The article will help you understand database transactions (principles, concepts, etc.) and how to use Spring Framework to implement transactional behavior in your application.
Preface
The author tries to share knowledge about database transactions and applying Spring Framework to deal with them. The knowledge comes from Craig Walls's book[1], Spring Framework documentation[2] and from searching for answers on Stack Overflow and Wikipedia. The article covers the most important things related to the topic, so that you could gain proper understanding of transactions and start working with them in your projects.
Introduction
Transactions follow the "all or nothing" principle. They consist of several steps. If all steps are successful, then the transaction is successful. If at least one of the steps was not executed successfully, then all previous steps must be rolled back as if nothing happened.
One of the simple cases where transactions could be applied is money transfer in a bank. Imagine a situation where money was successfully withdrawn from one account, but was not added to the second account. Or the opposite scenario, where money was successfully added to the second account, but withdrawal failed. Both situations are not acceptable. So, the act of money transferring must be transactional — it should either be successful completely, or rolled back if at least one of the steps fails.
In this article, we will cover the principles and concepts related to transactions. Particularly, we will focus on database transactions, i.e., the cases when we need to execute several queries in scope of a transaction. We will find out how to implement such transactional behavior in our Java applications with the help of Spring Framework (and will be amazed to see how simple it is).
Main Principles
Transactions are described as ACID, which stands for:
- Atomic — the mentioned "all or nothing" principle
- Consistent — once transaction ends (successfully or not), the system is left consistent with business it supports, i.e., no corrupted data are left
- Isolated from each other, preventing concurrent reads / writes to the same data
- Durable — once the transaction is completed, its results should be persisted
We can say that Atomic, Isolated and Durable properties support the Consistent property. Consistency is the main aspect of the system the transactions care about.
Transactions can be impacted by other transactions that are being executed concurrently. Concurrent transactions may lead to the following problems:
- Dirty reads occur when one transaction reads data that was modified but not yet committed by the second transaction. If the changes made by the second transaction are later rolled back, the data obtained by the first transaction become invalid.
- Non-repeatable reads occur when a transaction makes the same read query multiple times, and each time data in the same row is different, because another transaction updated the row between reading queries. The first transaction, however, expects that the data is the same.
- Phantom reads — when transaction executes the same reading query, and the second time the query result contains more rows then the first time, because another transaction inserted a row that satisfies
WHERE statement of the read queries.
Note: Non-repeatable reads and phantom reads may seem to be very similar. The important difference is that in case of non-repeatable read, the same row which was read before contains different data. In case of phantom reads, new rows are added by another transaction.
Applying Spring Framework
Now, when we know the main principles, concepts and problems related to transactions, we are ready to work with them. Let's see how to apply Spring Framework to introduce transactional behavior to our application which works with a database.
Choosing a Transaction Manager
We will need to use a transaction manager to interface with a platform-specific transaction implementation. In this context, platform is a persistence framework, e.g., JDBC, MyBatis, Hibernate, Java Transaction API (JTA). So, we need to choose a corresponding transaction manager that is provided by Spring.
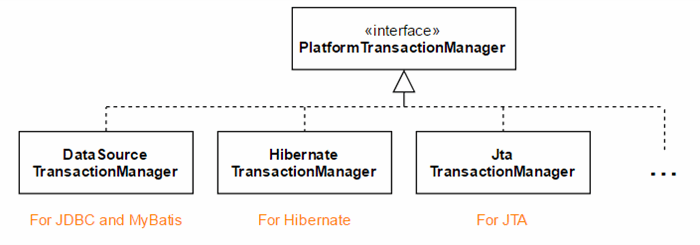
Let's imagine that our application interacts with the database through JdbcTemplate[3]. So we need to add DataSourceTransactionManager to the application context.
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.ibm.db2.jcc.DB2Driver"/>
<property name="url" value="jdbc:db2://${url}:${port}/${databaseName}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</bean>
We will not cover data source configuration in detail in this article, however you can find information about it in Spring Documentation[3].
Behind the scenes, DataSourceTransactionManager will work with java.sql.Connection object retrieved from DataSource, calling commit() on success, and rollback() on failure. For other persistence frameworks, the behavior is a different, but commit and rollback operations make up the core functionality.
