Abstract
This article describes the development of Example Based Machine Translation (EBMT) system using Java on Linux platform for translation from one language to another. In this particular case, I will be translating English sentences to Hindi. The principle of translating in EBMT is simple: a system decides an appropriate translation of an input sentence by analyzing the pre-translated sentences in the database. Therefore, the larger the database of pre-translated sentences, greater will be the accuracy of the EBMT system.
This article is greatly inspired by the works of Ralf Brown and Balakrishnan who have done extensive research in this field.
Introduction and Background
Example based translation is essentially translation by analogy. This means that if an EBMT system is given a set of sentences in the source language (from which one is translating) and their corresponding translations in the target language, the system can use these examples to translate other such similar source language sentences into target language sentences. The basic premise is that, if a previously translated sentence occurs again, the same translation is likely to be correct again.
Software Used
Developing your own machine translation is a difficult task. However, there are some tools that can help accelerate the process. I used the following tools in my EBMT system:
- Moses Decoder
- Giza++
- IRST-LM
Block Diagram
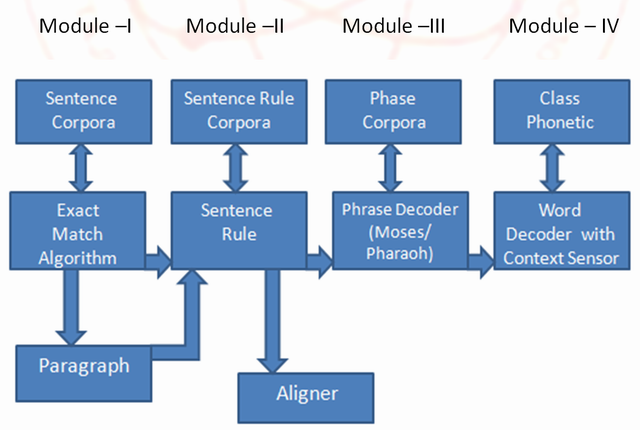
Description
I divided the entire EBMT system into four modules.
1. Module I: Exact Match Algorithm
In this module, the input English sentence is first checked with every sentence in the available bilingual corpora for an exact match. If found, the corresponding Hindi sentence is retrieved and displayed as output.
In the case when the input is a paragraph, then the input is first broken down into sentences, and each sentence is taken one by one and translated.
2. Module II: Sentence Rule Based Translation
Every language has some grammar that describes how the words in the sentences should be organized. For instance, consider English vs. Hindi. English follows Subject-Verb-Object (SVO) linguistic topology while Hindi follows Subject-Object-Verb (SOV) topology. To illustrate this example, compare the following two sentences:
English: Anshul plays football
Hindi: Anshul football khelta hai
This module converts the input language into tokenized format. For example, the above English sentence is converted to
<Subject> plays <Object>
This helps in generalizing the translation process.
Besides this, there are many other linguistic rules that must be taken into consideration while translating sentences.
3. Module III: Phrase Decoder
When the first modules fail to translate, we divide the sentences into phrases against which we run algorithms based on statistical machine translation to find the most probable translated output of the input sentence.
Mathematically, we try to find out:
H*= arg max<sub>H</sub>P(H/E) -(1)
I know this sounds complicated, so let me explain how we came to this equation.
According to the famous Bayes Law (Probability),
P(A/B) = P(B/A) * P(A)/P(B)
In this case, we need to find that translated sentence A which has max probability of being the correct translation for a given input sentence B. Since we are looking for the most likely outcome A* for an event, given a fixed event B, P(B) is constant and doesn't play a role.
Thus, we want:
=> A* = arg max<sub>A</sub> P(A/B)
=> A*=arg max<sub>A</sub> P(B/A)*P(A)/P(B)
=> A*= arg max<sub>A</sub> P(B/A)*P(A) -same as (1)
This module tries to find the most probable Hindi translation of an English sentence by trying to find phrase H that would maximize P(E/H)*P(H). Phrases like these are clubbed together to complete the sentence.
Note:
- P(H)=[Language model probability]:
I used IRST-Language Model that measures fluency and probability of Hindi sentence and provide a set of fluent sentences to test for potential translation.
- P(E/H)=[translation model probability H->E]:
I used Giza++ that measures faithfulness, Probability of an (English, Hindi) pair given a Hindi sentence and test if a given fluent sentence is a translation.
- arg maxH
I used Moses Decoder that uses heuristic search to effectively and efficiently find H*.
4. Module IV: Word Decoder
This is the last attempt by EBMT to translate the input sentence. When Module III also fails to translate, EBMT breaks the sentence into words. For every word, it tries to seek the dictionary translation and simply stitches the outputs into a translated sentence.
Setup of EBMT
Basic preparation of an EBMT system requires you to do the following:
- Develop a bilingual corpora having pretranslated sentences from source language to destination language.
- Once you have a decent size corpora, then you need to install Giza++, Moses and IRST on your system.
- IRST requires monolingual file as well. This can easily be created by separating the bilingual corpora.
- Finally, you need to train your corpora with giza++. At the backhand, shell scripts and Perl scripts are run that compute probabilities and generate various files such as alignment file, translation table, fertility file, distoration table, etc.

Result
Training with Giza++ took 1.5 days. After which my EBMT system was ready!
Future Work
Machine translation is a research field with a lot of work already done and a lot more yet to be done. I merely demonstrated how you can use existing tools to create your own machine translation system. This is my first step towards innovation and I have a long way to go...
History
- 11th August, 2010: Initial post
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






