trained model to recognize a commercial in a video stream. In order to do this, we modified the classify.py script from the tensorflow-image-classifier so that our new script, classify_video.py, is capable of:
- processing the video file
- extracting frames from the video
- classifying the extracted images
- displaying the results directly on the frames.
The result is saved to the recognized.avi video at 10 frames per second. We save it as a slow-motion video on purpose, to make it easier to follow the change of the classification results.
Here’s the full code for the modified classify_video.py script:
import tensorflow as tf
import sys
import os
import cv2
import math
# Disable tensorflow compilation warnings
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
label_lines = [line.rstrip() for line
in tf.gfile.GFile("tf_files/retrained_labels.txt")]
with tf.gfile.FastGFile("tf_files/retrained_graph.pb", 'rb') as f:
graph_def = tf.GraphDef() ## The graph-graph_def is a saved copy of a TensorFlow graph;
graph_def.ParseFromString(f.read()) #Parse serialized protocol buffer data into variable
_ = tf.import_graph_def(graph_def, name='')
# import a serialized TensorFlow GraphDef protocol buffer,
extract objects in the GraphDef as tf.Tensor
video_path = sys.argv[1]
writer = None
# classify.py for video processing.
# This is the interesting part where we actually changed the code:
#############################################################
with tf.Session() as sess:
video_capture = cv2.VideoCapture(video_path)
i = 0
while True: # fps._numFrames < 120
frame = video_capture.read()[1] # get current frame
frameId = video_capture.get(1) #current frame number
i = i + 1
cv2.imwrite(filename="screens/"+str(i)+"alpha.png", img=frame); # write frame image to file
image_data = tf.gfile.FastGFile
("screens/"+str(i)+"alpha.png", 'rb').read() # get this image file
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
predictions = sess.run(softmax_tensor, \
{'DecodeJpeg/contents:0': image_data}) # analyse the image
top_k = predictions[0].argsort()[-len(predictions[0]):][::-1]
pos = 1
for node_id in top_k:
human_string = label_lines[node_id]
score = predictions[0][node_id]
cv2.putText(frame, '%s (score = %.5f)' % (human_string, score),
(40, 40 * pos), cv2.FONT_HERSHEY_DUPLEX, 0.8, (255, 255, 255))
print('%s (score = %.5f)' % (human_string, score))
pos = pos + 1
print ("\n\n")
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"XVID")
writer = cv2.VideoWriter("recognized.avi", fourcc, 10,
(frame.shape[1], frame.shape[0]), True)
# write the output frame to disk
writer.write(frame)
cv2.imshow("image", frame) # show frame in window
cv2.waitKey(1) # wait 1ms -> 0 until key input
writer.release()
video_capture.release()
cv2.destroyAllWindows()
For this script to successfully execute, we need to add the screens folder to the directory with the script. This folder will contain all of the recognized frames.
Now let’s launch our script:
python classify_video.py mixed.mp4
Pay attention to the classification results in the frames from 2:24 to 2:27 in the video. Every time there’s a football field on the screen, the network classifies the frame as a football game.
In the end, we’ll get a video file with the classification results displayed in the upper left corner.
You might also notice strange changes in the results from 2:15 to 2:18, when someone’s face is shown up-close. This is the result of training the model on the game screens with close-ups of coaches or people on the stands. Unfortunately, this problem with recognition of a separate image can’t be solved with Inception V3, as to solve it you need to somehow remember the whole video sequence. But we hope to find a solution soon and will surely share it when we do.
Our experts are actively exploring the latest developments in the field of artificial intelligence and are constantly sharing their experiences here.
Conclusion
The possibilities of deep learning algorithms and modern CNNs aren’t limited to classifying separate images. CNNs can be effectively applied to recognizing patterns in video streams as well. In this article, we showed you an easy way to use the pretrained Inception V3 neural network for video classification.
In our example, we successfully retrained the existing Inception V3 model, added new classes of data to it, and used the modified network to classify video clips. However, we also faced a new challenge in the process: recognizing a video sequence, as Inception V3 only works with separate images.
ApriorIT is a software research and development company specializing in cybersecurity and data management technology engineering. We work for a broad range of clients from Fortune 500 technology leaders to small innovative startups building unique solutions.
As Apriorit offers integrated research&development services for the software projects in such areas as endpoint security, network security, data security, embedded Systems, and virtualization, we have strong kernel and driver development skills, huge system programming expertise, and are reals fans of research projects.
Our specialty is reverse engineering, we apply it for security testing and security-related projects.
A separate department of Apriorit works on large-scale business SaaS solutions, handling tasks from business analysis, data architecture design, and web development to performance optimization and DevOps.
Official site: https://www.apriorit.com
Clutch profile: https://clutch.co/profile/apriorit
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