Transaction Attributes
Before declaring transactions in our code, we need to get familiar with transaction attributes. The attributes allow to specify transaction behavior, so that it fits the needs. Spring Framework supports the following attributes, and each has a default value.
Propagation behavior defines how a method should be executed with respect to transactions. It specifies whether a new transaction needs to be created; or whether existing one (more global transaction) must be used; or whether transactions should be suspended for the duration of the method; and so on. Transactions have scope, and a transaction may be executed in scope of a "bigger" ("more global") transaction. We are able to specify how the transactions relate one to another. For example, in case of a transaction rolling back, should a more global transaction also roll back, or should it continue the execution? We have the power to choose.
The default value for this attribute in Spring Framework is REQUIRED, which means that method will run in scope of an existing (more global) transaction or new transaction will be started. If our transaction rolls back, the more global one will also rollback. In simple cases, when working with database, there will be no need to have several "layers" of transactions, so the default value will completely satisfy us. If not, please refer to Spring documentation[2] to gain deeper understanding propagation.
Isolation levels specify how transaction can be impacted by other concurrent transactions. We could say that isolation level defines how selfish the transaction is to data that it works with. Isolation is needed to solve the problems of concurrent transactions (mentioned before in the article). Spring Framework supports several levels of isolation which gradually solve the problems. The following figure shows which problems still occur in which isolation level.

The author hopes that the figure makes at least some sense. From it, we can see that SERIALIZABLE level solves all problems, whereas REPEATABLE_READ allows phantom reads to occur, and READ_UNCOMMITTED doesn't solve any of the known problems.
The question arises: why not always use SERIALIZABLE — the strictest isolation level — if it solves all the problems of concurrent transactions? In databases, isolation is realized by locking the rows[4] — transactions need to wait until a transaction that had obtained the lock releases it. Recall that we can view isolation level as a level of selfishness of a transaction regarding data. The more selfish transactions are, the longer on average transactions will need to wait for each other, so the performance of our database system will decrease. Hence, you should pick as low isolation level as possible, but do not (!) sacrifice consistency for performance. Consider what your transaction does to data and how it can be affected by external data modifications, and then choose the most relaxed isolation level that guarantees correctness.
Another problem caused by isolation (more precisely, by usage of locks) is the possibility of deadlocks[5]. Very briefly, an example of a deadlock is when the first transaction waits until the second transaction releases the lock on data, and at the same time, the second transaction waits until the first transaction releases the lock on another data object. In this case, transactions block each other and can't continue — deadlock has occurred. Deadlock is a large topic which we will not cover in this article. Please keep in mind that the problem of deadlocks exists in the domain of transactions, and eventually must be addressed. But for now, let's not focus on it.
The default value for this isolation attribute is DEFAULT, which uses the default setting of the underlying data store. Most probably, you will want to specify non-default value to make your transaction optimal from performance and consistency points of view, as well as to make your application independent of a certain database.
Note: Not all databases support the mentioned isolation levels — consult documentation of the database you are using. Even though the database might not support a certain isolation level, most probably, you want your application to be independent of a given data source implementation. Hence, you should choose isolation level as if the database supports all isolation levels we talked about.
Read-only attribute, as one could expect, specifies whether the transaction performs only read operations without modifying any data. It allows database to apply optimizations that take advantage of read-only nature of the transaction. Default value is false.
Transaction timeout specifies after how much time the transaction shall rollback. As we found out earlier, transactions may acquire locks from columns, thus blocking other transactions, and in some cases, it is unacceptable to occupy data for too long. Default value is default timeout of the underlying persistence framework (recall choosing transaction manager earlier), or none if timeouts are not supported.
Rollback rules. Transaction rolls back when an exception is thrown in its scope. With rollback rules, we can define which exceptions should prompt rollback. By default, transactions roll back on unchecked exceptions, i.e., RuntimeException and its subclasses, and do not rollback on checked exceptions.
Declaring Transactions
Spring provides different ways of working with transactions.
- Annotating classes and method as
@Transactional — very simple but powerful approach to make the method execute in scope of transaction. - Programmatic transactions which give you more fine-grained control. Use
TransactionTemplate[2] if you need more control, but be aware that the code will become more complex. - Declaring transactions in XML is very similar to using annotations. By following this approach, all information about transactions is gathered in XML documents instead of source code.
The author chose to cover annotation approach, since it is powerful enough for most cases, it is elegant (subjectively), and in the author's opinion, it is better to declare transactional behavior in the source code so that every developer can clearly see that transactions are applied. However, feel free to use any approach you see fit.
To use annotations, you need to add only one line of code to your configuration:
<tx:annotation-driven transaction-manager="transactionManager" />
Recall that we have declared transaction manager earlier. That's it. Now we can annotate repository class and / or methods as transactional. Note, that you should annotate the repository implementation instead of repository interface. It is because Java annotations are not inherited from interfaces, and placing @Transactional on interface will work only if interface-based proxies are used, and you, most probably, don't want to make your application dependent on that.
Use case. We have a repository that persists Documents. Documents may have several Attachments. To concentrate on transactions, let's assume the DocumentMapper handles mapping of Java object onto SQL query and executes it against underlying database — all we need is to call its methods (DocumentMapper is supported by MyBatis, but it is not relevant right now). So, let's go ahead and annotate our class and methods to apply transactional behavior.
@Repository
@Transactional(isolation = SERIALIZABLE)
public class DocumentRepositoryImpl implements DocumentRepository {
private final DocumentMapper documentMapper;
@Autowired
public DocumentRepositoryImpl(DocumentMapper documentMapper) {
this.documentMapper = documentMapper;
}
@Transactional(isolation = READ_UNCOMMITTED)
public void save(Document document) {
documentMapper.saveDocument(document);
for (Attachment attachment : document.getAttachments()) {
documentMapper.saveAttachment(document, attachment);
}
}
@Transactional(isolation = READ_COMMITTED, readOnly = true)
public Document readDocument(long id) {
return documentMapper.readDocument(id);
}
...
}
Taking the Code Apart
Annotating class as @Transactional is equivalent to putting this annotation to every public method in the class. However, the method-level @Transactional annotation takes precedence over class-level annotation. So, by putting @Transactional(isolation = SERIALIZABLE), we declared that by default every public method of our repository should be executed in scope of transaction with the strictest isolation level, but we are allowed to reconfigure the transactional behavior for each method individually.
The save(Document) method will serve as main example to demonstrate the power of transactions. Inside the method, document and its attachments are saved. With each call to documentWrapper, an SQL query is sent to database and executed. So, for example, if a document has three attachments, it will take four queries to save this document: one for document itself, and three for its attachments. The important thing to notice is that between the queries to database, execution flow returns to our Java application. In the application, many things can go wrong, and we don't want to leave our persisted data in inconsistent state (e.g., document with only part of submitted attachments). So, by annotating save(Document) as @Transactional we make the SQL queries, that are encapsulated in documentWrapper, to be executed in scope of transaction. The transaction will commit only when the execution flow returns from save(Document) method. The transaction will rollback if any unchecked exception (RuntimeException and its sub-classes) is thrown from the method. Thus, the persisted data about documents will stay consistent — we are sure that if the document was saved, all its attachments were saved as well.
Let's have a look at transaction attributes of save(Document) method. We explicitly specified that isolation level is READ_UNCOMMITTED, which is the weakest isolation level that allows phantom reads, non-repeatable reads and dirty reads. This choice was made on a basis that our transaction doesn't read any data during the execution, it only writes. Therefore, there is no need to make isolation any stricter. All other attributes are implicitly left as defaults: we are happy with default propagation behavior which will create a new transaction or will use a more global one; false value for read-only attribute is obviously the proper one since the transaction modifies data; since the method does not throw any checked exceptions, rolling back on unchecked exceptions is what we need, so rollback rules stay default; and lastly, there is no need to modify default transaction timeout (at least for now), so we keep it as default.
One big benefit of transactions managed by Spring Framework is that it is possible to unit-test them. Please have a look at the following code:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:test-config.xml")
public class DocumentRepositoryImplTest {
@Autowired
private DocumentRepository testedObject;
@Test
transactionalSaveDocument_withCorruptedAttachment_rollsBack() throws Exception {
Document document = createDocumentWithAttachments();
Document documentWithCorruptedAttachment = addCorruptedAttachmentTo(document);
trySaving(documentWithCorruptedAttachment);
assertNoDataIsLeftInDatabase();
}
private static Document createDocumentWithAttachments() {
}
private static Document addCorruptedAttachmentTo(Document document) {
List<Attachment> attachments = document.getAttachments();
attachments.add(new CorruptedAttachment());
return document;
}
private void trySaving(Document documentWithCorruptedAttachment) {
try {
testedObject.save(documentWithCorruptedAttachment);
Assert.fail("Document with corrupted attachment should not have passed.");
} catch (RuntimeException e) {
}
}
private void assertNoDataIsLeftInDatabase() {
}
private static class CorruptedAttachment extends Attachment {
@Override
public String getType() {
throw new RuntimeException();
}
}
}
The key points of the test is that we have added an attachment that throws RuntimeException on getType() call. Underneath the hood, DocumentMapper uses accessor methods to form SQL query, so RuntimeException will be thrown out as soon as the tested repository will try to save the corrupted attachment in this line: documentMapper.saveAttachment(document, attachment); We catch the exception in our test. Since the exception has been thrown out of save(Document) method, we expect that transaction has rolled back. We can verify it by checking whether no data about document and attachments are left in database — assertNoDataIsLeftInDatabase() call.
We can go even further, and try to debug the test. By putting a breakpoint at the line documentMapper.saveAttachment(document, attachment), we can assure that SQL queries are executed one by one. Particularly, it is possible to see that Document and Attachment objects acquire IDs from database (the output from database mapping onto Java objects is handled by DocumentMapper). Since ID of document is known, while execution waits at breakpoint, it is possible to try to get data about document with SELECT statement by using database client. The author tried to do so with IBM DB2 database, and the query was not able to execute because it was blocked. It is expected, because the row we are interested in is locked by transaction until it commits.
That's it about save(Document) method. Let's have a quick look at readDocument(long). Reading the document with its attachments requires a single SELECT query, so phantom reads and non-repeatable reads are not possible. However, we want to be safe from dirty reads. That's why isolation level is READ_COMMITTED. To enable database optimizations for read-only transactions, we go forward and declare readOnly = true.
So, we have seen how to apply and test transactional behavior. Let's summarize what we have learned.
Summary
Database transactions are applied when data processing requires several steps which must be reverted if at least one of them fails so that data consistency is not violated. Transactions can be described as Atomic, Isolated, Durable and Consistent (ACID).
In database, transactions are executed concurrently. The concurrency of transactions leads to problems such as dirty reads, non-repeatable reads and phantom reads. Isolation levels address these problems. The stricter isolation level is applied, the more the throughput of the database is impacted. One must analyze how the problems with the reads can affect the transaction under consideration and choose the lowest isolation level possible which guarantees that transaction will not be affected.
It is truly impressive how simple it is to deal with transactions by applying Spring Framework. All you need to do is the following:
- Depending on the persistence framework you are using (JDBC, MyBatis, Hibernate...), choose the proper transaction manager and declare it as a bean in your application context.
- Enable
@Transactional annotation processing by adding one line to the configuration: <tx:annotation-driven transaction-manager="transactionManager" />. - Annotate your repository class and / or methods as
@Transactional. - Specify the transaction attributes. As we have seen, Spring supports different propagation behavior, isolation levels, declaring transaction as read-only, specifying timeout and rollback rules.
Note that @Transactional annotation is only one of the ways of dealing with transactions in Spring Framework.
Now you have strong base knowledge about database transactions and their application, and how to deal with them particularly with Spring Framework. Thank you for reading the article!
History
- 11th June 2017: Submitted article
Bibliography
- Craig Walls. Spring in Action. 3rd edition. Manning, June 2011. 424 p. ISBN 9781935182351. Chapter 6: Managing Transactions.
- The Spring Framework. Spring Framework Reference, Part V. Data Access, Chapter 17: Transaction Management. [online, viewed 4 June 2017]. Available from: http://docs.spring.io/spring/docs/current/spring-framework-reference/html/transaction.html
- The Spring Framework. Spring Framework Reference, Part V. Data Access, Chapter 19: Data access with JDBC. [online, viewed 4 June 2017]. Available from: http://docs.spring.io/spring-framework/docs/current/spring-framework-reference/html/jdbc.html
- Wikipedia. Isolation (database systems). [online, viewed 6 June 2017]. Available from: https://en.wikipedia.org/wiki/Isolation_(database_systems)
- Wikipedia. Deadlock. [online, viewed 6 June 2017]. Available from: https://en.wikipedia.org/wiki/Index_locking
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





